 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScheduling with Uncertain Holding Costs and its Application to Content Moderation
May 27, 2025



In content moderation for social media platforms, the cost of delaying the review of a content is proportional to its view trajectory, which fluctuates and is apriori unknown. Motivated by such uncertain holding costs, we consider a queueing model where job states evolve based on a Markov chain with state-dependent instantaneous holding costs. We demonstrate that in the presence of such uncertain holding costs, the two canonical algorithmic principles, instantaneous-cost ($c\mu$-rule) and expected-remaining-cost ($c\mu/\theta$-rule), are suboptimal. By viewing each job as a Markovian ski-rental problem, we develop a new index-based algorithm, Opportunity-adjusted Remaining Cost (OaRC), that adjusts to the opportunity of serving jobs in the future when uncertainty partly resolves. We show that the regret of OaRC scales as $\tilde{O}(L^{1.5}\sqrt{N})$, where $L$ is the maximum length of a job's holding cost trajectory and $N$ is the system size. This regret bound shows that OaRC achieves asymptotic optimality when the system size $N$ scales to infinity. Moreover, its regret is independent of the state-space size, which is a desirable property when job states contain contextual information. We corroborate our results with an extensive simulation study based on two holding cost patterns (online ads and user-generated content) that arise in content moderation for social media platforms. Our simulations based on synthetic and real datasets demonstrate that OaRC consistently outperforms existing practice, which is based on the two canonical algorithmic principles.
Bandits for Online Calibration: An Application to Content Moderation on Social Media Platforms
Nov 11, 2022


We describe the current content moderation strategy employed by Meta to remove policy-violating content from its platforms. Meta relies on both handcrafted and learned risk models to flag potentially violating content for human review. Our approach aggregates these risk models into a single ranking score, calibrating them to prioritize more reliable risk models. A key challenge is that violation trends change over time, affecting which risk models are most reliable. Our system additionally handles production challenges such as changing risk models and novel risk models. We use a contextual bandit to update the calibration in response to such trends. Our approach increases Meta's top-line metric for measuring the effectiveness of its content moderation strategy by 13%.
QUEST: Queue Simulation for Content Moderation at Scale
Mar 31, 2021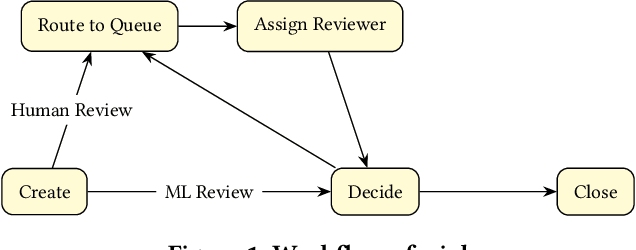
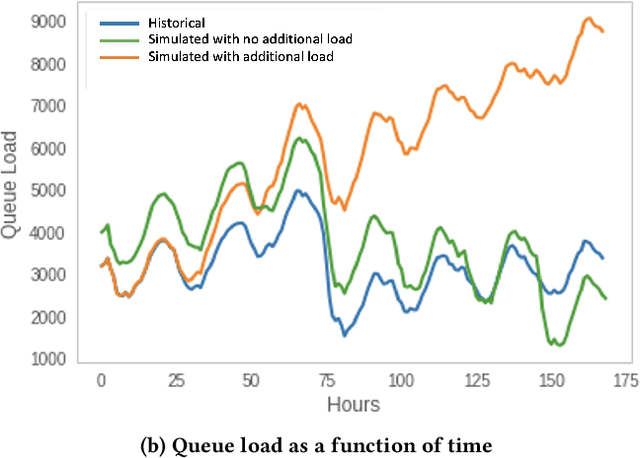
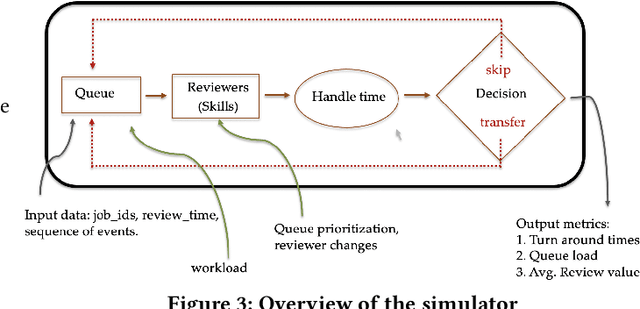
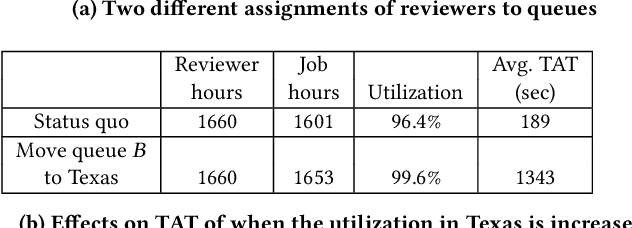
Moderating content in social media platforms is a formidable challenge due to the unprecedented scale of such systems, which typically handle billions of posts per day. Some of the largest platforms such as Facebook blend machine learning with manual review of platform content by thousands of reviewers. Operating a large-scale human review system poses interesting and challenging methodological questions that can be addressed with operations research techniques. We investigate the problem of optimally operating such a review system at scale using ideas from queueing theory and simulation.