 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoVLM: Dynamic Mixture-of-Experts Vision-Language Model for Universal Ultrasound Intelligence
Sep 18, 2025


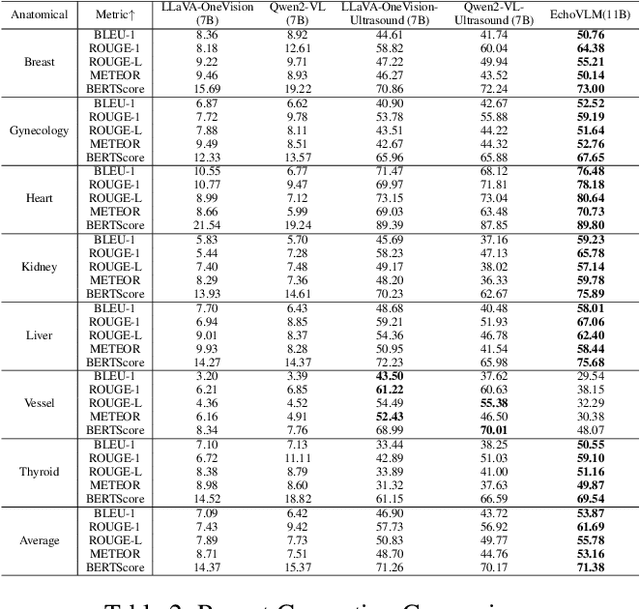
Ultrasound imaging has become the preferred imaging modality for early cancer screening due to its advantages of non-ionizing radiation, low cost, and real-time imaging capabilities. However, conventional ultrasound diagnosis heavily relies on physician expertise, presenting challenges of high subjectivity and low diagnostic efficiency. Vision-language models (VLMs) offer promising solutions for this issue, but existing general-purpose models demonstrate limited knowledge in ultrasound medical tasks, with poor generalization in multi-organ lesion recognition and low efficiency across multi-task diagnostics. To address these limitations, we propose EchoVLM, a vision-language model specifically designed for ultrasound medical imaging. The model employs a Mixture of Experts (MoE) architecture trained on data spanning seven anatomical regions. This design enables the model to perform multiple tasks, including ultrasound report generation, diagnosis and visual question-answering (VQA). The experimental results demonstrated that EchoVLM achieved significant improvements of 10.15 and 4.77 points in BLEU-1 scores and ROUGE-1 scores respectively compared to Qwen2-VL on the ultrasound report generation task. These findings suggest that EchoVLM has substantial potential to enhance diagnostic accuracy in ultrasound imaging, thereby providing a viable technical solution for future clinical applications. Source code and model weights are available at https://github.com/Asunatan/EchoVLM.
A Retrospective Systematic Study on Hierarchical Sparse Query Transformer-assisted Ultrasound Screening for Early Hepatocellular Carcinoma
Feb 06, 2025Hepatocellular carcinoma (HCC) ranks as the third leading cause of cancer-related mortality worldwide, with early detection being crucial for improving patient survival rates. However, early screening for HCC using ultrasound suffers from insufficient sensitivity and is highly dependent on the expertise of radiologists for interpretation. Leveraging the latest advancements in artificial intelligence (AI) in medical imaging, this study proposes an innovative Hierarchical Sparse Query Transformer (HSQformer) model that combines the strengths of Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) to enhance the accuracy of HCC diagnosis in ultrasound screening. The HSQformer leverages sparse latent space representations to capture hierarchical details at various granularities without the need for complex adjustments, and adopts a modular, plug-and-play design philosophy, ensuring the model's versatility and ease of use. The HSQformer's performance was rigorously tested across three distinct clinical scenarios: single-center, multi-center, and high-risk patient testing. In each of these settings, it consistently outperformed existing state-of-the-art models, such as ConvNext and SwinTransformer. Notably, the HSQformer even matched the diagnostic capabilities of senior radiologists and comprehensively surpassed those of junior radiologists. The experimental results from this study strongly demonstrate the effectiveness and clinical potential of AI-assisted tools in HCC screening. The full code is available at https://github.com/Asunatan/HSQformer.
LM-Net: A Light-weight and Multi-scale Network for Medical Image Segmentation
Jan 07, 2025Current medical image segmentation approaches have limitations in deeply exploring multi-scale information and effectively combining local detail textures with global contextual semantic information. This results in over-segmentation, under-segmentation, and blurred segmentation boundaries. To tackle these challenges, we explore multi-scale feature representations from different perspectives, proposing a novel, lightweight, and multi-scale architecture (LM-Net) that integrates advantages of both Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) to enhance segmentation accuracy. LM-Net employs a lightweight multi-branch module to capture multi-scale features at the same level. Furthermore, we introduce two modules to concurrently capture local detail textures and global semantics with multi-scale features at different levels: the Local Feature Transformer (LFT) and Global Feature Transformer (GFT). The LFT integrates local window self-attention to capture local detail textures, while the GFT leverages global self-attention to capture global contextual semantics. By combining these modules, our model achieves complementarity between local and global representations, alleviating the problem of blurred segmentation boundaries in medical image segmentation. To evaluate the feasibility of LM-Net, extensive experiments have been conducted on three publicly available datasets with different modalities. Our proposed model achieves state-of-the-art results, surpassing previous methods, while only requiring 4.66G FLOPs and 5.4M parameters. These state-of-the-art results on three datasets with different modalities demonstrate the effectiveness and adaptability of our proposed LM-Net for various medical image segmentation tasks.