 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScore $\times$ Decoder: A Unified View of Unsupervised Inference-Time Scaling for Hallucination Mitigation
May 30, 2026Large language models hallucinate even when the answer lies within their parameters. While inference-time scaling can surface this latent knowledge, the most effective methods require supervision: a trained verifier or reward model. We ask what can be done with only a base language model: which intrinsic signal best identifies correct outputs, and how should it be decoded? We cast this as a score~$\times$~decoder grid pairing four scores (perplexity, contrastive, power-distribution likelihood, and self-verification) with three decoding families (optimization, sampling, consensus), and evaluate every cell on MATH500 with the base and instruction-tuned Qwen3-1.7B. While self-verification, which prompts the model to judge its own answer and is sharpened by a training-free virtual-thinking prefix, works well in most settings, no score has a fixed quality: its value depends on the decoder that consumes it and on model capability. When no supervision is available, the score and the decoding family must be chosen together.
Mitigating Distribution Sharpening in Math RLVR via Distribution-Aligned Hint Synthesis and Backward Hint Annealing
Apr 09, 2026Reinforcement learning with verifiable rewards (RLVR) can improve low-$k$ reasoning accuracy while narrowing solution coverage on challenging math questions, and pass@1 gains do not necessarily translate into better large-$k$ performance. Existing hint-based approaches can make challenging questions trainable, but they leave two issues underexplored: teacher-student distribution mismatch and the need to reduce hint exposure to match no-hint evaluation. We address these issues through two components. Distribution-Aligned Hint Synthesis (DAHS) constructs verified teacher hints conditioned on student-style responses. Backward Hint Annealing (BHA) anneals hint exposure across difficulty buckets and uses per-question hint dropout to preserve no-hint updates throughout RL training. We evaluate the method in math RLVR under the DAPO training framework across AIME24, AIME25, and AIME26 using $\texttt{Qwen3-1.7B-Base}$ and $\texttt{Llama-3.2-1B-Instruct}$. On $\texttt{Qwen3-1.7B-Base}$, our method improves both pass@1 and pass@2048 relative to DAPO across the three AIME benchmarks. On $\texttt{Llama-3.2-1B-Instruct}$, the gains are concentrated in the large-$k$ regime. These results suggest that, in math RLVR, hint scaffolding is effective when it restores learnable updates on challenging questions early in training and is then gradually removed before no-hint evaluation.
TraceSafe: A Systematic Assessment of LLM Guardrails on Multi-Step Tool-Calling Trajectories
Apr 08, 2026As large language models (LLMs) evolve from static chatbots into autonomous agents, the primary vulnerability surface shifts from final outputs to intermediate execution traces. While safety guardrails are well-benchmarked for natural language responses, their efficacy remains largely unexplored within multi-step tool-use trajectories. To address this gap, we introduce TraceSafe-Bench, the first comprehensive benchmark specifically designed to assess mid-trajectory safety. It encompasses 12 risk categories, ranging from security threats (e.g., prompt injection, privacy leaks) to operational failures (e.g., hallucinations, interface inconsistencies), featuring over 1,000 unique execution instances. Our evaluation of 13 LLM-as-a-guard models and 7 specialized guardrails yields three critical findings: 1) Structural Bottleneck: Guardrail efficacy is driven more by structural data competence (e.g., JSON parsing) than semantic safety alignment. Performance correlates strongly with structured-to-text benchmarks ($ρ=0.79$) but shows near-zero correlation with standard jailbreak robustness. 2) Architecture over Scale: Model architecture influences risk detection performance more significantly than model size, with general-purpose LLMs consistently outperforming specialized safety guardrails in trajectory analysis. 3) Temporal Stability: Accuracy remains resilient across extended trajectories. Increased execution steps allow models to pivot from static tool definitions to dynamic execution behaviors, actually improving risk detection performance in later stages. Our findings suggest that securing agentic workflows requires jointly optimizing for structural reasoning and safety alignment to effectively mitigate mid-trajectory risks.
Eyes-on-Me: Scalable RAG Poisoning through Transferable Attention-Steering Attractors
Oct 01, 2025Existing data poisoning attacks on retrieval-augmented generation (RAG) systems scale poorly because they require costly optimization of poisoned documents for each target phrase. We introduce Eyes-on-Me, a modular attack that decomposes an adversarial document into reusable Attention Attractors and Focus Regions. Attractors are optimized to direct attention to the Focus Region. Attackers can then insert semantic baits for the retriever or malicious instructions for the generator, adapting to new targets at near zero cost. This is achieved by steering a small subset of attention heads that we empirically identify as strongly correlated with attack success. Across 18 end-to-end RAG settings (3 datasets $\times$ 2 retrievers $\times$ 3 generators), Eyes-on-Me raises average attack success rates from 21.9 to 57.8 (+35.9 points, 2.6$\times$ over prior work). A single optimized attractor transfers to unseen black box retrievers and generators without retraining. Our findings establish a scalable paradigm for RAG data poisoning and show that modular, reusable components pose a practical threat to modern AI systems. They also reveal a strong link between attention concentration and model outputs, informing interpretability research.
CmdCaliper: A Semantic-Aware Command-Line Embedding Model and Dataset for Security Research
Nov 02, 2024



This research addresses command-line embedding in cybersecurity, a field obstructed by the lack of comprehensive datasets due to privacy and regulation concerns. We propose the first dataset of similar command lines, named CyPHER, for training and unbiased evaluation. The training set is generated using a set of large language models (LLMs) comprising 28,520 similar command-line pairs. Our testing dataset consists of 2,807 similar command-line pairs sourced from authentic command-line data. In addition, we propose a command-line embedding model named CmdCaliper, enabling the computation of semantic similarity with command lines. Performance evaluations demonstrate that the smallest version of CmdCaliper (30 million parameters) suppresses state-of-the-art (SOTA) sentence embedding models with ten times more parameters across various tasks (e.g., malicious command-line detection and similar command-line retrieval). Our study explores the feasibility of data generation using LLMs in the cybersecurity domain. Furthermore, we release our proposed command-line dataset, embedding models' weights and all program codes to the public. This advancement paves the way for more effective command-line embedding for future researchers.
With Greater Distance Comes Worse Performance: On the Perspective of Layer Utilization and Model Generalization
Jan 28, 2022
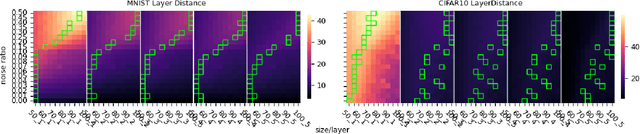
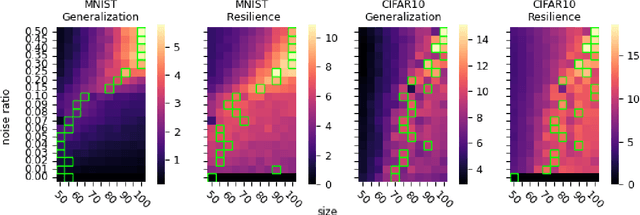
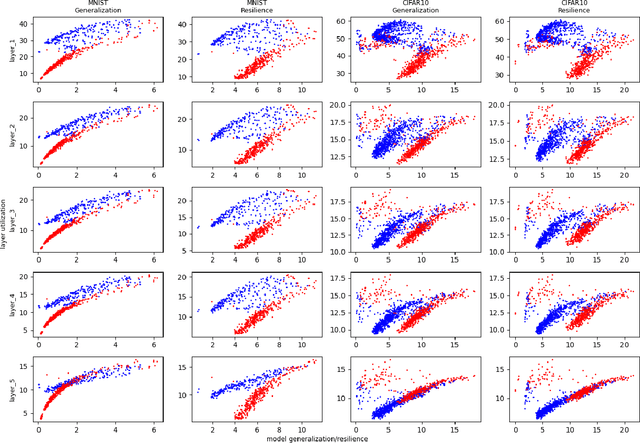
Generalization of deep neural networks remains one of the main open problems in machine learning. Previous theoretical works focused on deriving tight bounds of model complexity, while empirical works revealed that neural networks exhibit double descent with respect to both training sample counts and the neural network size. In this paper, we empirically examined how different layers of neural networks contribute differently to the model; we found that early layers generally learn representations relevant to performance on both training data and testing data. Contrarily, deeper layers only minimize training risks and fail to generalize well with testing or mislabeled data. We further illustrate the distance of trained weights to its initial value of final layers has high correlation to generalization errors and can serve as an indicator of an overfit of model. Moreover, we show evidence to support post-training regularization by re-initializing weights of final layers. Our findings provide an efficient method to estimate the generalization capability of neural networks, and the insight of those quantitative results may inspire derivation to better generalization bounds that take the internal structure of neural networks into consideration.