 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-device Federated Learning for Mobile Health Diagnostics: A First Study on COVID-19 Detection
Mar 13, 2023



Federated learning (FL) aided health diagnostic models can incorporate data from a large number of personal edge devices (e.g., mobile phones) while keeping the data local to the originating devices, largely ensuring privacy. However, such a cross-device FL approach for health diagnostics still imposes many challenges due to both local data imbalance (as extreme as local data consists of a single disease class) and global data imbalance (the disease prevalence is generally low in a population). Since the federated server has no access to data distribution information, it is not trivial to solve the imbalance issue towards an unbiased model. In this paper, we propose FedLoss, a novel cross-device FL framework for health diagnostics. Here the federated server averages the models trained on edge devices according to the predictive loss on the local data, rather than using only the number of samples as weights. As the predictive loss better quantifies the data distribution at a device, FedLoss alleviates the impact of data imbalance. Through a real-world dataset on respiratory sound and symptom-based COVID-$19$ detection task, we validate the superiority of FedLoss. It achieves competitive COVID-$19$ detection performance compared to a centralised model with an AUC-ROC of $79\%$. It also outperforms the state-of-the-art FL baselines in sensitivity and convergence speed. Our work not only demonstrates the promise of federated COVID-$19$ detection but also paves the way to a plethora of mobile health model development in a privacy-preserving fashion.
Turning Silver into Gold: Domain Adaptation with Noisy Labels for Wearable Cardio-Respiratory Fitness Prediction
Nov 20, 2022Deep learning models have shown great promise in various healthcare applications. However, most models are developed and validated on small-scale datasets, as collecting high-quality (gold-standard) labels for health applications is often costly and time-consuming. As a result, these models may suffer from overfitting and not generalize well to unseen data. At the same time, an extensive amount of data with imprecise labels (silver-standard) is starting to be generally available, as collected from inexpensive wearables like accelerometers and electrocardiography sensors. These currently underutilized datasets and labels can be leveraged to produce more accurate clinical models. In this work, we propose UDAMA, a novel model with two key components: Unsupervised Domain Adaptation and Multi-discriminator Adversarial training, which leverage noisy data from source domain (the silver-standard dataset) to improve gold-standard modeling. We validate our framework on the challenging task of predicting lab-measured maximal oxygen consumption (VO$_{2}$max), the benchmark metric of cardio-respiratory fitness, using free-living wearable sensor data from two cohort studies as inputs. Our experiments show that the proposed framework achieves the best performance of corr = 0.665 $\pm$ 0.04, paving the way for accurate fitness estimation at scale.
Longitudinal cardio-respiratory fitness prediction through free-living wearable sensors
May 06, 2022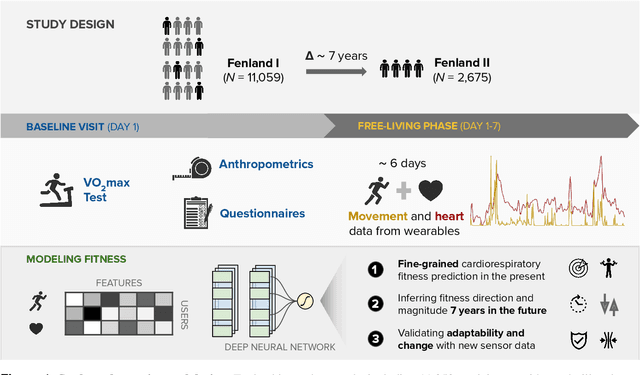
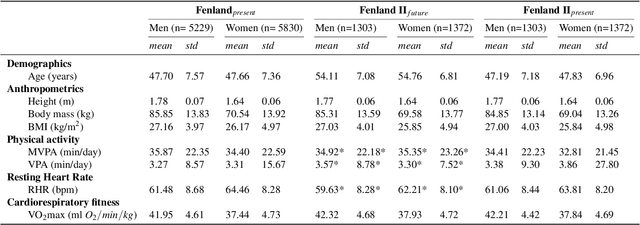
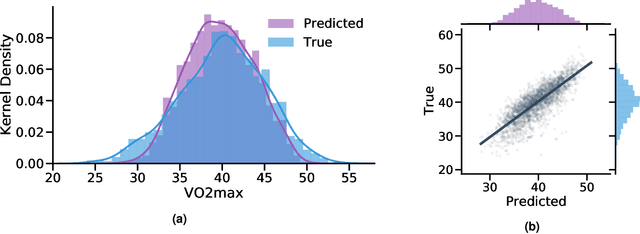
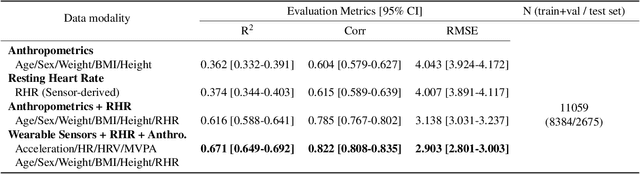
Cardiorespiratory fitness is an established predictor of metabolic disease and mortality. Fitness is directly measured as maximal oxygen consumption (VO2max), or indirectly assessed using heart rate response to a standard exercise test. However, such testing is costly and burdensome, limiting its utility and scalability. Fitness can also be approximated using resting heart rate and self-reported exercise habits but with lower accuracy. Modern wearables capture dynamic heart rate data which, in combination with machine learning models, could improve fitness prediction. In this work, we analyze movement and heart rate signals from wearable sensors in free-living conditions from 11,059 participants who also underwent a standard exercise test, along with a longitudinal repeat cohort of 2,675 participants. We design algorithms and models that convert raw sensor data into cardio-respiratory fitness estimates, and validate these estimates' ability to capture fitness profiles in a longitudinal cohort over time while subjects engaged in real-world (non-exercise) behaviour. Additionally, we validate our methods with a third external cohort of 181 participants who underwent maximal VO2max testing, which is considered the gold standard measurement because it requires reaching one's maximum heart rate and exhaustion level. Our results show that the developed models yield a high correlation (r = 0.82, 95CI 0.80-0.83), when compared to the ground truth in a holdout sample. These models outperform conventional non-exercise fitness models and traditional bio-markers using measurements of normal daily living without the need for a specific exercise test. Additionally, we show the adaptability and applicability of this approach for detecting fitness change over time in the longitudinal subsample that repeated measurements after 7 years.
Improving Feature Generalizability with Multitask Learning in Class Incremental Learning
Apr 26, 2022
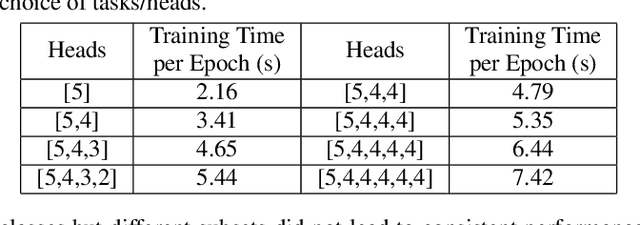
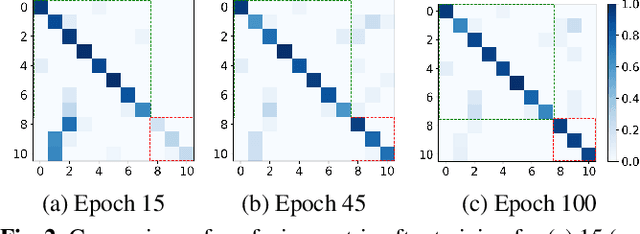
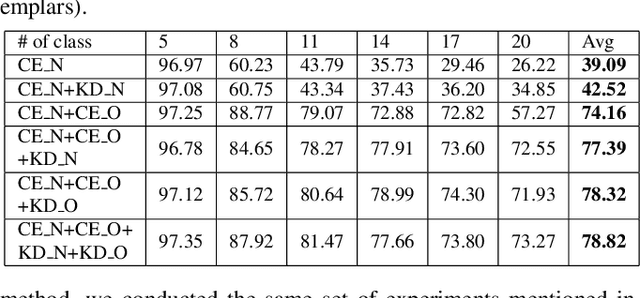
Many deep learning applications, like keyword spotting, require the incorporation of new concepts (classes) over time, referred to as Class Incremental Learning (CIL). The major challenge in CIL is catastrophic forgetting, i.e., preserving as much of the old knowledge as possible while learning new tasks. Various techniques, such as regularization, knowledge distillation, and the use of exemplars, have been proposed to resolve this issue. However, prior works primarily focus on the incremental learning step, while ignoring the optimization during the base model training. We hypothesize that a more transferable and generalizable feature representation from the base model would be beneficial to incremental learning. In this work, we adopt multitask learning during base model training to improve the feature generalizability. Specifically, instead of training a single model with all the base classes, we decompose the base classes into multiple subsets and regard each of them as a task. These tasks are trained concurrently and a shared feature extractor is obtained for incremental learning. We evaluate our approach on two datasets under various configurations. The results show that our approach enhances the average incremental learning accuracy by up to 5.5%, which enables more reliable and accurate keyword spotting over time. Moreover, the proposed approach can be combined with many existing techniques and provides additional performance gain.
YONO: Modeling Multiple Heterogeneous Neural Networks on Microcontrollers
Mar 08, 2022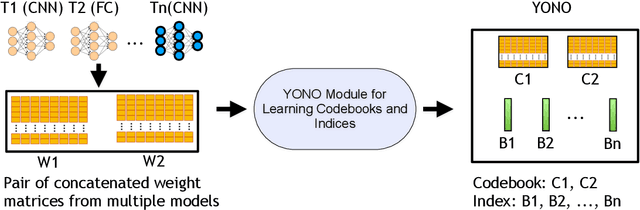
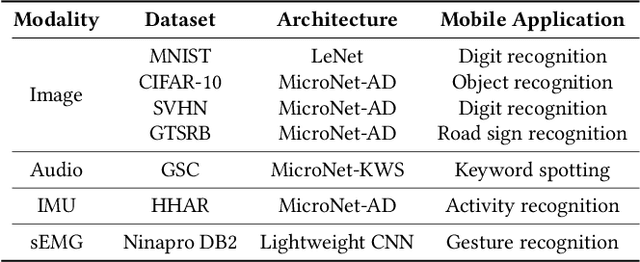
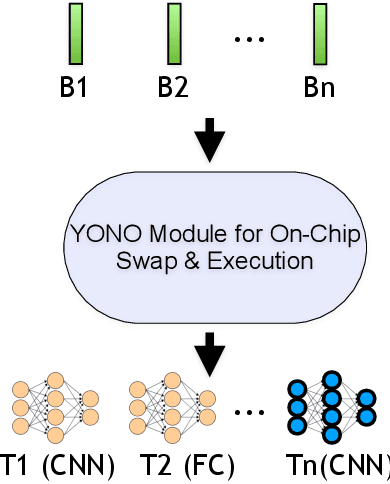

With the advancement of Deep Neural Networks (DNN) and large amounts of sensor data from Internet of Things (IoT) systems, the research community has worked to reduce the computational and resource demands of DNN to compute on low-resourced microcontrollers (MCUs). However, most of the current work in embedded deep learning focuses on solving a single task efficiently, while the multi-tasking nature and applications of IoT devices demand systems that can handle a diverse range of tasks (activity, voice, and context recognition) with input from a variety of sensors, simultaneously. In this paper, we propose YONO, a product quantization (PQ) based approach that compresses multiple heterogeneous models and enables in-memory model execution and switching for dissimilar multi-task learning on MCUs. We first adopt PQ to learn codebooks that store weights of different models. Also, we propose a novel network optimization and heuristics to maximize the compression rate and minimize the accuracy loss. Then, we develop an online component of YONO for efficient model execution and switching between multiple tasks on an MCU at run time without relying on an external storage device. YONO shows remarkable performance as it can compress multiple heterogeneous models with negligible or no loss of accuracy up to 12.37$\times$. Besides, YONO's online component enables an efficient execution (latency of 16-159 ms per operation) and reduces model loading/switching latency and energy consumption by 93.3-94.5% and 93.9-95.0%, respectively, compared to external storage access. Interestingly, YONO can compress various architectures trained with datasets that were not shown during YONO's offline codebook learning phase showing the generalizability of our method. To summarize, YONO shows great potential and opens further doors to enable multi-task learning systems on extremely resource-constrained devices.
Enabling On-Device Smartphone GPU based Training: Lessons Learned
Feb 21, 2022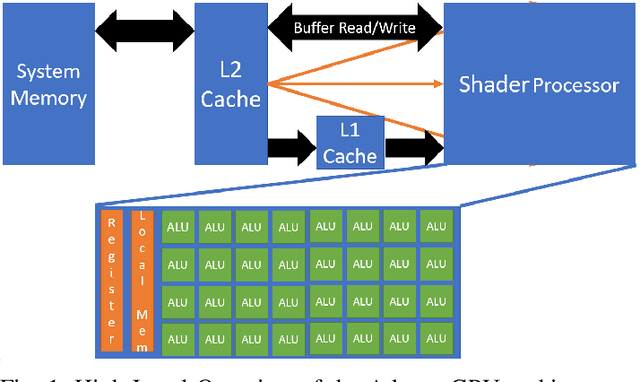
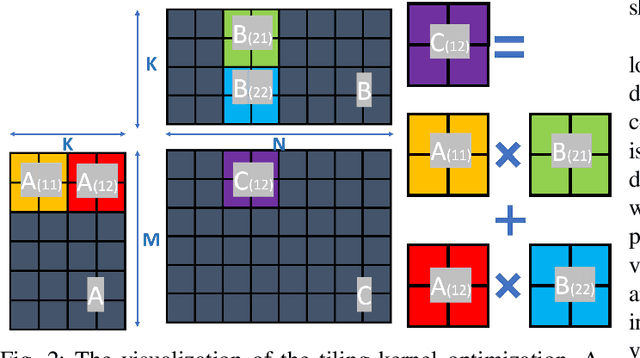
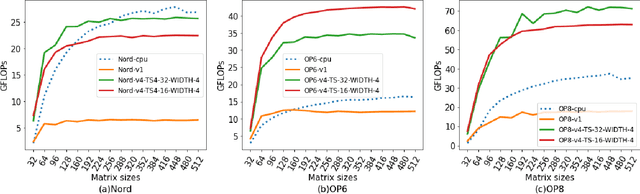
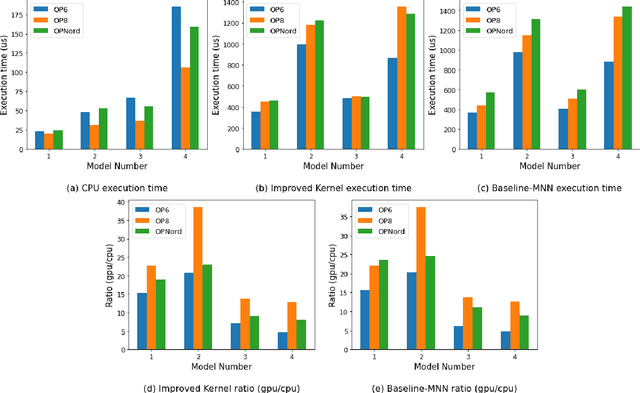
Deep Learning (DL) has shown impressive performance in many mobile applications. Most existing works have focused on reducing the computational and resource overheads of running Deep Neural Networks (DNN) inference on resource-constrained mobile devices. However, the other aspect of DNN operations, i.e. training (forward and backward passes) on smartphone GPUs, has received little attention thus far. To this end, we conduct an initial analysis to examine the feasibility of on-device training on smartphones using mobile GPUs. We first employ the open-source mobile DL framework (MNN) and its OpenCL backend for running compute kernels on GPUs. Next, we observed that training on CPUs is much faster than on GPUs and identified two possible bottlenecks related to this observation: (i) computation and (ii) memory bottlenecks. To solve the computation bottleneck, we optimize the OpenCL backend's kernels, showing 2x improvements (40-70 GFLOPs) over CPUs (15-30 GFLOPs) on the Snapdragon 8 series processors. However, we find that the full DNN training is still much slower on GPUs than on CPUs, indicating that memory bottleneck plays a significant role in the lower performance of GPU over CPU. The data movement takes almost 91% of training time due to the low bandwidth. Lastly, based on the findings and failures during our investigation, we present limitations and practical guidelines for future directions.
A Summary of the ComParE COVID-19 Challenges
Feb 17, 2022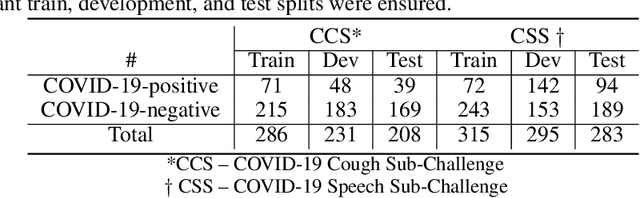
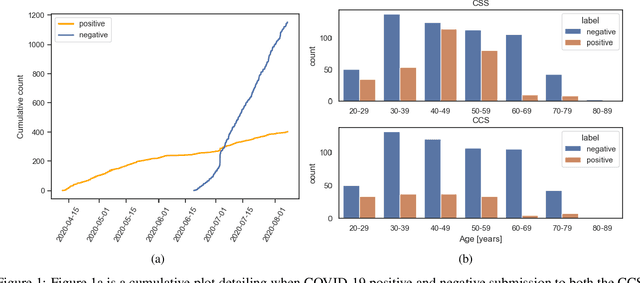
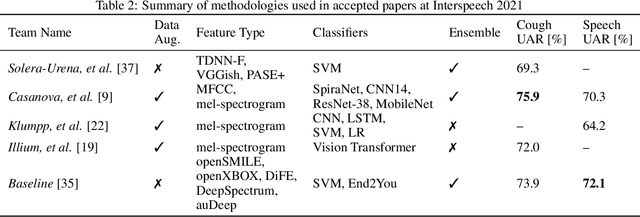
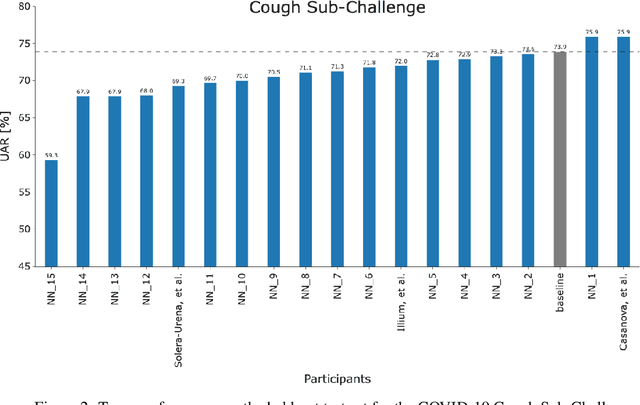
The COVID-19 pandemic has caused massive humanitarian and economic damage. Teams of scientists from a broad range of disciplines have searched for methods to help governments and communities combat the disease. One avenue from the machine learning field which has been explored is the prospect of a digital mass test which can detect COVID-19 from infected individuals' respiratory sounds. We present a summary of the results from the INTERSPEECH 2021 Computational Paralinguistics Challenges: COVID-19 Cough, (CCS) and COVID-19 Speech, (CSS).
Benchmarking Uncertainty Quantification on Biosignal Classification Tasks under Dataset Shift
Jan 25, 2022
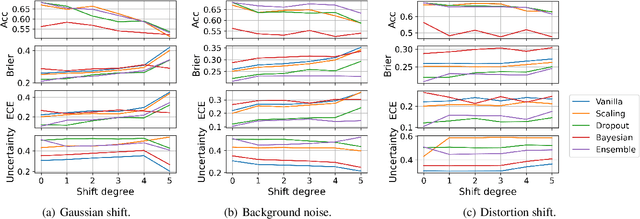
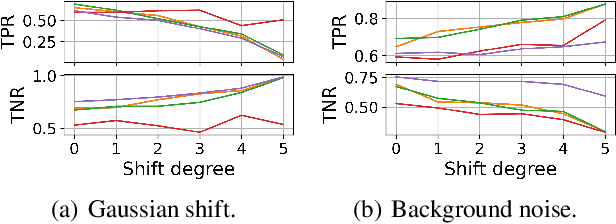
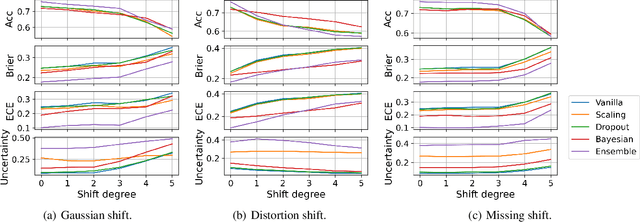
A biosignal is a signal that can be continuously measured from human bodies, such as respiratory sounds, heart activity (ECG), brain waves (EEG), etc, based on which, machine learning models have been developed with very promising performance for automatic disease detection and health status monitoring. However, dataset shift, i.e., data distribution of inference varies from the distribution of the training, is not uncommon for real biosignal-based applications. To improve the robustness, probabilistic models with uncertainty quantification are adapted to capture how reliable a prediction is. Yet, assessing the quality of the estimated uncertainty remains a challenge. In this work, we propose a framework to evaluate the capability of the estimated uncertainty in capturing different types of biosignal dataset shifts with various degrees. In particular, we use three classification tasks based on respiratory sounds and electrocardiography signals to benchmark five representative uncertainty quantification methods. Extensive experiments show that, although Ensemble and Bayesian models could provide relatively better uncertainty estimations under dataset shifts, all tested models fail to meet the promise in trustworthy prediction and model calibration. Our work paves the way for a comprehensive evaluation for any newly developed biosignal classifiers.
Enhancing the Security & Privacy of Wearable Brain-Computer Interfaces
Jan 19, 2022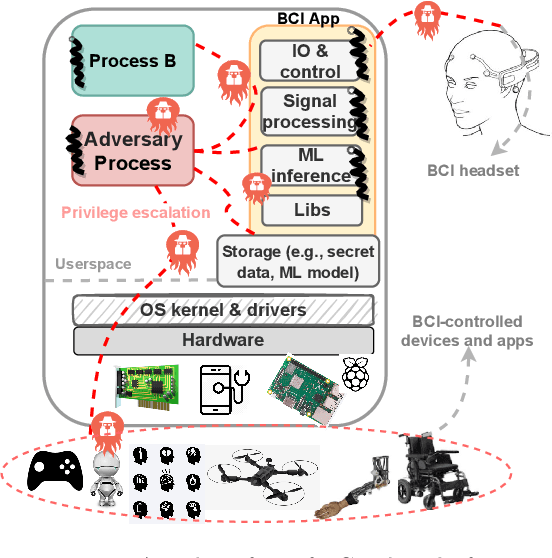

Brain computing interfaces (BCI) are used in a plethora of safety/privacy-critical applications, ranging from healthcare to smart communication and control. Wearable BCI setups typically involve a head-mounted sensor connected to a mobile device, combined with ML-based data processing. Consequently, they are susceptible to a multiplicity of attacks across the hardware, software, and networking stacks used that can leak users' brainwave data or at worst relinquish control of BCI-assisted devices to remote attackers. In this paper, we: (i) analyse the whole-system security and privacy threats to existing wearable BCI products from an operating system and adversarial machine learning perspective; and (ii) introduce Argus, the first information flow control system for wearable BCI applications that mitigates these attacks. Argus' domain-specific design leads to a lightweight implementation on Linux ARM platforms suitable for existing BCI use-cases. Our proof of concept attacks on real-world BCI devices (Muse, NeuroSky, and OpenBCI) led us to discover more than 300 vulnerabilities across the stacks of six major attack vectors. Our evaluation shows Argus is highly effective in tracking sensitive dataflows and restricting these attacks with an acceptable memory and performance overhead (<15%).
COVID-19 Disease Progression Prediction via Audio Signals: A Longitudinal Study
Jan 04, 2022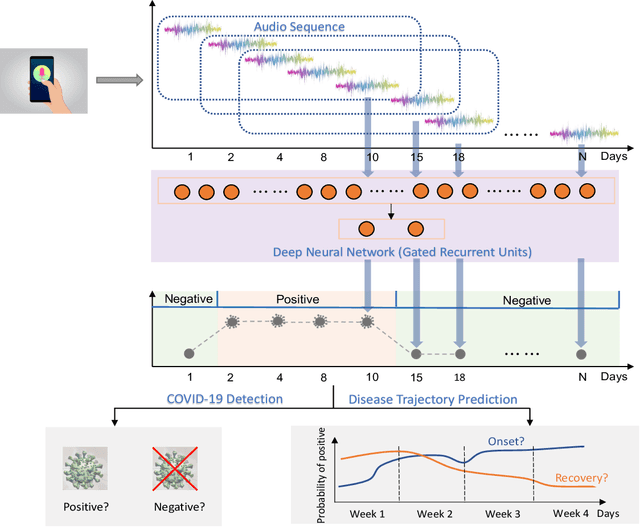
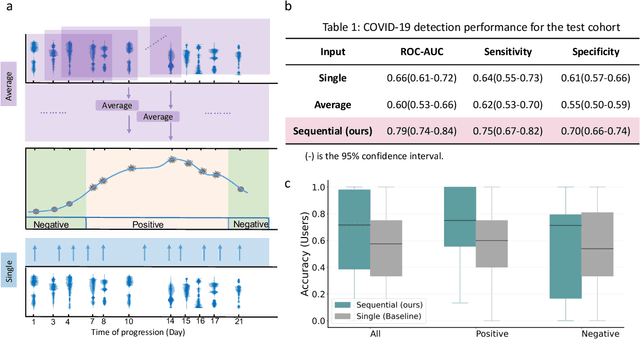
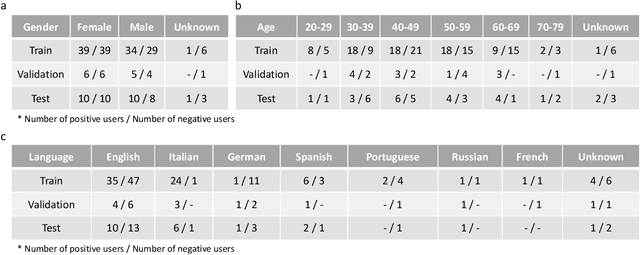
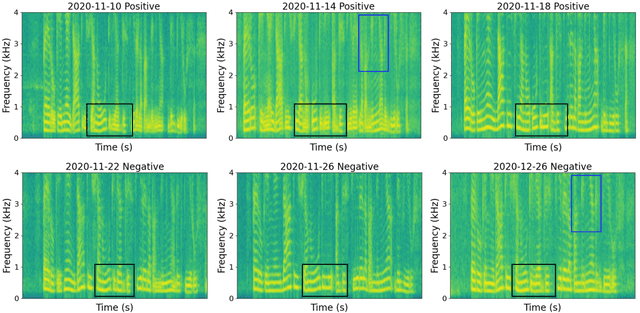
Recent work has shown the potential of the use of audio data in screening for COVID-19. However, very little exploration has been done of monitoring disease progression, especially recovery in COVID-19 through audio. Tracking disease progression characteristics and patterns of recovery could lead to tremendous insights and more timely treatment or treatment adjustment, as well as better resources management in health care systems. The primary objective of this study is to explore the potential of longitudinal audio dynamics for COVID-19 monitoring using sequential deep learning techniques, focusing on prediction of disease progression and, especially, recovery trend prediction. We analysed crowdsourced respiratory audio data from 212 individuals over 5 days to 385 days, alongside their self-reported COVID-19 test results. We first explore the benefits of capturing longitudinal dynamics of audio biomarkers for COVID-19 detection. The strong performance, yielding an AUC-ROC of 0.79, sensitivity of 0.75 and specificity of 0.70, supports the effectiveness of the approach compared to methods that do not leverage longitudinal dynamics. We further examine the predicted disease progression trajectory, which displays high consistency with the longitudinal test results with a correlation of 0.76 in the test cohort, and 0.86 in a subset of the test cohort with 12 participants who report disease recovery. Our findings suggest that monitoring COVID-19 progression via longitudinal audio data has enormous potential in the tracking of individuals' disease progression and recovery.