 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Coresets for Support Vector Machines
Feb 15, 2020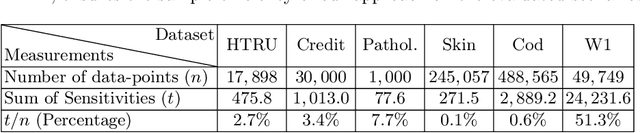
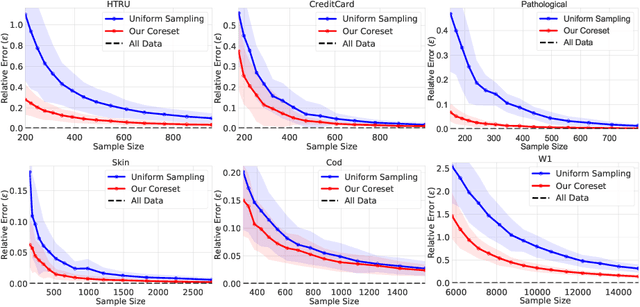
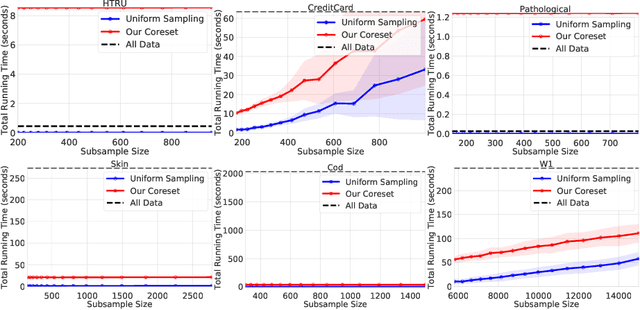
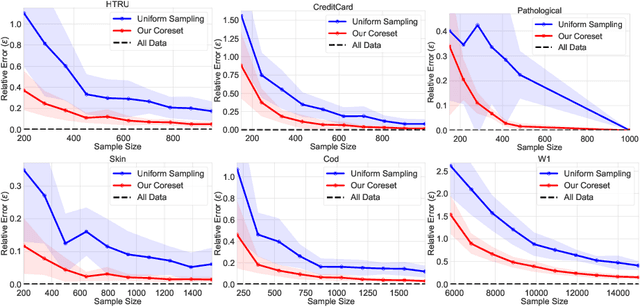
We present an efficient coreset construction algorithm for large-scale Support Vector Machine (SVM) training in Big Data and streaming applications. A coreset is a small, representative subset of the original data points such that a models trained on the coreset are provably competitive with those trained on the original data set. Since the size of the coreset is generally much smaller than the original set, our preprocess-then-train scheme has potential to lead to significant speedups when training SVM models. We prove lower and upper bounds on the size of the coreset required to obtain small data summaries for the SVM problem. As a corollary, we show that our algorithm can be used to extend the applicability of any off-the-shelf SVM solver to streaming, distributed, and dynamic data settings. We evaluate the performance of our algorithm on real-world and synthetic data sets. Our experimental results reaffirm the favorable theoretical properties of our algorithm and demonstrate its practical effectiveness in accelerating SVM training.
Provable Filter Pruning for Efficient Neural Networks
Nov 18, 2019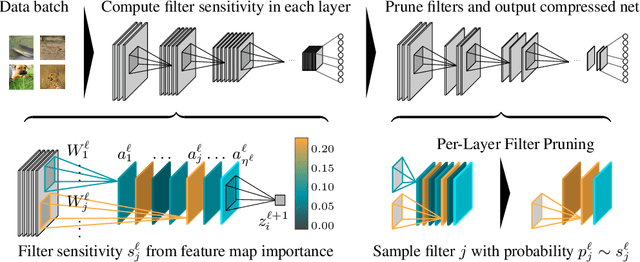

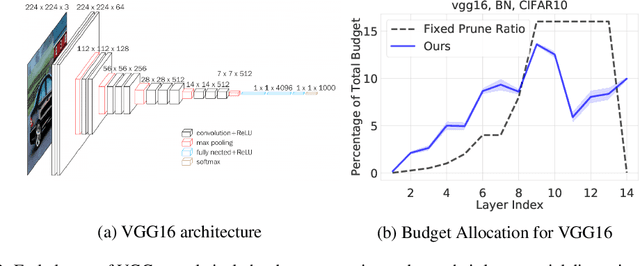
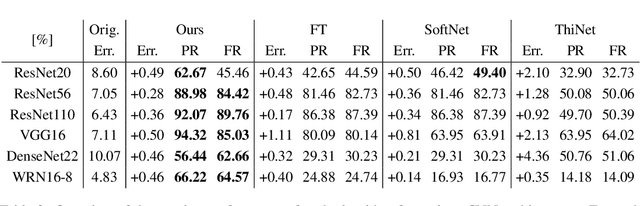
We present a provable, sampling-based approach for generating compact Convolutional Neural Networks (CNNs) by identifying and removing redundant filters from an over-parameterized network. Our algorithm uses a small batch of input data points to assign a saliency score to each filter and constructs an importance sampling distribution where filters that highly affect the output are sampled with correspondingly high probability. In contrast to existing filter pruning approaches, our method is simultaneously data-informed, exhibits provable guarantees on the size and performance of the pruned network, and is widely applicable to varying network architectures and data sets. Our analytical bounds bridge the notions of compressibility and importance of network structures, which gives rise to a fully-automated procedure for identifying and preserving filters in layers that are essential to the network's performance. Our experimental evaluations on popular architectures and data sets show that our algorithm consistently generates sparser and more efficient models than those constructed by existing filter pruning approaches.
SiPPing Neural Networks: Sensitivity-informed Provable Pruning of Neural Networks
Oct 11, 2019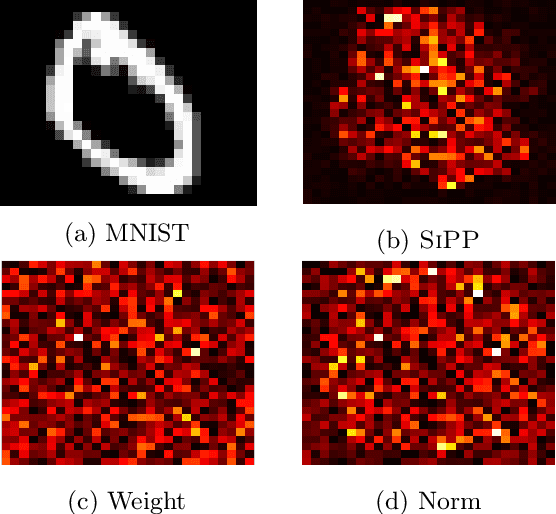
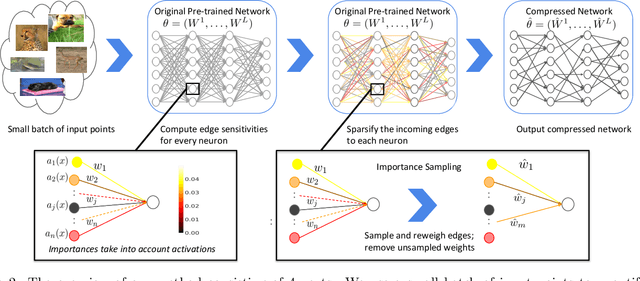
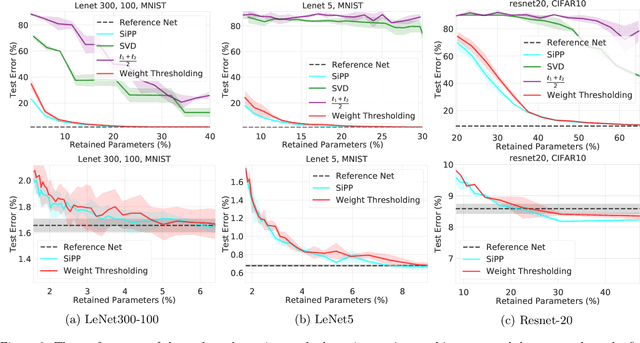
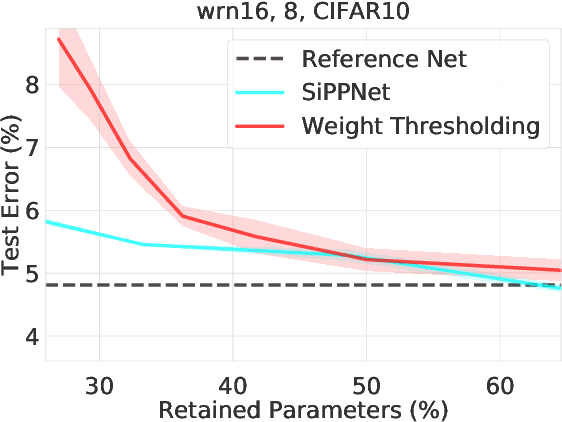
We introduce a pruning algorithm that provably sparsifies the parameters of a trained model in a way that approximately preserves the model's predictive accuracy. Our algorithm uses a small batch of input points to construct a data-informed importance sampling distribution over the network's parameters, and adaptively mixes a sampling-based and deterministic pruning procedure to discard redundant weights. Our pruning method is simultaneously computationally efficient, provably accurate, and broadly applicable to various network architectures and data distributions. Our empirical comparisons show that our algorithm reliably generates highly compressed networks that incur minimal loss in performance relative to that of the original network. We present experimental results that demonstrate our algorithm's potential to unearth essential network connections that can be trained successfully in isolation, which may be of independent interest.
Data-Dependent Coresets for Compressing Neural Networks with Applications to Generalization Bounds
Sep 05, 2018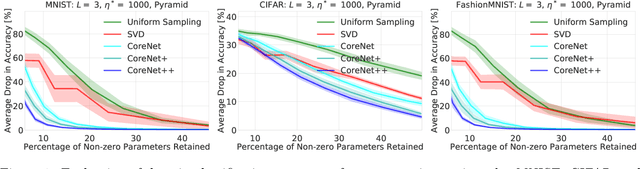
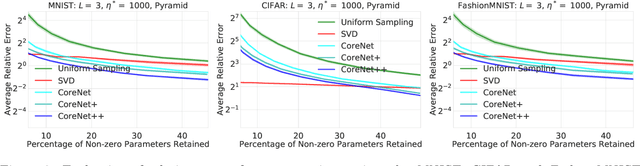
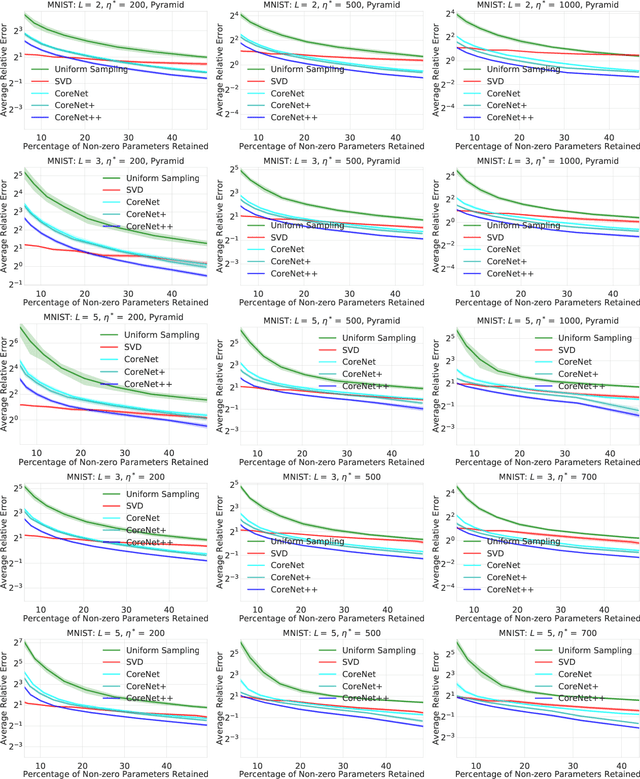
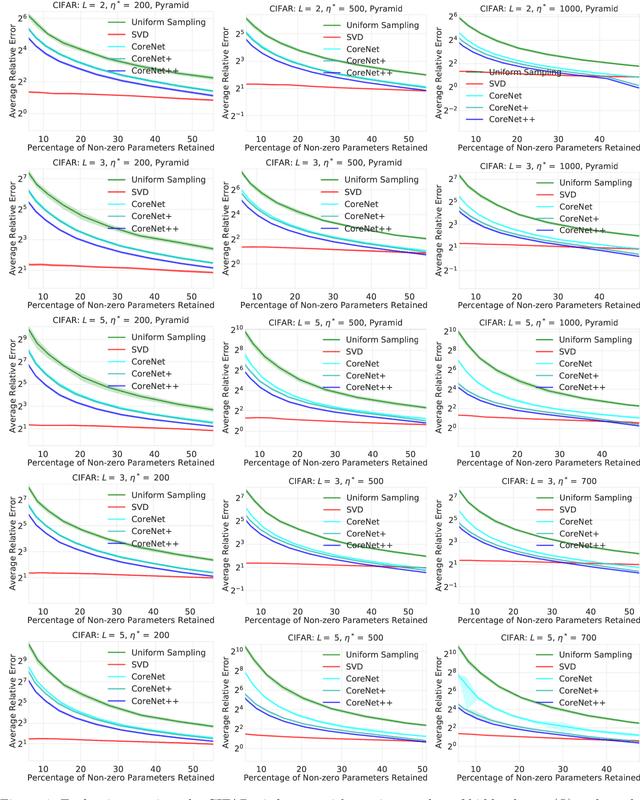
We present an efficient coresets-based neural network compression algorithm that provably sparsifies the parameters of a trained fully-connected neural network in a manner that approximately preserves the network's output. Our approach is based on an importance sampling scheme that judiciously defines a sampling distribution over the neural network parameters, and as a result, retains parameters of high importance while discarding redundant ones. We leverage a novel, empirical notion of sensitivity and extend traditional coreset constructions to the application of compressing parameters. Our theoretical analysis establishes guarantees on the size and accuracy of the resulting compressed neural network and gives rise to new generalization bounds that may provide novel insights on the generalization properties of neural networks. We demonstrate the practical effectiveness of our algorithm on a variety of neural network configurations and real-world data sets.
Training Support Vector Machines using Coresets
Nov 10, 2017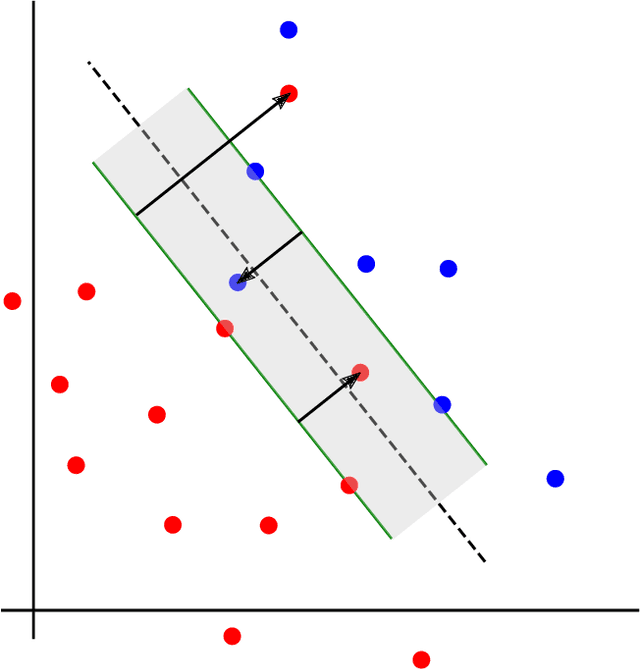
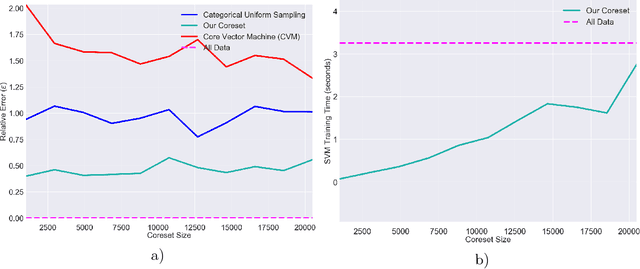
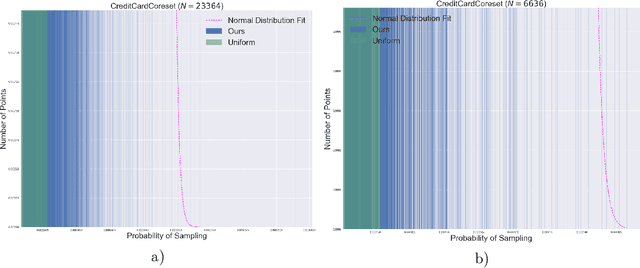
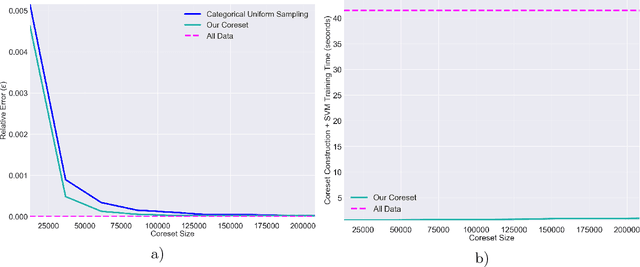
We present a novel coreset construction algorithm for solving classification tasks using Support Vector Machines (SVMs) in a computationally efficient manner. A coreset is a weighted subset of the original data points that provably approximates the original set. We show that coresets of size polylogarithmic in $n$ and polynomial in $d$ exist for a set of $n$ input points with $d$ features and present an $(\epsilon,\delta)$-FPRAS for constructing coresets for scalable SVM training. Our method leverages the insight that data points are often redundant and uses an importance sampling scheme based on the sensitivity of each data point to construct coresets efficiently. We evaluate the performance of our algorithm in accelerating SVM training against real-world data sets and compare our algorithm to state-of-the-art coreset approaches. Our empirical results show that our approach outperforms a state-of-the-art coreset approach and uniform sampling in enabling computational speedups while achieving low approximation error.