 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracing Energy Flow: Learning Tactile-based Grasping Force Control to Prevent Slippage in Dynamic Object Interaction
Dec 24, 2025



Regulating grasping force to reduce slippage during dynamic object interaction remains a fundamental challenge in robotic manipulation, especially when objects are manipulated by multiple rolling contacts, have unknown properties (such as mass or surface conditions), and when external sensing is unreliable. In contrast, humans can quickly regulate grasping force by touch, even without visual cues. Inspired by this ability, we aim to enable robotic hands to rapidly explore objects and learn tactile-driven grasping force control under motion and limited sensing. We propose a physics-informed energy abstraction that models the object as a virtual energy container. The inconsistency between the fingers' applied power and the object's retained energy provides a physically grounded signal for inferring slip-aware stability. Building on this abstraction, we employ model-based learning and planning to efficiently model energy dynamics from tactile sensing and perform real-time grasping force optimization. Experiments in both simulation and hardware demonstrate that our method can learn grasping force control from scratch within minutes, effectively reduce slippage, and extend grasp duration across diverse motion-object pairs, all without relying on external sensing or prior object knowledge.
Prolonging Tool Life: Learning Skillful Use of General-purpose Tools through Lifespan-guided Reinforcement Learning
Jul 23, 2025



In inaccessible environments with uncertain task demands, robots often rely on general-purpose tools that lack predefined usage strategies. These tools are not tailored for particular operations, making their longevity highly sensitive to how they are used. This creates a fundamental challenge: how can a robot learn a tool-use policy that both completes the task and prolongs the tool's lifespan? In this work, we address this challenge by introducing a reinforcement learning (RL) framework that incorporates tool lifespan as a factor during policy optimization. Our framework leverages Finite Element Analysis (FEA) and Miner's Rule to estimate Remaining Useful Life (RUL) based on accumulated stress, and integrates the RUL into the RL reward to guide policy learning toward lifespan-guided behavior. To handle the fact that RUL can only be estimated after task execution, we introduce an Adaptive Reward Normalization (ARN) mechanism that dynamically adjusts reward scaling based on estimated RULs, ensuring stable learning signals. We validate our method across simulated and real-world tool use tasks, including Object-Moving and Door-Opening with multiple general-purpose tools. The learned policies consistently prolong tool lifespan (up to 8.01x in simulation) and transfer effectively to real-world settings, demonstrating the practical value of learning lifespan-guided tool use strategies.
Uncertainty-aware Contact-safe Model-based Reinforcement Learning
Oct 16, 2020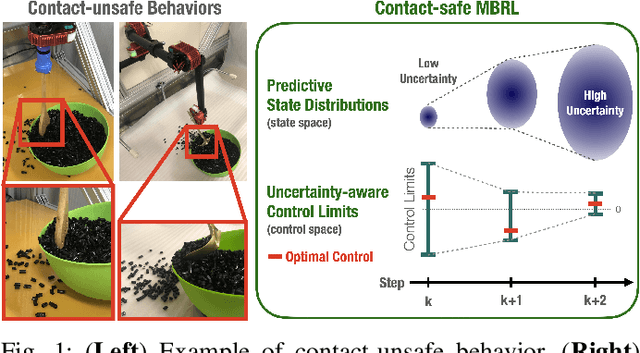
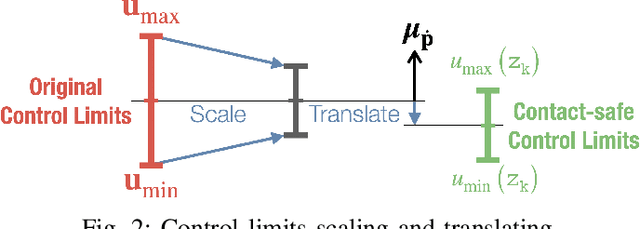
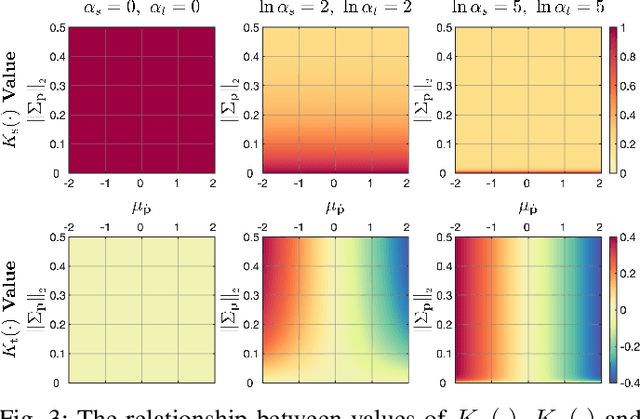
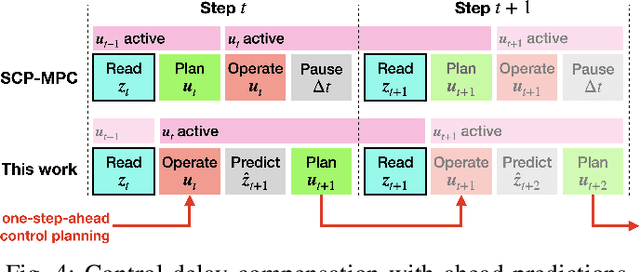
This paper presents contact-safe Model-based Reinforcement Learning (MBRL) for robot applications that achieves contact-safe behaviors in the learning process. In typical MBRL, we cannot expect the data-driven model to generate accurate and reliable policies to the intended robotic tasks during the learning process due to data scarcity. Operating these unreliable policies in a contact-rich environment could cause damage to the robot and its surroundings. To alleviate the risk of causing damage through unexpected intensive physical contacts, we present the contact-safe MBRL that associates the probabilistic Model Predictive Control's (pMPC) control limits with the model uncertainty so that the allowed acceleration of controlled behavior is adjusted according to learning progress. Control planning with such uncertainty-aware control limits is formulated as a deterministic MPC problem using a computationally-efficient approximated GP dynamics and an approximated inference technique. Our approach's effectiveness is evaluated through bowl mixing tasks with simulated and real robots, scooping tasks with a real robot as examples of contact-rich manipulation skills. (video: https://youtu.be/8uTDYYUKeFM)