 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedSPLIT: One-Shot Federated Recommendation System Based on Non-negative Joint Matrix Factorization and Knowledge Distillation
May 04, 2022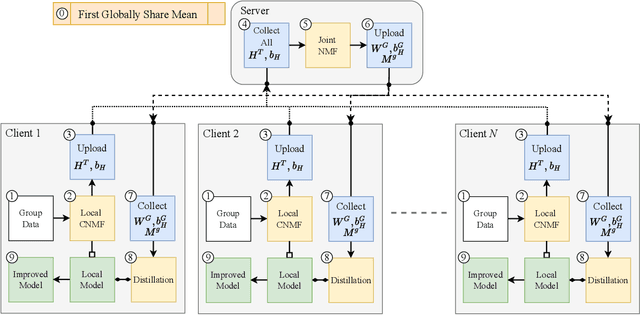

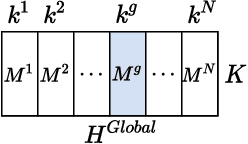

Non-negative matrix factorization (NMF) with missing-value completion is a well-known effective Collaborative Filtering (CF) method used to provide personalized user recommendations. However, traditional CF relies on the privacy-invasive collection of users' explicit and implicit feedback to build a central recommender model. One-shot federated learning has recently emerged as a method to mitigate the privacy problem while addressing the traditional communication bottleneck of federated learning. In this paper, we present the first unsupervised one-shot federated CF implementation, named FedSPLIT, based on NMF joint factorization. In our solution, the clients first apply local CF in-parallel to build distinct client-specific recommenders. Then, the privacy-preserving local item patterns and biases from each client are shared with the processor to perform joint factorization in order to extract the global item patterns. Extracted patterns are then aggregated to each client to build the local models via knowledge distillation. In our experiments, we demonstrate the feasibility of our approach with standard recommendation datasets. FedSPLIT can obtain similar results than the state of the art (and even outperform it in certain situations) with a substantial decrease in the number of communications.
Out of Distribution Data Detection Using Dropout Bayesian Neural Networks
Feb 18, 2022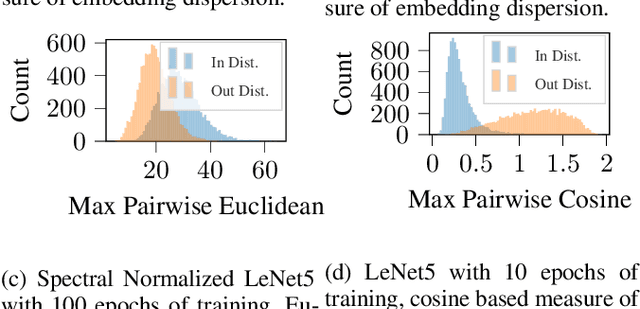
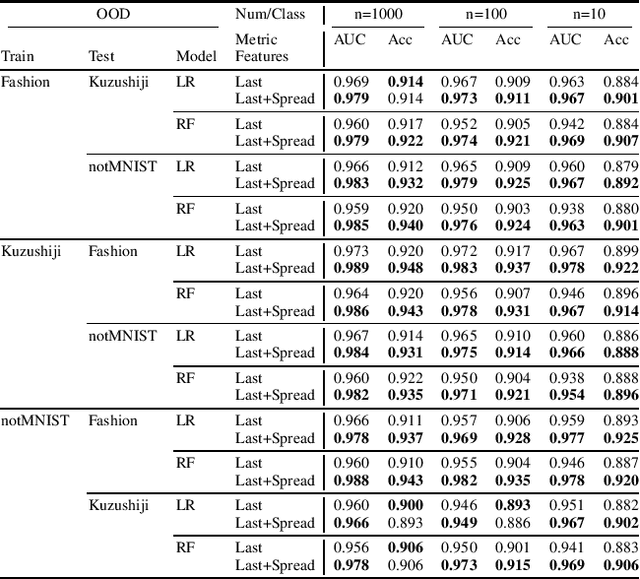
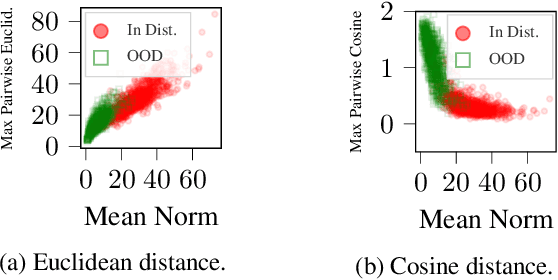
We explore the utility of information contained within a dropout based Bayesian neural network (BNN) for the task of detecting out of distribution (OOD) data. We first show how previous attempts to leverage the randomized embeddings induced by the intermediate layers of a dropout BNN can fail due to the distance metric used. We introduce an alternative approach to measuring embedding uncertainty, justify its use theoretically, and demonstrate how incorporating embedding uncertainty improves OOD data identification across three tasks: image classification, language classification, and malware detection.
Rank-1 Similarity Matrix Decomposition For Modeling Changes in Antivirus Consensus Through Time
Dec 28, 2021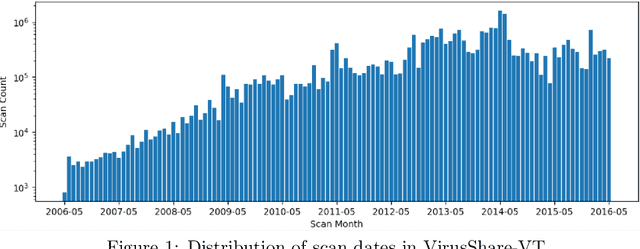
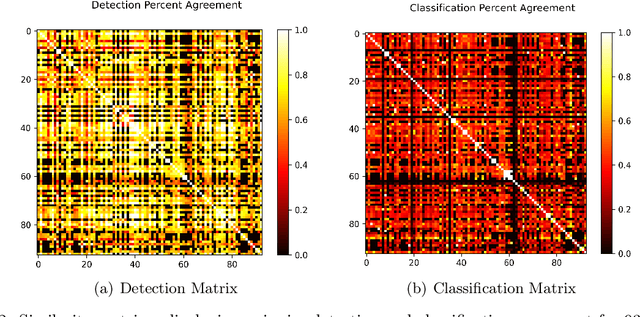
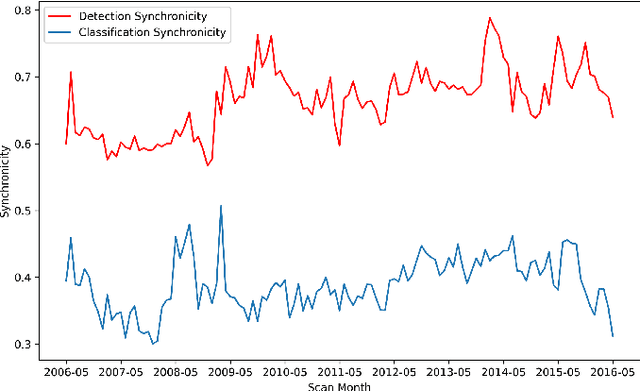
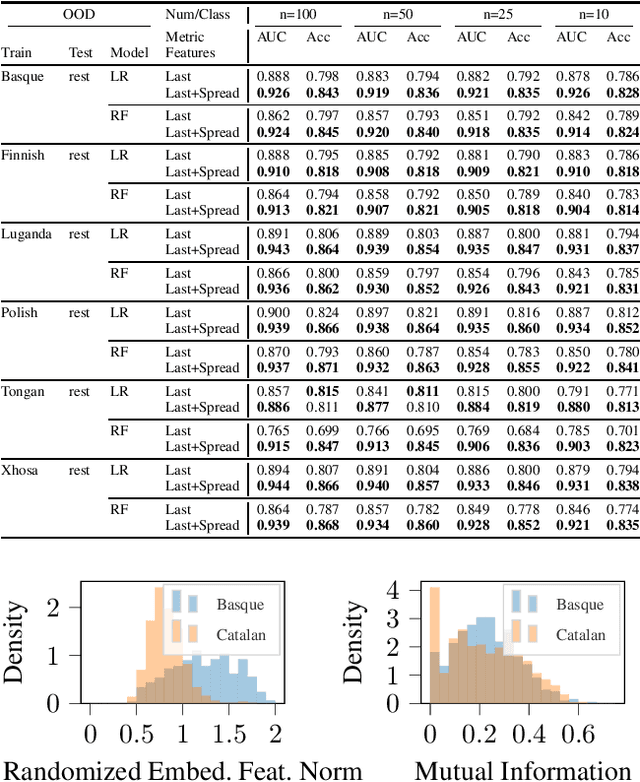
Although groups of strongly correlated antivirus engines are known to exist, at present there is limited understanding of how or why these correlations came to be. Using a corpus of 25 million VirusTotal reports representing over a decade of antivirus scan data, we challenge prevailing wisdom that these correlations primarily originate from "first-order" interactions such as antivirus vendors copying the labels of leading vendors. We introduce the Temporal Rank-1 Similarity Matrix decomposition (R1SM-T) in order to investigate the origins of these correlations and to model how consensus amongst antivirus engines changes over time. We reveal that first-order interactions do not explain as much behavior in antivirus correlation as previously thought, and that the relationships between antivirus engines are highly volatile. We make recommendations on items in need of future study and consideration based on our findings.
MOTIF: A Large Malware Reference Dataset with Ground Truth Family Labels
Nov 29, 2021
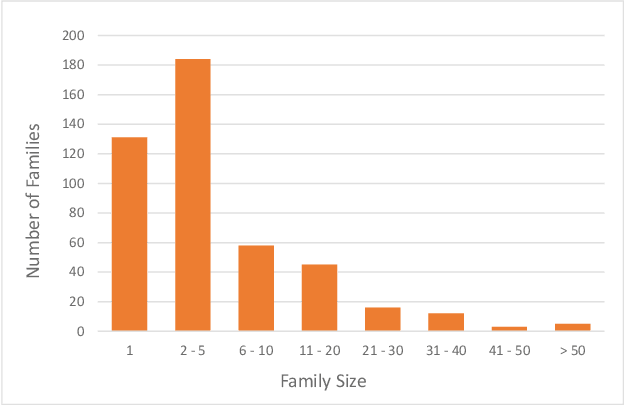
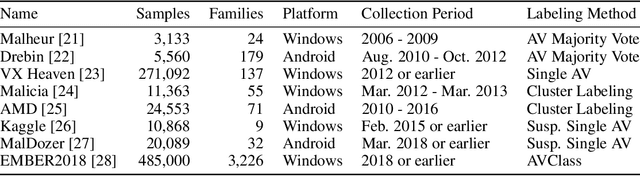

Malware family classification is a significant issue with public safety and research implications that has been hindered by the high cost of expert labels. The vast majority of corpora use noisy labeling approaches that obstruct definitive quantification of results and study of deeper interactions. In order to provide the data needed to advance further, we have created the Malware Open-source Threat Intelligence Family (MOTIF) dataset. MOTIF contains 3,095 malware samples from 454 families, making it the largest and most diverse public malware dataset with ground truth family labels to date, nearly 3x larger than any prior expert-labeled corpus and 36x larger than the prior Windows malware corpus. MOTIF also comes with a mapping from malware samples to threat reports published by reputable industry sources, which both validates the labels and opens new research opportunities in connecting opaque malware samples to human-readable descriptions. This enables important evaluations that are normally infeasible due to non-standardized reporting in industry. For example, we provide aliases of the different names used to describe the same malware family, allowing us to benchmark for the first time accuracy of existing tools when names are obtained from differing sources. Evaluation results obtained using the MOTIF dataset indicate that existing tasks have significant room for improvement, with accuracy of antivirus majority voting measured at only 62.10% and the well-known AVClass tool having just 46.78% accuracy. Our findings indicate that malware family classification suffers a type of labeling noise unlike that studied in most ML literature, due to the large open set of classes that may not be known from the sample under consideration
A Framework for Cluster and Classifier Evaluation in the Absence of Reference Labels
Sep 23, 2021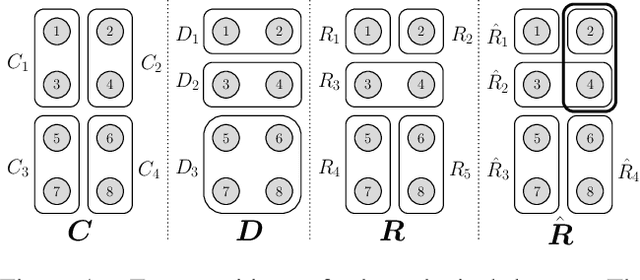
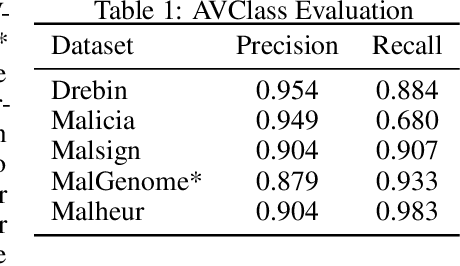
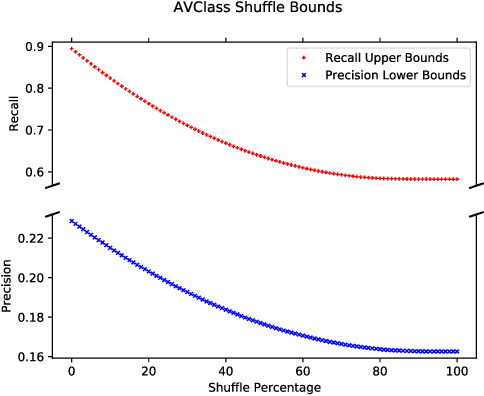
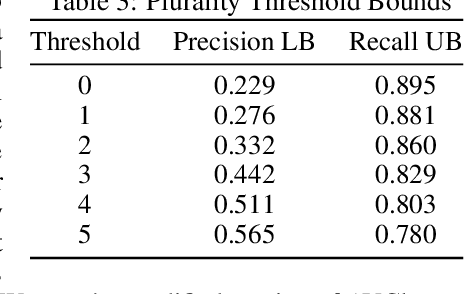
In some problem spaces, the high cost of obtaining ground truth labels necessitates use of lower quality reference datasets. It is difficult to benchmark model performance using these datasets, as evaluation results may be biased. We propose a supplement to using reference labels, which we call an approximate ground truth refinement (AGTR). Using an AGTR, we prove that bounds on specific metrics used to evaluate clustering algorithms and multi-class classifiers can be computed without reference labels. We also introduce a procedure that uses an AGTR to identify inaccurate evaluation results produced from datasets of dubious quality. Creating an AGTR requires domain knowledge, and malware family classification is a task with robust domain knowledge approaches that support the construction of an AGTR. We demonstrate our AGTR evaluation framework by applying it to a popular malware labeling tool to diagnose over-fitting in prior testing and evaluate changes whose impact could not be meaningfully quantified under previous data.
Leveraging Uncertainty for Improved Static Malware Detection Under Extreme False Positive Constraints
Aug 09, 2021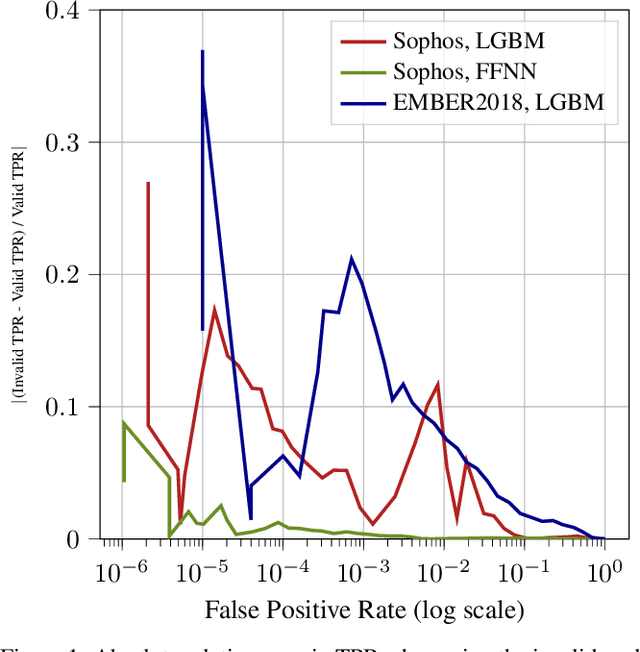
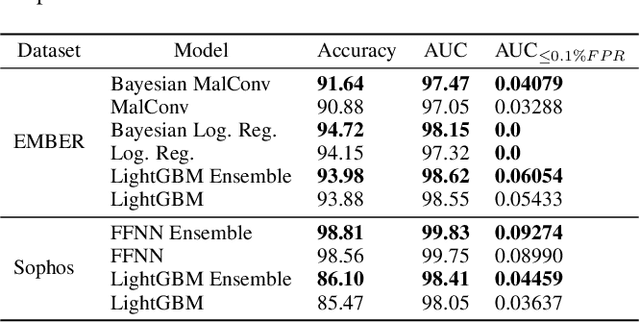
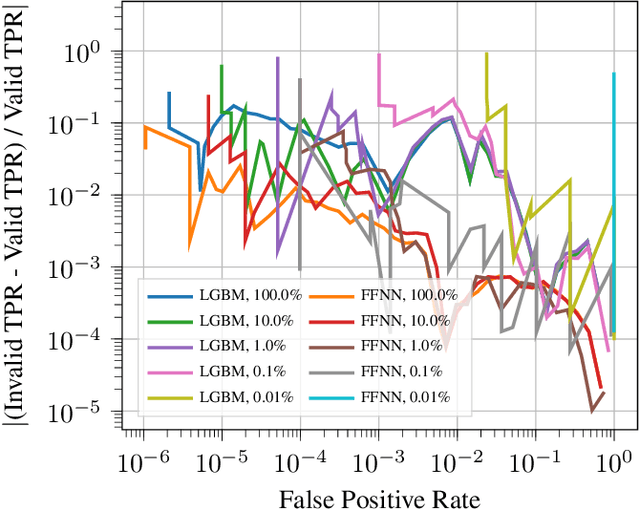
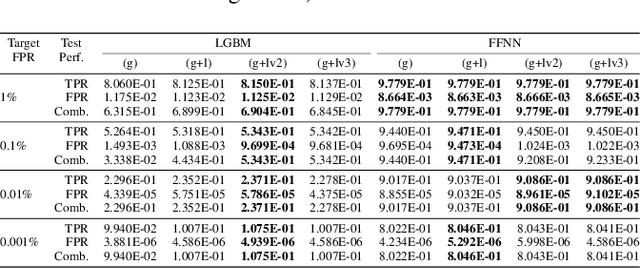
The detection of malware is a critical task for the protection of computing environments. This task often requires extremely low false positive rates (FPR) of 0.01% or even lower, for which modern machine learning has no readily available tools. We introduce the first broad investigation of the use of uncertainty for malware detection across multiple datasets, models, and feature types. We show how ensembling and Bayesian treatments of machine learning methods for static malware detection allow for improved identification of model errors, uncovering of new malware families, and predictive performance under extreme false positive constraints. In particular, we improve the true positive rate (TPR) at an actual realized FPR of 1e-5 from an expected 0.69 for previous methods to 0.80 on the best performing model class on the Sophos industry scale dataset. We additionally demonstrate how previous works have used an evaluation protocol that can lead to misleading results.
COVID-19 Multidimensional Kaggle Literature Organization
Jul 20, 2021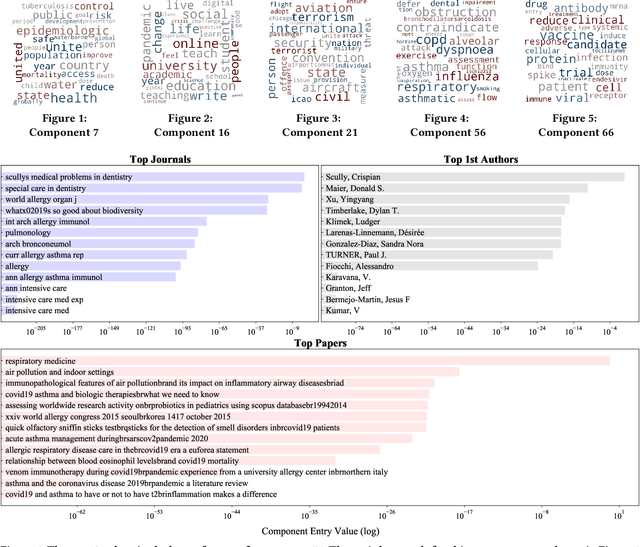
The unprecedented outbreak of Severe Acute Respiratory Syndrome Coronavirus-2 (SARS-CoV-2), or COVID-19, continues to be a significant worldwide problem. As a result, a surge of new COVID-19 related research has followed suit. The growing number of publications requires document organization methods to identify relevant information. In this paper, we expand upon our previous work with clustering the CORD-19 dataset by applying multi-dimensional analysis methods. Tensor factorization is a powerful unsupervised learning method capable of discovering hidden patterns in a document corpus. We show that a higher-order representation of the corpus allows for the simultaneous grouping of similar articles, relevant journals, authors with similar research interests, and topic keywords. These groupings are identified within and among the latent components extracted via tensor decomposition. We further demonstrate the application of this method with a publicly available interactive visualization of the dataset.
Evading Malware Classifiers via Monte Carlo Mutant Feature Discovery
Jun 15, 2021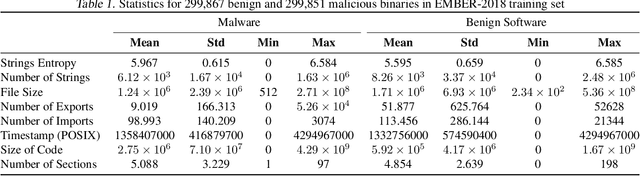
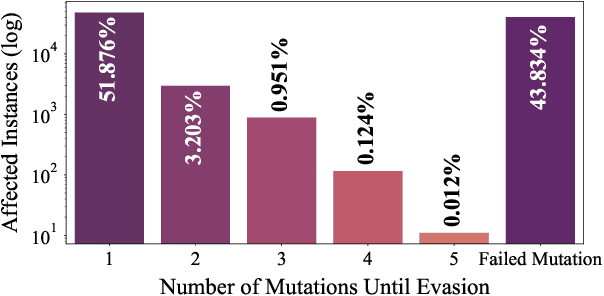
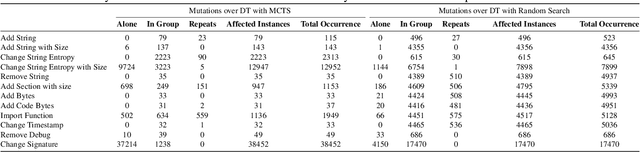
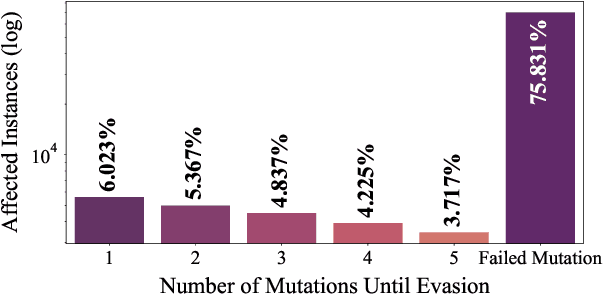
The use of Machine Learning has become a significant part of malware detection efforts due to the influx of new malware, an ever changing threat landscape, and the ability of Machine Learning methods to discover meaningful distinctions between malicious and benign software. Antivirus vendors have also begun to widely utilize malware classifiers based on dynamic and static malware analysis features. Therefore, a malware author might make evasive binary modifications against Machine Learning models as part of the malware development life cycle to execute an attack successfully. This makes the studying of possible classifier evasion strategies an essential part of cyber defense against malice. To this extent, we stage a grey box setup to analyze a scenario where the malware author does not know the target classifier algorithm, and does not have access to decisions made by the classifier, but knows the features used in training. In this experiment, a malicious actor trains a surrogate model using the EMBER-2018 dataset to discover binary mutations that cause an instance to be misclassified via a Monte Carlo tree search. Then, mutated malware is sent to the victim model that takes the place of an antivirus API to test whether it can evade detection.
Automatic Yara Rule Generation Using Biclustering
Sep 06, 2020
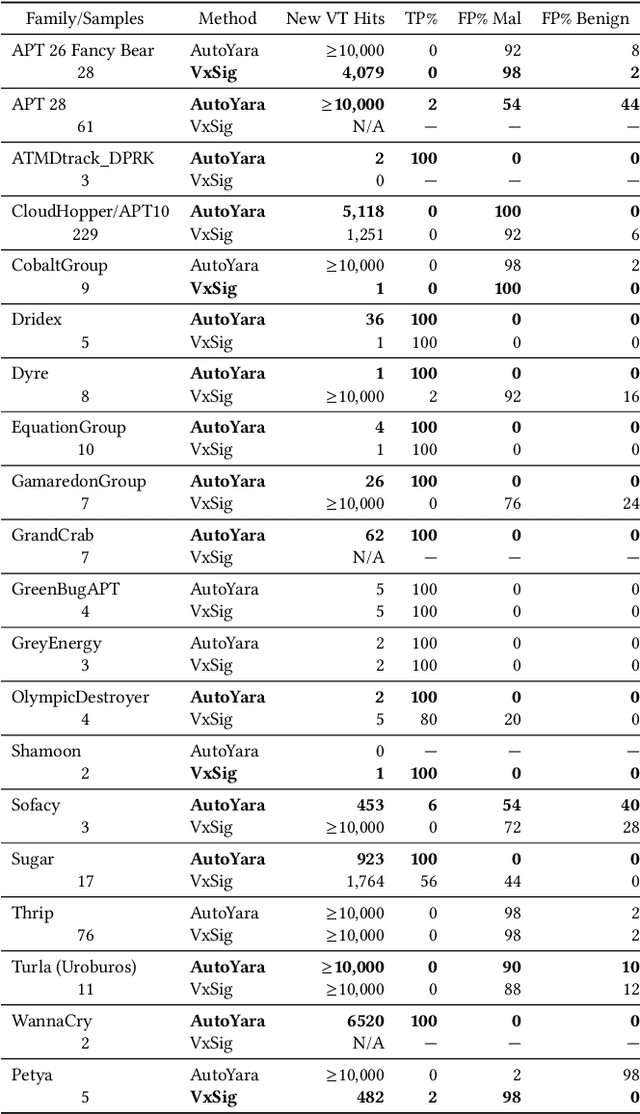
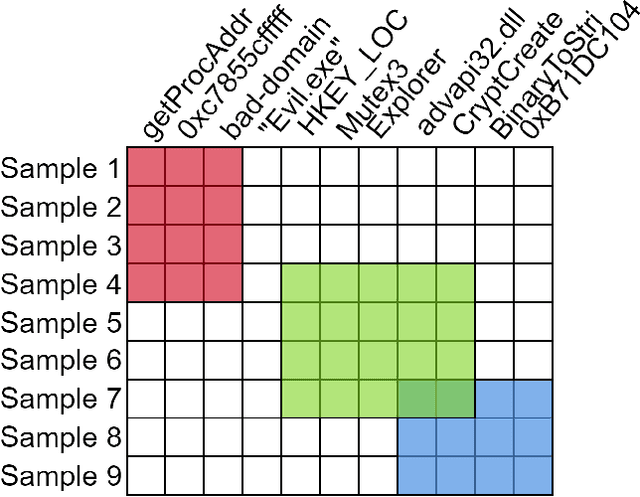
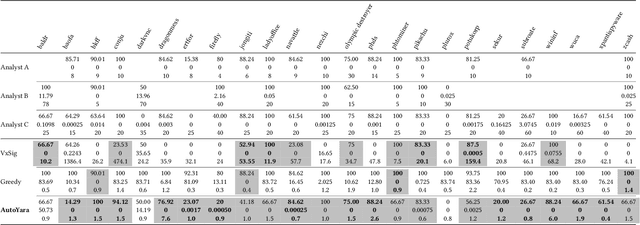
Yara rules are a ubiquitous tool among cybersecurity practitioners and analysts. Developing high-quality Yara rules to detect a malware family of interest can be labor- and time-intensive, even for expert users. Few tools exist and relatively little work has been done on how to automate the generation of Yara rules for specific families. In this paper, we leverage large n-grams ($n \geq 8$) combined with a new biclustering algorithm to construct simple Yara rules more effectively than currently available software. Our method, AutoYara, is fast, allowing for deployment on low-resource equipment for teams that deploy to remote networks. Our results demonstrate that AutoYara can help reduce analyst workload by producing rules with useful true-positive rates while maintaining low false-positive rates, sometimes matching or even outperforming human analysts. In addition, real-world testing by malware analysts indicates AutoYara could reduce analyst time spent constructing Yara rules by 44-86%, allowing them to spend their time on the more advanced malware that current tools can't handle. Code will be made available at https://github.com/NeuromorphicComputationResearchProgram .
COVID-19 Kaggle Literature Organization
Sep 02, 2020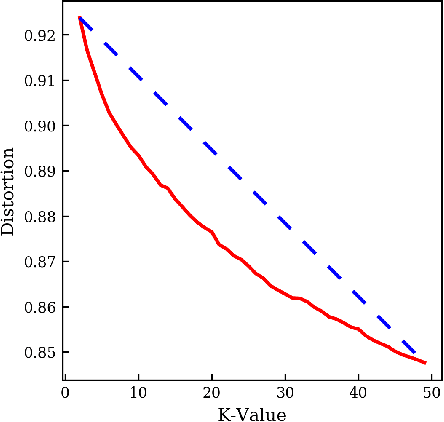
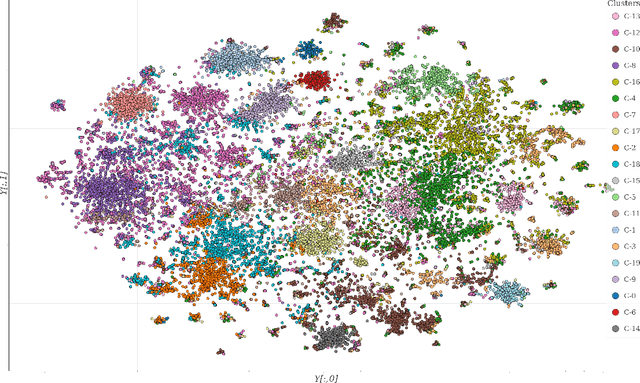
The world has faced the devastating outbreak of Severe Acute Respiratory Syndrome Coronavirus-2 (SARS-CoV-2), or COVID-19, in 2020. Research in the subject matter was fast-tracked to such a point that scientists were struggling to keep up with new findings. With this increase in the scientific literature, there arose a need for organizing those documents. We describe an approach to organize and visualize the scientific literature on or related to COVID-19 using machine learning techniques so that papers on similar topics are grouped together. By doing so, the navigation of topics and related papers is simplified. We implemented this approach using the widely recognized CORD-19 dataset to present a publicly available proof of concept.