 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Bayesian melding for integrating individual and population models
Oct 30, 2015


In many statistical problems, a more coarse-grained model may be suitable for population-level behaviour, whereas a more detailed model is appropriate for accurate modelling of individual behaviour. This raises the question of how to integrate both types of models. Methods such as posterior regularization follow the idea of generalized moment matching, in that they allow matching expectations between two models, but sometimes both models are most conveniently expressed as latent variable models. We propose latent Bayesian melding, which is motivated by averaging the distributions over populations statistics of both the individual-level and the population-level models under a logarithmic opinion pool framework. In a case study on electricity disaggregation, which is a type of single-channel blind source separation problem, we show that latent Bayesian melding leads to significantly more accurate predictions than an approach based solely on generalized moment matching.
Scheduled denoising autoencoders
Apr 10, 2015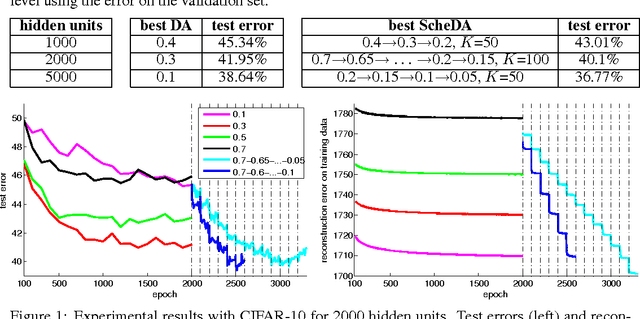



We present a representation learning method that learns features at multiple different levels of scale. Working within the unsupervised framework of denoising autoencoders, we observe that when the input is heavily corrupted during training, the network tends to learn coarse-grained features, whereas when the input is only slightly corrupted, the network tends to learn fine-grained features. This motivates the scheduled denoising autoencoder, which starts with a high level of noise that lowers as training progresses. We find that the resulting representation yields a significant boost on a later supervised task compared to the original input, or to a standard denoising autoencoder trained at a single noise level. After supervised fine-tuning our best model achieves the lowest ever reported error on the CIFAR-10 data set among permutation-invariant methods.
Semi-Separable Hamiltonian Monte Carlo for Inference in Bayesian Hierarchical Models
Jun 15, 2014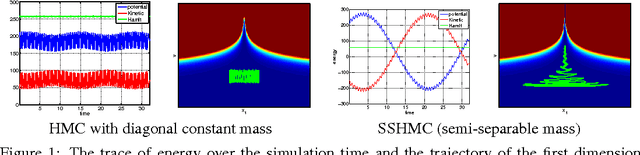


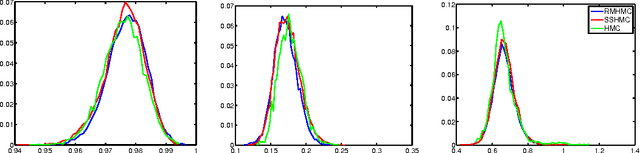
Sampling from hierarchical Bayesian models is often difficult for MCMC methods, because of the strong correlations between the model parameters and the hyperparameters. Recent Riemannian manifold Hamiltonian Monte Carlo (RMHMC) methods have significant potential advantages in this setting, but are computationally expensive. We introduce a new RMHMC method, which we call semi-separable Hamiltonian Monte Carlo, which uses a specially designed mass matrix that allows the joint Hamiltonian over model parameters and hyperparameters to decompose into two simpler Hamiltonians. This structure is exploited by a new integrator which we call the alternating blockwise leapfrog algorithm. The resulting method can mix faster than simpler Gibbs sampling while being simpler and more efficient than previous instances of RMHMC.
Piecewise Training for Undirected Models
Jul 04, 2012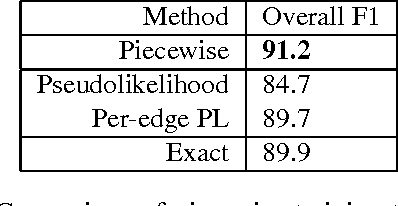
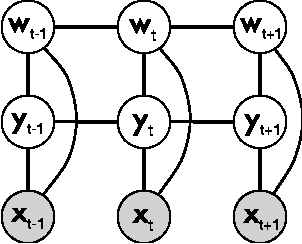
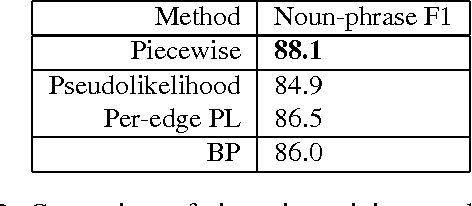
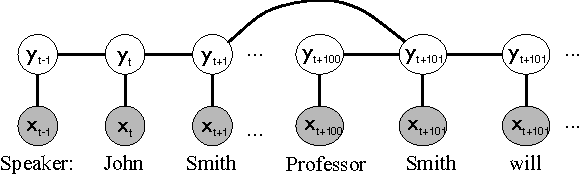
For many large undirected models that arise in real-world applications, exact maximumlikelihood training is intractable, because it requires computing marginal distributions of the model. Conditional training is even more difficult, because the partition function depends not only on the parameters, but also on the observed input, requiring repeated inference over each training example. An appealing idea for such models is to independently train a local undirected classifier over each clique, afterwards combining the learned weights into a single global model. In this paper, we show that this piecewise method can be justified as minimizing a new family of upper bounds on the log partition function. On three natural-language data sets, piecewise training is more accurate than pseudolikelihood, and often performs comparably to global training using belief propagation.
Improved Dynamic Schedules for Belief Propagation
Jun 20, 2012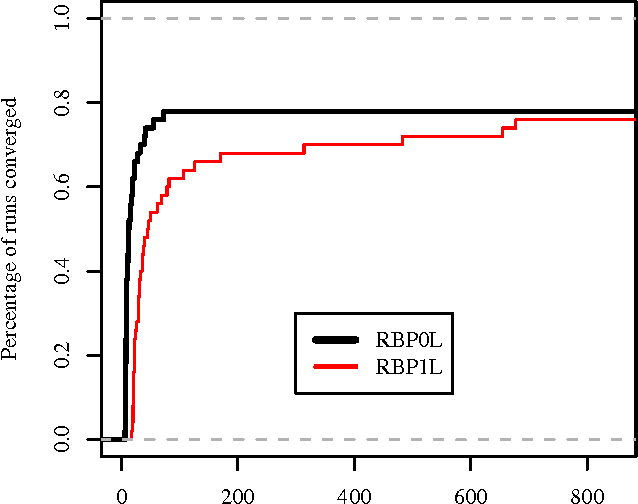

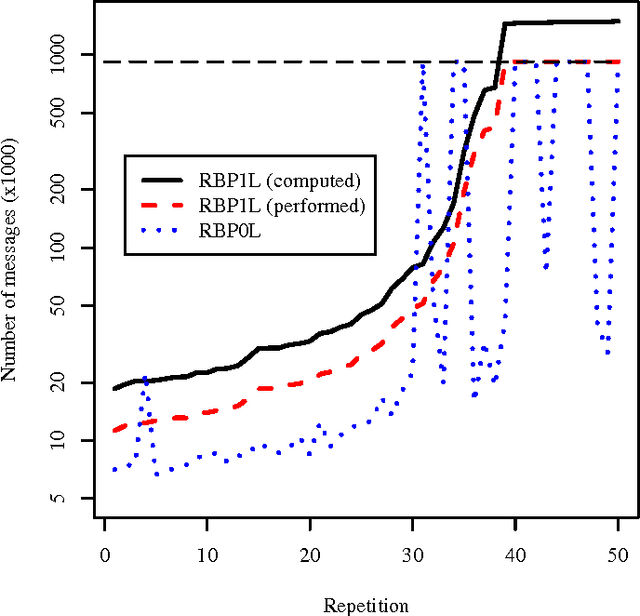
Belief propagation and its variants are popular methods for approximate inference, but their running time and even their convergence depend greatly on the schedule used to send the messages. Recently, dynamic update schedules have been shown to converge much faster on hard networks than static schedules, namely the residual BP schedule of Elidan et al. [2006]. But that RBP algorithm wastes message updates: many messages are computed solely to determine their priority, and are never actually performed. In this paper, we show that estimating the residual, rather than calculating it directly, leads to significant decreases in the number of messages required for convergence, and in the total running time. The residual is estimated using an upper bound based on recent work on message errors in BP. On both synthetic and real-world networks, this dramatically decreases the running time of BP, in some cases by a factor of five, without affecting the quality of the solution.
Bayesian inference for queueing networks and modeling of internet services
Apr 15, 2011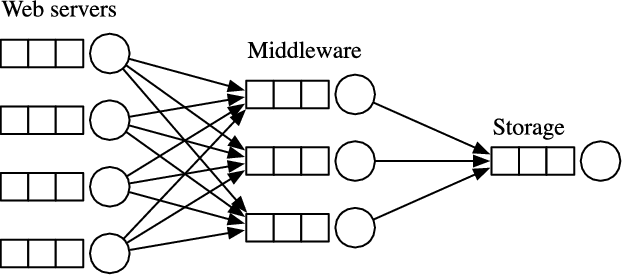

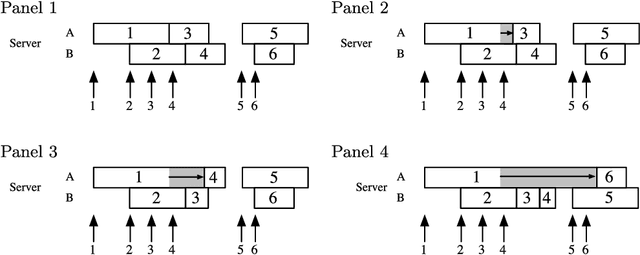

Modern Internet services, such as those at Google, Yahoo!, and Amazon, handle billions of requests per day on clusters of thousands of computers. Because these services operate under strict performance requirements, a statistical understanding of their performance is of great practical interest. Such services are modeled by networks of queues, where each queue models one of the computers in the system. A key challenge is that the data are incomplete, because recording detailed information about every request to a heavily used system can require unacceptable overhead. In this paper we develop a Bayesian perspective on queueing models in which the arrival and departure times that are not observed are treated as latent variables. Underlying this viewpoint is the observation that a queueing model defines a deterministic transformation between the data and a set of independent variables called the service times. With this viewpoint in hand, we sample from the posterior distribution over missing data and model parameters using Markov chain Monte Carlo. We evaluate our framework on data from a benchmark Web application. We also present a simple technique for selection among nested queueing models. We are unaware of any previous work that considers inference in networks of queues in the presence of missing data.
* Published in at http://dx.doi.org/10.1214/10-AOAS392 the Annals of Applied Statistics (http://www.imstat.org/aoas/) by the Institute of Mathematical Statistics (http://www.imstat.org)
An Introduction to Conditional Random Fields
Nov 17, 2010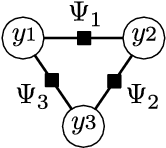

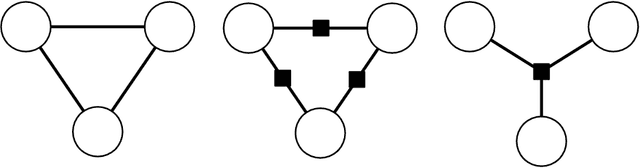

Often we wish to predict a large number of variables that depend on each other as well as on other observed variables. Structured prediction methods are essentially a combination of classification and graphical modeling, combining the ability of graphical models to compactly model multivariate data with the ability of classification methods to perform prediction using large sets of input features. This tutorial describes conditional random fields, a popular probabilistic method for structured prediction. CRFs have seen wide application in natural language processing, computer vision, and bioinformatics. We describe methods for inference and parameter estimation for CRFs, including practical issues for implementing large scale CRFs. We do not assume previous knowledge of graphical modeling, so this tutorial is intended to be useful to practitioners in a wide variety of fields.