 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePattern Detection in the Activation Space for Identifying Synthesized Content
May 27, 2021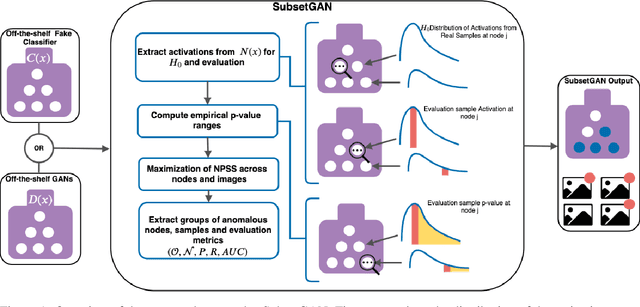
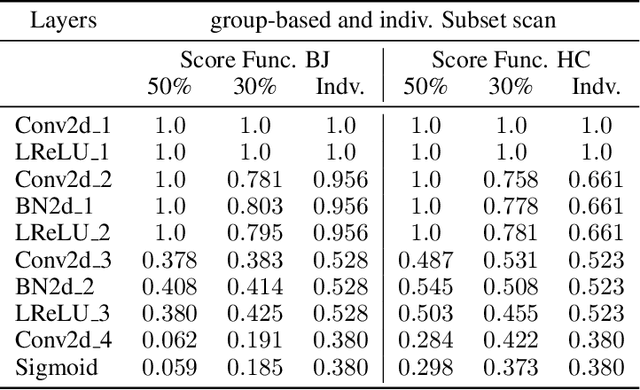
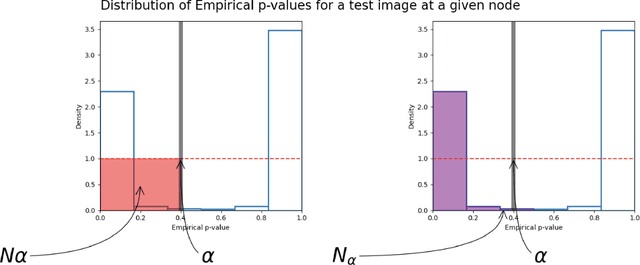

Generative Adversarial Networks (GANs) have recently achieved unprecedented success in photo-realistic image synthesis from low-dimensional random noise. The ability to synthesize high-quality content at a large scale brings potential risks as the generated samples may lead to misinformation that can create severe social, political, health, and business hazards. We propose SubsetGAN to identify generated content by detecting a subset of anomalous node-activations in the inner layers of pre-trained neural networks. These nodes, as a group, maximize a non-parametric measure of divergence away from the expected distribution of activations created from real data. This enable us to identify synthesised images without prior knowledge of their distribution. SubsetGAN efficiently scores subsets of nodes and returns the group of nodes within the pre-trained classifier that contributed to the maximum score. The classifier can be a general fake classifier trained over samples from multiple sources or the discriminator network from different GANs. Our approach shows consistently higher detection power than existing detection methods across several state-of-the-art GANs (PGGAN, StarGAN, and CycleGAN) and over different proportions of generated content.
Towards creativity characterization of generative models via group-based subset scanning
Apr 01, 2021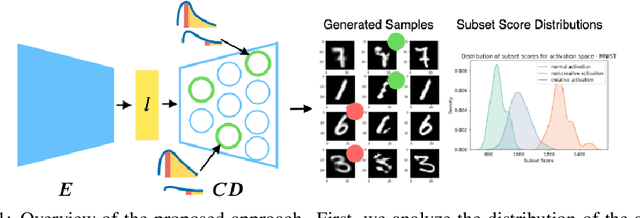
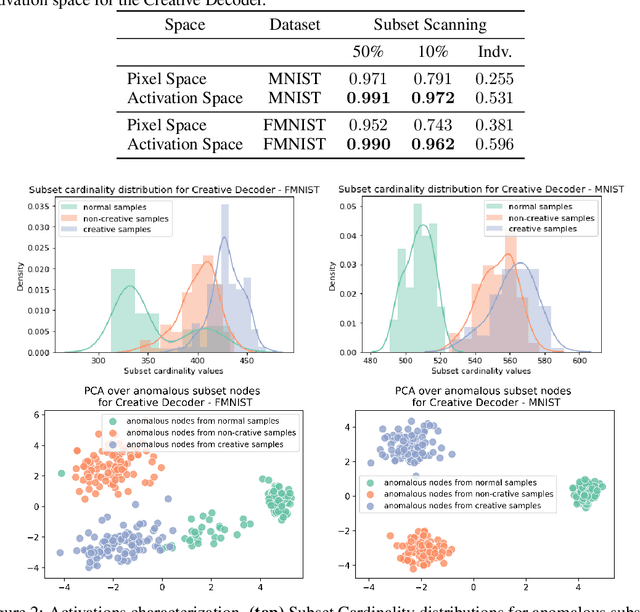
Deep generative models, such as Variational Autoencoders (VAEs), have been employed widely in computational creativity research. However, such models discourage out-of-distribution generation to avoid spurious sample generation, limiting their creativity. Thus, incorporating research on human creativity into generative deep learning techniques presents an opportunity to make their outputs more compelling and human-like. As we see the emergence of generative models directed to creativity research, a need for machine learning-based surrogate metrics to characterize creative output from these models is imperative. We propose group-based subset scanning to quantify, detect, and characterize creative processes by detecting a subset of anomalous node-activations in the hidden layers of generative models. Our experiments on original, typically decoded, and "creatively decoded" (Das et al 2020) image datasets reveal that the proposed subset scores distribution is more useful for detecting creative processes in the activation space rather than the pixel space. Further, we found that creative samples generate larger subsets of anomalies than normal or non-creative samples across datasets. The node activations highlighted during the creative decoding process are different from those responsible for normal sample generation.
Prediction of neonatal mortality in Sub-Saharan African countries using data-level linkage of multiple surveys
Nov 25, 2020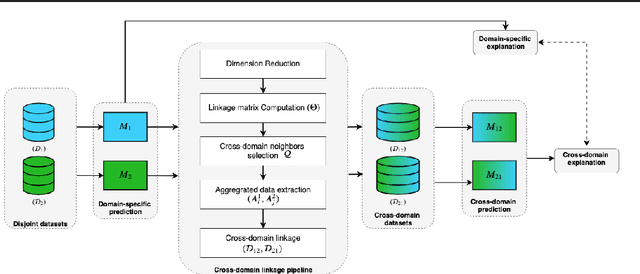
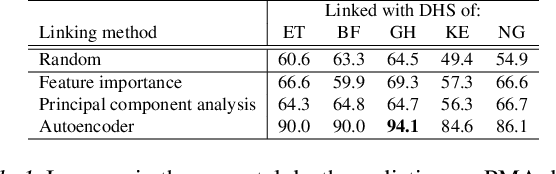
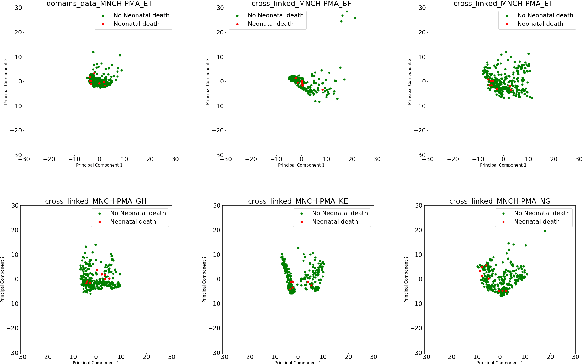
Existing datasets available to address crucial problems, such as child mortality and family planning discontinuation in developing countries, are not ample for data-driven approaches. This is partly due to disjoint data collection efforts employed across locations, times, and variations of modalities. On the other hand, state-of-the-art methods for small data problem are confined to image modalities. In this work, we proposed a data-level linkage of disjoint surveys across Sub-Saharan African countries to improve prediction performance of neonatal death and provide cross-domain explainability.
Identifying Audio Adversarial Examples via Anomalous Pattern Detection
Feb 13, 2020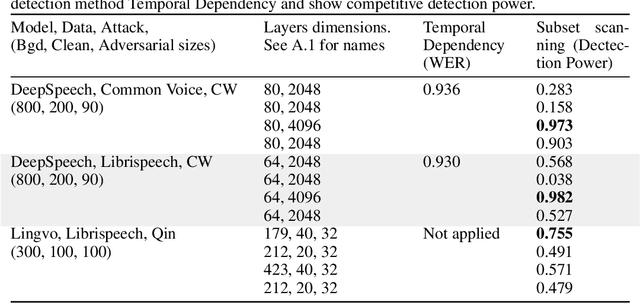
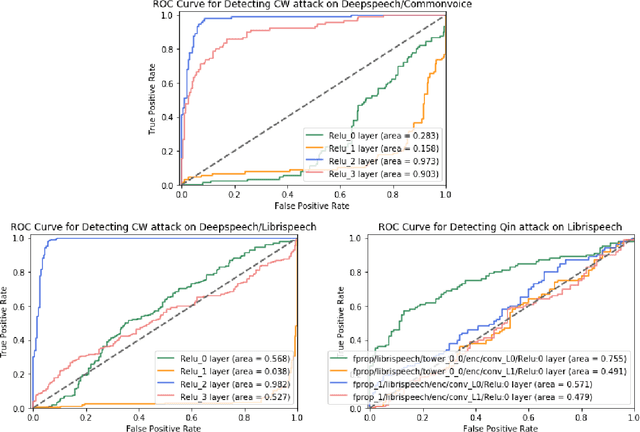
Audio processing models based on deep neural networks are susceptible to adversarial attacks even when the adversarial audio waveform is 99.9% similar to a benign sample. Given the wide application of DNN-based audio recognition systems, detecting the presence of adversarial examples is of high practical relevance. By applying anomalous pattern detection techniques in the activation space of these models, we show that 2 of the recent and current state-of-the-art adversarial attacks on audio processing systems systematically lead to higher-than-expected activation at some subset of nodes and we can detect these with up to an AUC of 0.98 with no degradation in performance on benign samples.
Analyzing Bias in Sensitive Personal Information Used to Train Financial Models
Nov 09, 2019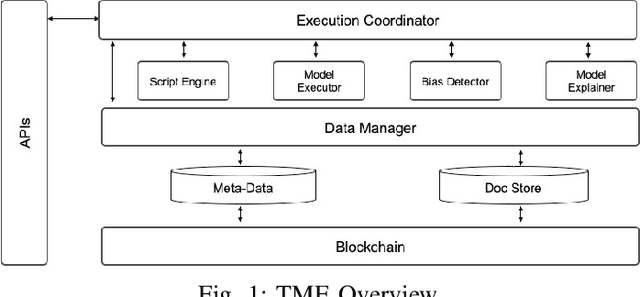
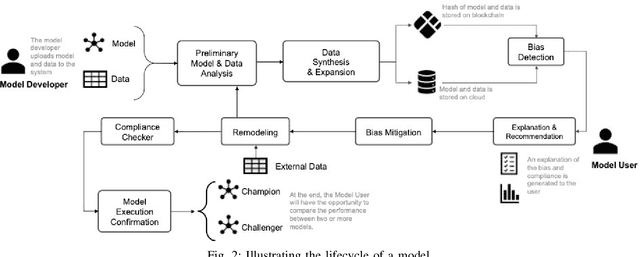
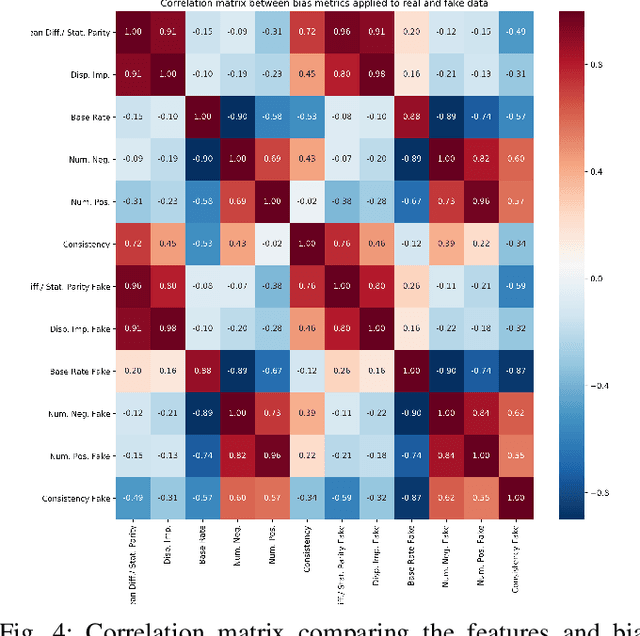
Bias in data can have unintended consequences that propagate to the design, development, and deployment of machine learning models. In the financial services sector, this can result in discrimination from certain financial instruments and services. At the same time, data privacy is of paramount importance, and recent data breaches have seen reputational damage for large institutions. Presented in this paper is a trusted model-lifecycle management platform that attempts to ensure consumer data protection, anonymization, and fairness. Specifically, we examine how datasets can be reproduced using deep learning techniques to effectively retain important statistical features in datasets whilst simultaneously protecting data privacy and enabling safe and secure sharing of sensitive personal information beyond the current state-of-practice.
Estimating Skin Tone and Effects on Classification Performance in Dermatology Datasets
Oct 29, 2019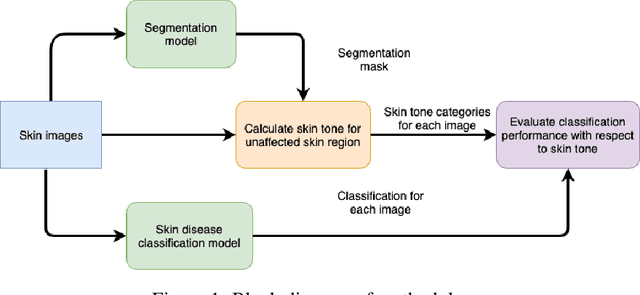
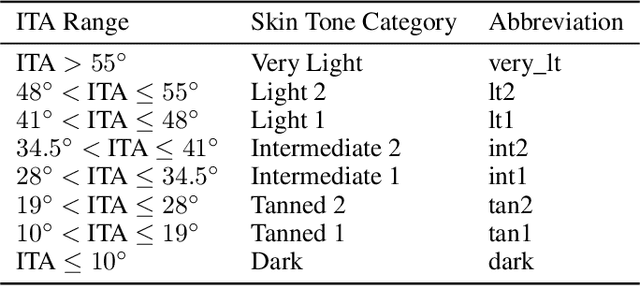
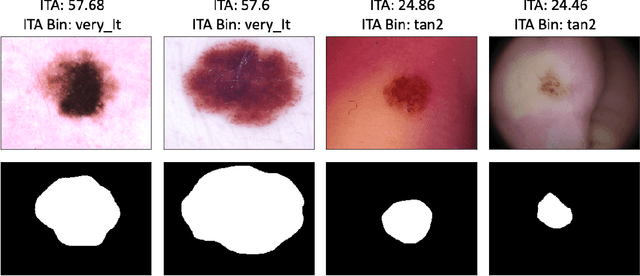

Recent advances in computer vision and deep learning have led to breakthroughs in the development of automated skin image analysis. In particular, skin cancer classification models have achieved performance higher than trained expert dermatologists. However, no attempt has been made to evaluate the consistency in performance of machine learning models across populations with varying skin tones. In this paper, we present an approach to estimate skin tone in benchmark skin disease datasets, and investigate whether model performance is dependent on this measure. Specifically, we use individual typology angle (ITA) to approximate skin tone in dermatology datasets. We look at the distribution of ITA values to better understand skin color representation in two benchmark datasets: 1) the ISIC 2018 Challenge dataset, a collection of dermoscopic images of skin lesions for the detection of skin cancer, and 2) the SD-198 dataset, a collection of clinical images capturing a wide variety of skin diseases. To estimate ITA, we first develop segmentation models to isolate non-diseased areas of skin. We find that the majority of the data in the the two datasets have ITA values between 34.5{\deg} and 48{\deg}, which are associated with lighter skin, and is consistent with under-representation of darker skinned populations in these datasets. We also find no measurable correlation between performance of machine learning model and ITA values, though more comprehensive data is needed for further validation.
Smooth Grad-CAM++: An Enhanced Inference Level Visualization Technique for Deep Convolutional Neural Network Models
Aug 03, 2019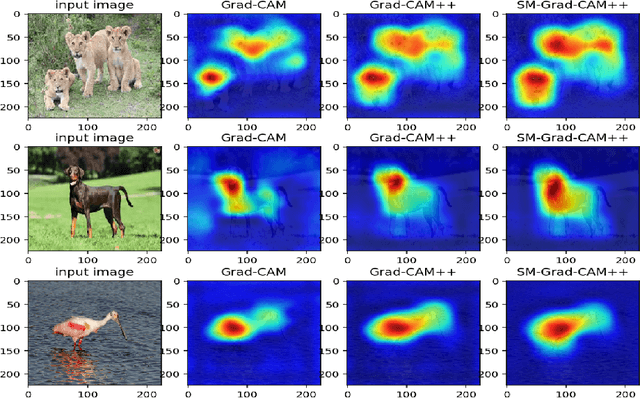
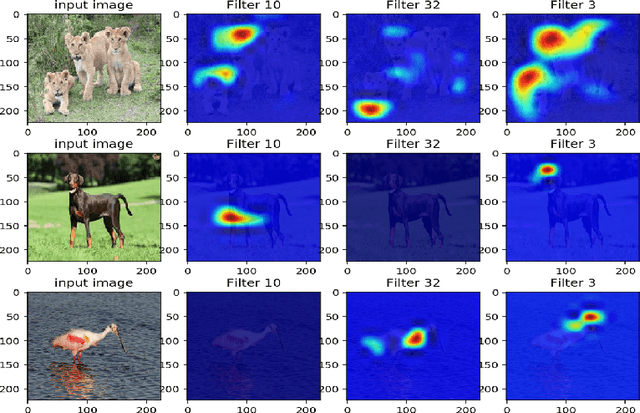
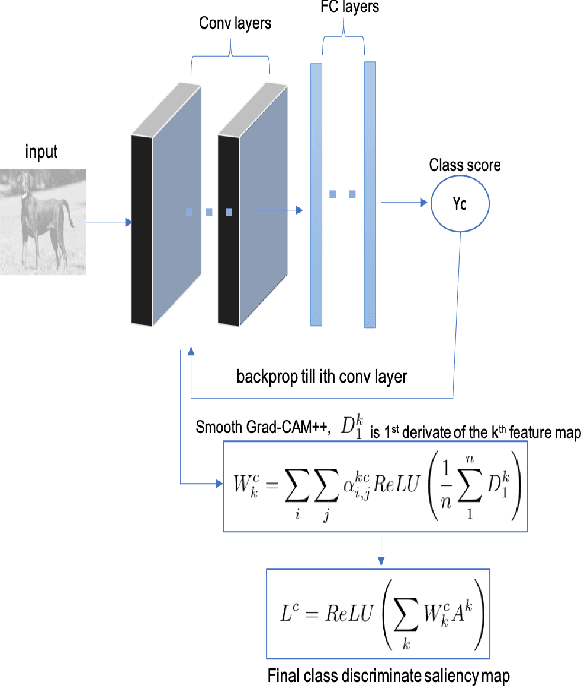
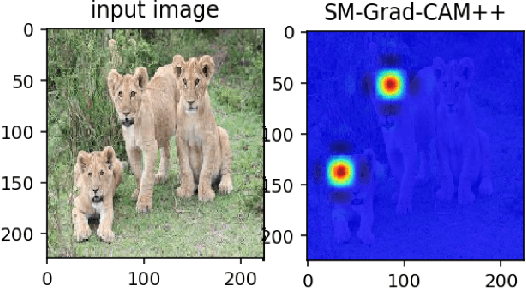
Gaining insight into how deep convolutional neural network models perform image classification and how to explain their outputs have been a concern to computer vision researchers and decision makers. These deep models are often referred to as black box due to low comprehension of their internal workings. As an effort to developing explainable deep learning models, several methods have been proposed such as finding gradients of class output with respect to input image (sensitivity maps), class activation map (CAM), and Gradient based Class Activation Maps (Grad-CAM). These methods under perform when localizing multiple occurrences of the same class and do not work for all CNNs. In addition, Grad-CAM does not capture the entire object in completeness when used on single object images, this affect performance on recognition tasks. With the intention to create an enhanced visual explanation in terms of visual sharpness, object localization and explaining multiple occurrences of objects in a single image, we present Smooth Grad-CAM++ \footnote{Simple demo: http://35.238.22.135:5000/}, a technique that combines methods from two other recent techniques---SMOOTHGRAD and Grad-CAM++. Our Smooth Grad-CAM++ technique provides the capability of either visualizing a layer, subset of feature maps, or subset of neurons within a feature map at each instance at the inference level (model prediction process). After experimenting with few images, Smooth Grad-CAM++ produced more visually sharp maps with better localization of objects in the given input images when compared with other methods.