 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopicTag: Automatic Annotation of NMF Topic Models Using Chain of Thought and Prompt Tuning with LLMs
Jul 29, 2024


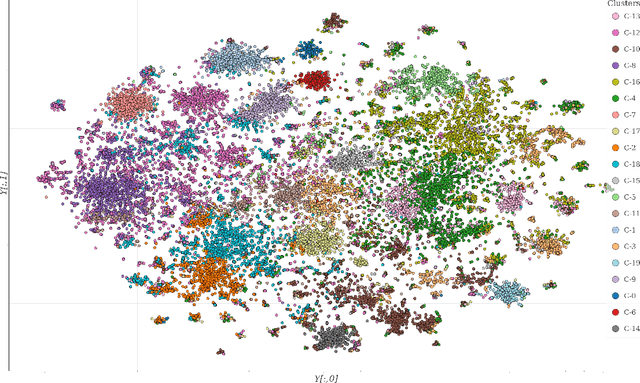
Topic modeling is a technique for organizing and extracting themes from large collections of unstructured text. Non-negative matrix factorization (NMF) is a common unsupervised approach that decomposes a term frequency-inverse document frequency (TF-IDF) matrix to uncover latent topics and segment the dataset accordingly. While useful for highlighting patterns and clustering documents, NMF does not provide explicit topic labels, necessitating subject matter experts (SMEs) to assign labels manually. We present a methodology for automating topic labeling in documents clustered via NMF with automatic model determination (NMFk). By leveraging the output of NMFk and employing prompt engineering, we utilize large language models (LLMs) to generate accurate topic labels. Our case study on over 34,000 scientific abstracts on Knowledge Graphs demonstrates the effectiveness of our method in enhancing knowledge management and document organization.
SeNMFk-SPLIT: Large Corpora Topic Modeling by Semantic Non-negative Matrix Factorization with Automatic Model Selection
Aug 21, 2022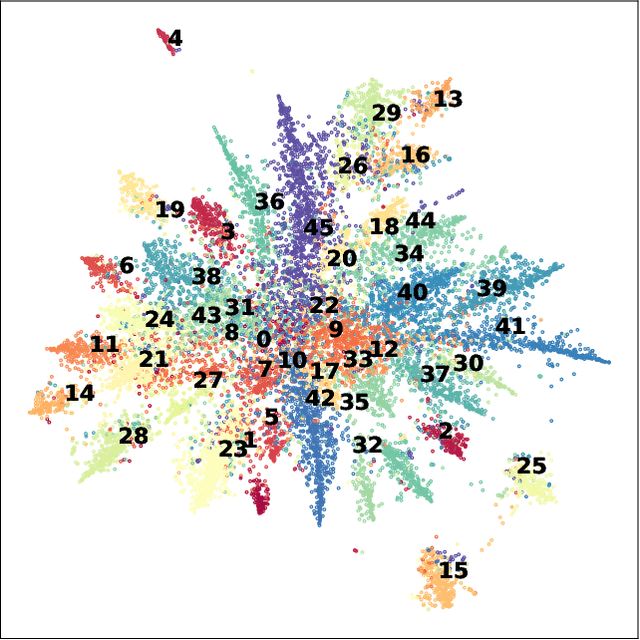


As the amount of text data continues to grow, topic modeling is serving an important role in understanding the content hidden by the overwhelming quantity of documents. One popular topic modeling approach is non-negative matrix factorization (NMF), an unsupervised machine learning (ML) method. Recently, Semantic NMF with automatic model selection (SeNMFk) has been proposed as a modification to NMF. In addition to heuristically estimating the number of topics, SeNMFk also incorporates the semantic structure of the text. This is performed by jointly factorizing the term frequency-inverse document frequency (TF-IDF) matrix with the co-occurrence/word-context matrix, the values of which represent the number of times two words co-occur in a predetermined window of the text. In this paper, we introduce a novel distributed method, SeNMFk-SPLIT, for semantic topic extraction suitable for large corpora. Contrary to SeNMFk, our method enables the joint factorization of large documents by decomposing the word-context and term-document matrices separately. We demonstrate the capability of SeNMFk-SPLIT by applying it to the entire artificial intelligence (AI) and ML scientific literature uploaded on arXiv.
COVID-19 Multidimensional Kaggle Literature Organization
Jul 20, 2021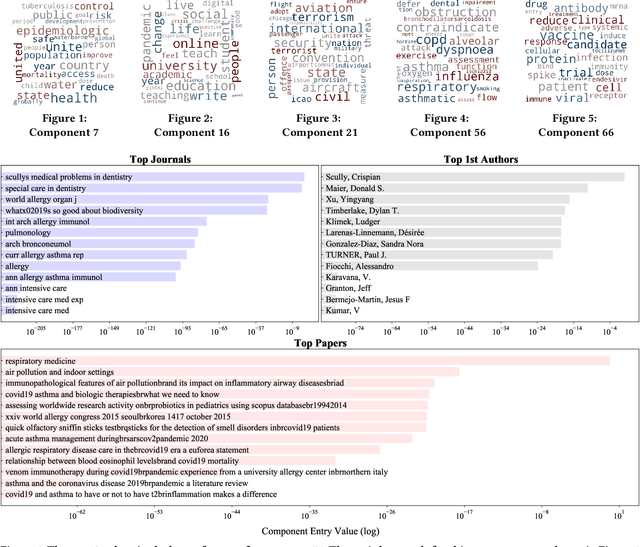
The unprecedented outbreak of Severe Acute Respiratory Syndrome Coronavirus-2 (SARS-CoV-2), or COVID-19, continues to be a significant worldwide problem. As a result, a surge of new COVID-19 related research has followed suit. The growing number of publications requires document organization methods to identify relevant information. In this paper, we expand upon our previous work with clustering the CORD-19 dataset by applying multi-dimensional analysis methods. Tensor factorization is a powerful unsupervised learning method capable of discovering hidden patterns in a document corpus. We show that a higher-order representation of the corpus allows for the simultaneous grouping of similar articles, relevant journals, authors with similar research interests, and topic keywords. These groupings are identified within and among the latent components extracted via tensor decomposition. We further demonstrate the application of this method with a publicly available interactive visualization of the dataset.
COVID-19 Kaggle Literature Organization
Sep 02, 2020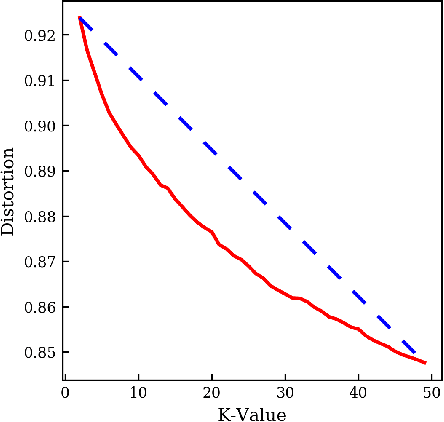
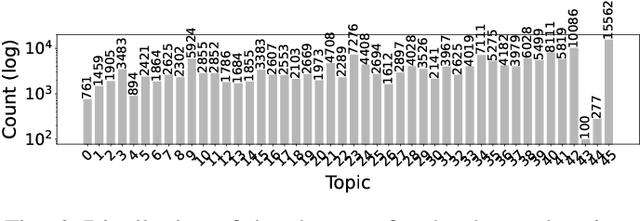
The world has faced the devastating outbreak of Severe Acute Respiratory Syndrome Coronavirus-2 (SARS-CoV-2), or COVID-19, in 2020. Research in the subject matter was fast-tracked to such a point that scientists were struggling to keep up with new findings. With this increase in the scientific literature, there arose a need for organizing those documents. We describe an approach to organize and visualize the scientific literature on or related to COVID-19 using machine learning techniques so that papers on similar topics are grouped together. By doing so, the navigation of topics and related papers is simplified. We implemented this approach using the widely recognized CORD-19 dataset to present a publicly available proof of concept.