 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuarding the Middle: Protecting Intermediate Representations in Federated Split Learning
Feb 19, 2026Big data scenarios, where massive, heterogeneous datasets are distributed across clients, demand scalable, privacy-preserving learning methods. Federated learning (FL) enables decentralized training of machine learning (ML) models across clients without data centralization. Decentralized training, however, introduces a computational burden on client devices. U-shaped federated split learning (UFSL) offloads a fraction of the client computation to the server while keeping both data and labels on the clients' side. However, the intermediate representations (i.e., smashed data) shared by clients with the server are prone to exposing clients' private data. To reduce exposure of client data through intermediate data representations, this work proposes k-anonymous differentially private UFSL (KD-UFSL), which leverages privacy-enhancing techniques such as microaggregation and differential privacy to minimize data leakage from the smashed data transferred to the server. We first demonstrate that an adversary can access private client data from intermediate representations via a data-reconstruction attack, and then present a privacy-enhancing solution, KD-UFSL, to mitigate this risk. Our experiments indicate that, alongside increasing the mean squared error between the actual and reconstructed images by up to 50% in some cases, KD-UFSL also decreases the structural similarity between them by up to 40% on four benchmarking datasets. More importantly, KD-UFSL improves privacy while preserving the utility of the global model. This highlights its suitability for large-scale big data applications where privacy and utility must be balanced.
Catastrophic Forgetting Resilient One-Shot Incremental Federated Learning
Feb 19, 2026Modern big-data systems generate massive, heterogeneous, and geographically dispersed streams that are large-scale and privacy-sensitive, making centralization challenging. While federated learning (FL) provides a privacy-enhancing training mechanism, it assumes a static data flow and learns a collaborative model over multiple rounds, making learning with \textit{incremental} data challenging in limited-communication scenarios. This paper presents One-Shot Incremental Federated Learning (OSI-FL), the first FL framework that addresses the dual challenges of communication overhead and catastrophic forgetting. OSI-FL communicates category-specific embeddings, devised by a frozen vision-language model (VLM) from each client in a single communication round, which a pre-trained diffusion model at the server uses to synthesize new data similar to the client's data distribution. The synthesized samples are used on the server for training. However, two challenges still persist: i) tasks arriving incrementally need to retrain the global model, and ii) as future tasks arrive, retraining the model introduces catastrophic forgetting. To this end, we augment training with Selective Sample Retention (SSR), which identifies and retains the top-p most informative samples per category and task pair based on sample loss. SSR bounds forgetting by ensuring that representative retained samples are incorporated into training in further iterations. The experimental results indicate that OSI-FL outperforms baselines, including traditional and one-shot FL approaches, in both class-incremental and domain-incremental scenarios across three benchmark datasets.
Federated Learning for Large-Scale Cloud Robotic Manipulation: Opportunities and Challenges
Jul 23, 2025Federated Learning (FL) is an emerging distributed machine learning paradigm, where the collaborative training of a model involves dynamic participation of devices to achieve broad objectives. In contrast, classical machine learning (ML) typically requires data to be located on-premises for training, whereas FL leverages numerous user devices to train a shared global model without the need to share private data. Current robotic manipulation tasks are constrained by the individual capabilities and speed of robots due to limited low-latency computing resources. Consequently, the concept of cloud robotics has emerged, allowing robotic applications to harness the flexibility and reliability of computing resources, effectively alleviating their computational demands across the cloud-edge continuum. Undoubtedly, within this distributed computing context, as exemplified in cloud robotic manipulation scenarios, FL offers manifold advantages while also presenting several challenges and opportunities. In this paper, we present fundamental concepts of FL and their connection to cloud robotic manipulation. Additionally, we envision the opportunities and challenges associated with realizing efficient and reliable cloud robotic manipulation at scale through FL, where researchers adopt to design and verify FL models in either centralized or decentralized settings.
A Comprehensive Empirical Evaluation of Existing Word Embedding Approaches
Mar 13, 2023

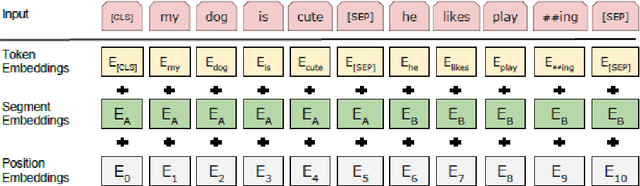

Vector-based word representations help countless Natural Language Processing (NLP) tasks capture both semantic and syntactic regularities of the language. In this paper, we present the characteristics of existing word embedding approaches and analyze them with regards to many classification tasks. We categorize the methods into two main groups - Traditional approaches mostly use matrix factorization to produce word representations, and they are not able to capture the semantic and syntactic regularities of the language very well. Neural-Network based approaches, on the other hand, can capture sophisticated regularities of the language and preserve the word relationships in the generated word representations. We report experimental results on multiple classification tasks and highlight the scenarios where one approach performs better than the rest.