 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Cost Transfer Learning of Face Tasks
Jan 09, 2019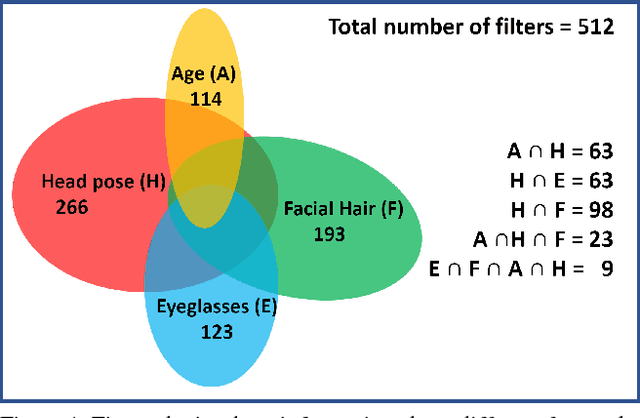
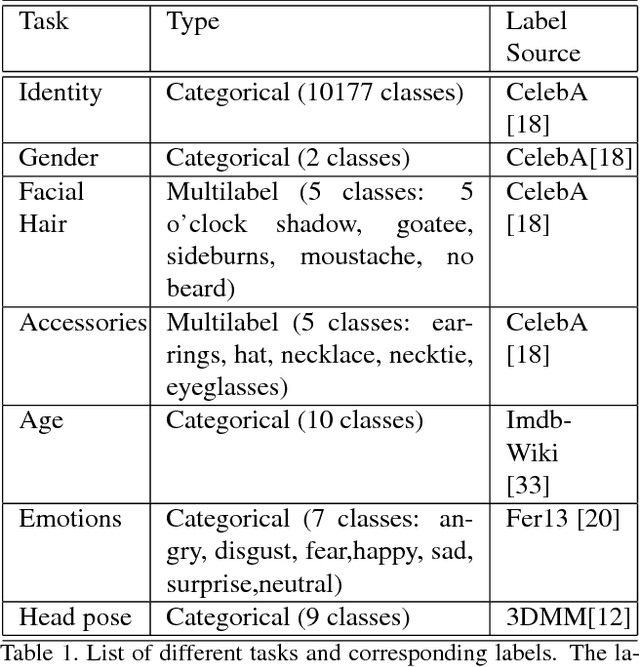
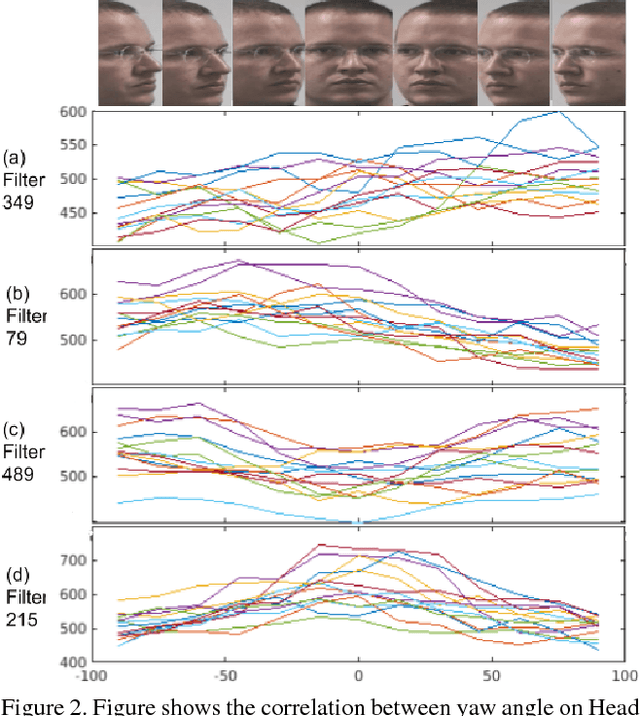

Do we know what the different filters of a face network represent? Can we use this filter information to train other tasks without transfer learning? For instance, can age, head pose, emotion and other face related tasks be learned from face recognition network without transfer learning? Understanding the role of these filters allows us to transfer knowledge across tasks and take advantage of large data sets in related tasks. Given a pretrained network, we can infer which tasks the network generalizes for and the best way to transfer the information to a new task.
City-Scale Road Audit System using Deep Learning
Nov 26, 2018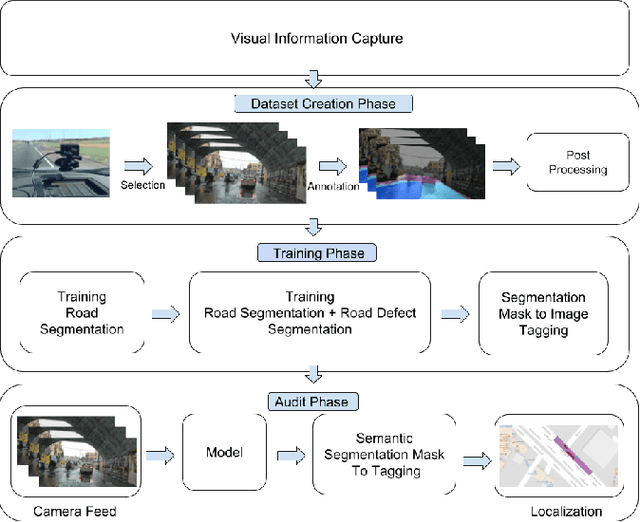
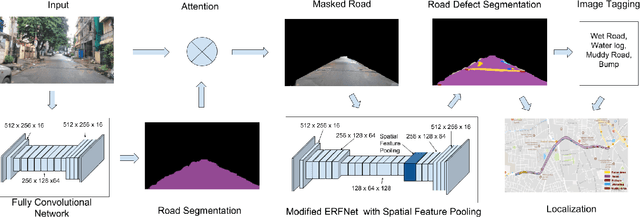

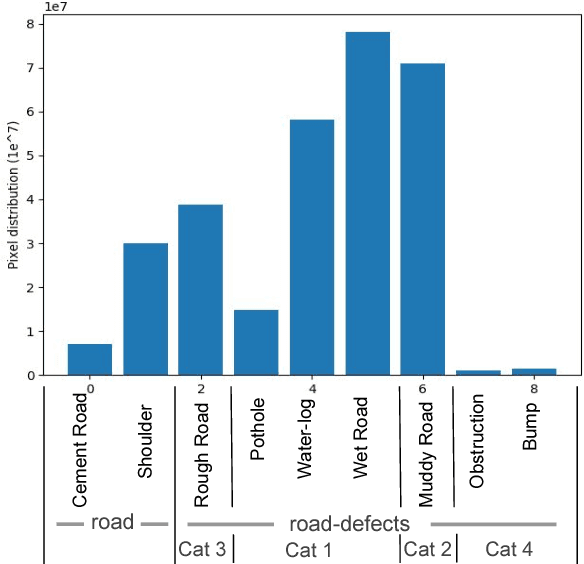
Road networks in cities are massive and is a critical component of mobility. Fast response to defects, that can occur not only due to regular wear and tear but also because of extreme events like storms, is essential. Hence there is a need for an automated system that is quick, scalable and cost-effective for gathering information about defects. We propose a system for city-scale road audit, using some of the most recent developments in deep learning and semantic segmentation. For building and benchmarking the system, we curated a dataset which has annotations required for road defects. However, many of the labels required for road audit have high ambiguity which we overcome by proposing a label hierarchy. We also propose a multi-step deep learning model that segments the road, subdivide the road further into defects, tags the frame for each defect and finally localizes the defects on a map gathered using GPS. We analyze and evaluate the models on image tagging as well as segmentation at different levels of the label hierarchy.
Dissimilarity Coefficient based Weakly Supervised Object Detection
Nov 25, 2018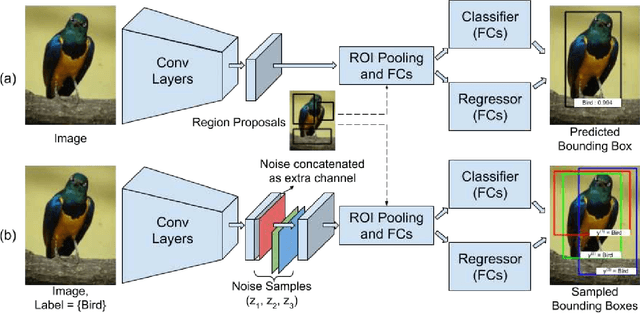
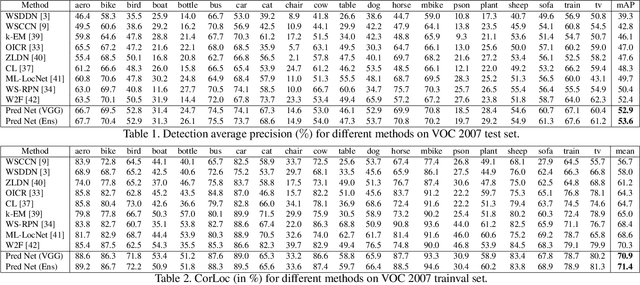

We consider the problem of weakly supervised object detection, where the training samples are annotated using only image-level labels that indicate the presence or absence of an object category. In order to model the uncertainty in the location of the objects, we employ a dissimilarity coefficient based probabilistic learning objective. The learning objective minimizes the difference between an annotation agnostic prediction distribution and an annotation aware conditional distribution. The main computational challenge is the complex nature of the conditional distribution, which consists of terms over hundreds or thousands of variables. The complexity of the conditional distribution rules out the possibility of explicitly modeling it. Instead, we exploit the fact that deep learning frameworks rely on stochastic optimization. This allows us to use a state of the art discrete generative model that can provide annotation consistent samples from the conditional distribution. Extensive experiments on PASCAL VOC 2007 and 2012 data sets demonstrate the efficacy of our proposed approach.
Improved Visual Relocalization by Discovering Anchor Points
Nov 11, 2018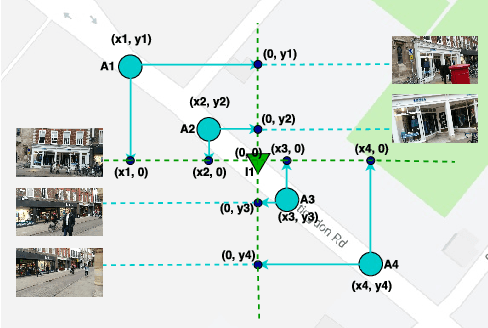
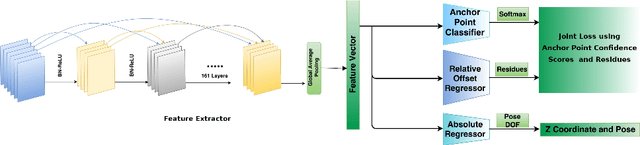
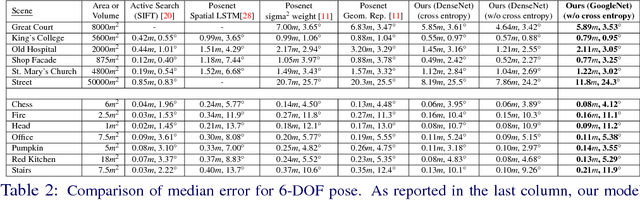
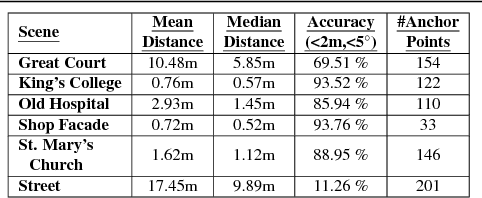
We address the visual relocalization problem of predicting the location and camera orientation or pose (6DOF) of the given input scene. We propose a method based on how humans determine their location using the visible landmarks. We define anchor points uniformly across the route map and propose a deep learning architecture which predicts the most relevant anchor point present in the scene as well as the relative offsets with respect to it. The relevant anchor point need not be the nearest anchor point to the ground truth location, as it might not be visible due to the pose. Hence we propose a multi task loss function, which discovers the relevant anchor point, without needing the ground truth for it. We validate the effectiveness of our approach by experimenting on CambridgeLandmarks (large scale outdoor scenes) as well as 7 Scenes (indoor scenes) using variousCNN feature extractors. Our method improves the median error in indoor as well as outdoor localization datasets compared to the previous best deep learning model known as PoseNet (with geometric re-projection loss) using the same feature extractor. We improve the median error in localization in the specific case of Street scene, by over 8m.
Class2Str: End to End Latent Hierarchy Learning
Aug 20, 2018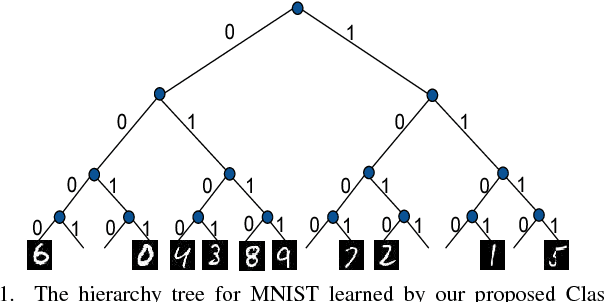
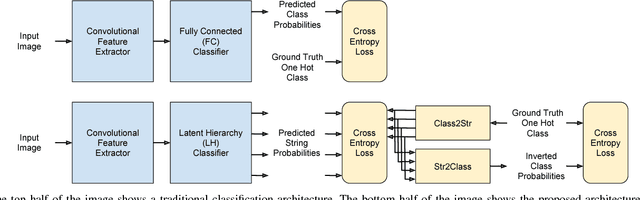
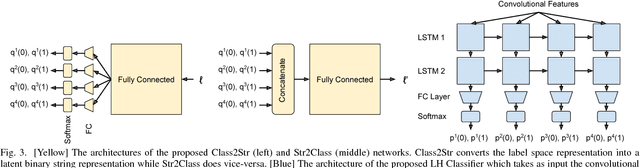
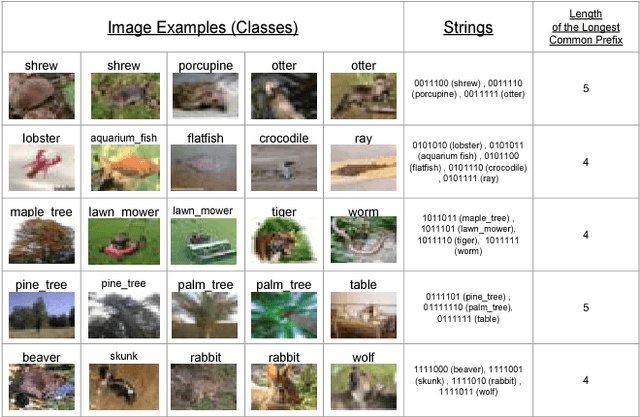
Deep neural networks for image classification typically consists of a convolutional feature extractor followed by a fully connected classifier network. The predicted and the ground truth labels are represented as one hot vectors. Such a representation assumes that all classes are equally dissimilar. However, classes have visual similarities and often form a hierarchy. Learning this latent hierarchy explicitly in the architecture could provide invaluable insights. We propose an alternate architecture to the classifier network called the Latent Hierarchy (LH) Classifier and an end to end learned Class2Str mapping which discovers a latent hierarchy of the classes. We show that for some of the best performing architectures on CIFAR and Imagenet datasets, the proposed replacement and training by LH classifier recovers the accuracy, with a fraction of the number of parameters in the classifier part. Compared to the previous work of HDCNN, which also learns a 2 level hierarchy, we are able to learn a hierarchy at an arbitrary number of levels as well as obtain an accuracy improvement on the Imagenet classification task over them. We also verify that many visually similar classes are grouped together, under the learnt hierarchy.
Connecting Visual Experiences using Max-flow Network with Application to Visual Localization
Aug 01, 2018

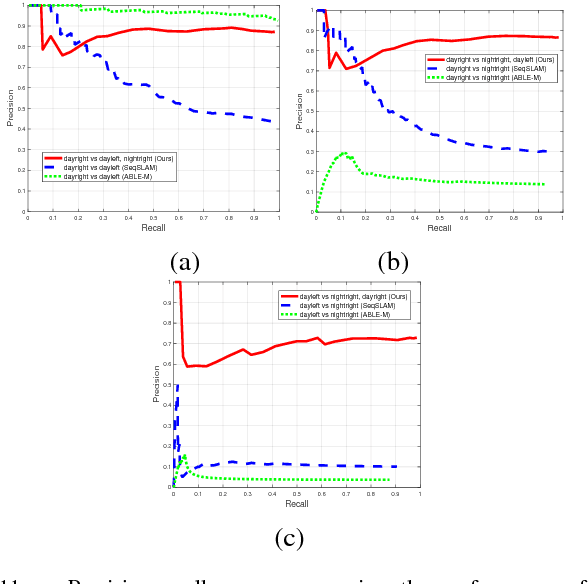
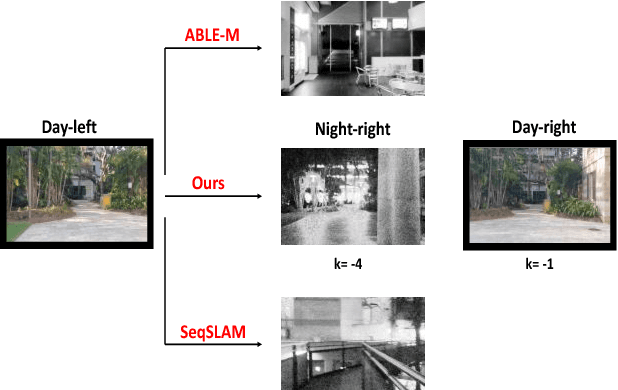
We are motivated by the fact that multiple representations of the environment are required to stand for the changes in appearance with time and for changes that appear in a cyclic manner. These changes are, for example, from day to night time, and from day to day across seasons. In such situations, the robot visits the same routes multiple times and collects different appearances of it. Multiple visual experiences usually find robotic vision applications like visual localization, mapping, place recognition, and autonomous navigation. The novelty in this paper is an algorithm that connects multiple visual experiences via aligning multiple image sequences. This problem is solved by finding the maximum flow in a directed graph flow-network, whose vertices represent the matches between frames in the test and reference sequences. Edges of the graph represent the cost of these matches. The problem of finding the best match is reduced to finding the minimum-cut surface, which is solved as a maximum flow network problem. Application to visual localization is considered in this paper to show the effectiveness of the proposed multiple image sequence alignment method, without loosing its generality. Experimental evaluations show that the precision of sequence matching is improved by considering multiple visual sequences for the same route, and that the method performs favorably against state-of-the-art single representation methods like SeqSLAM and ABLE-M.
Learning Human Poses from Actions
Jul 24, 2018
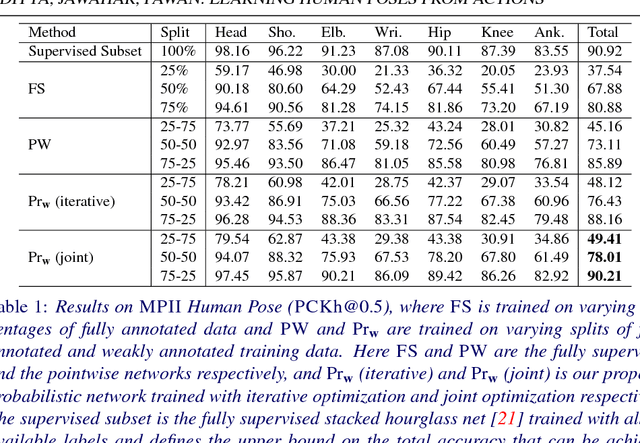
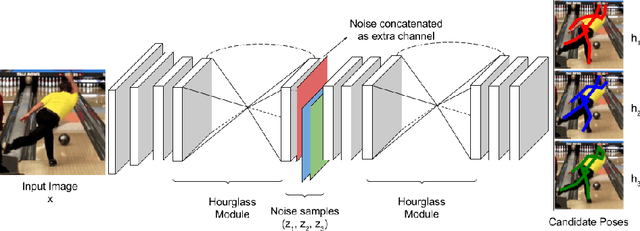
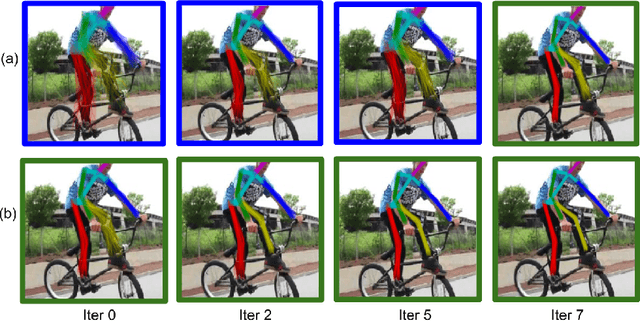
We consider the task of learning to estimate human pose in still images. In order to avoid the high cost of full supervision, we propose to use a diverse data set, which consists of two types of annotations: (i) a small number of images are labeled using the expensive ground-truth pose; and (ii) other images are labeled using the inexpensive action label. As action information helps narrow down the pose of a human, we argue that this approach can help reduce the cost of training without significantly affecting the accuracy. To demonstrate this we design a probabilistic framework that employs two distributions: (i) a conditional distribution to model the uncertainty over the human pose given the image and the action; and (ii) a prediction distribution, which provides the pose of an image without using any action information. We jointly estimate the parameters of the two aforementioned distributions by minimizing their dissimilarity coefficient, as measured by a task-specific loss function. During both training and testing, we only require an efficient sampling strategy for both the aforementioned distributions. This allows us to use deep probabilistic networks that are capable of providing accurate pose estimates for previously unseen images. Using the MPII data set, we show that our approach outperforms baseline methods that either do not use the diverse annotations or rely on pointwise estimates of the pose.
TextTopicNet - Self-Supervised Learning of Visual Features Through Embedding Images on Semantic Text Spaces
Jul 04, 2018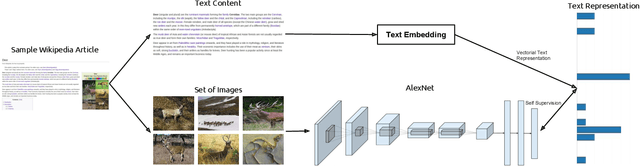
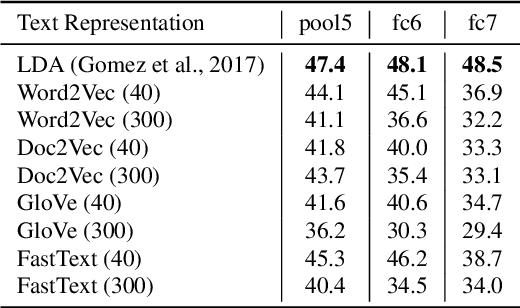

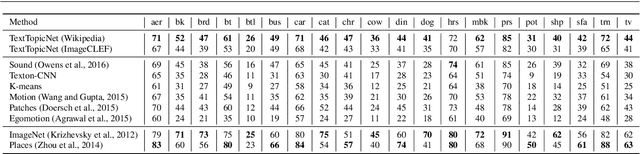
The immense success of deep learning based methods in computer vision heavily relies on large scale training datasets. These richly annotated datasets help the network learn discriminative visual features. Collecting and annotating such datasets requires a tremendous amount of human effort and annotations are limited to popular set of classes. As an alternative, learning visual features by designing auxiliary tasks which make use of freely available self-supervision has become increasingly popular in the computer vision community. In this paper, we put forward an idea to take advantage of multi-modal context to provide self-supervision for the training of computer vision algorithms. We show that adequate visual features can be learned efficiently by training a CNN to predict the semantic textual context in which a particular image is more probable to appear as an illustration. More specifically we use popular text embedding techniques to provide the self-supervision for the training of deep CNN. Our experiments demonstrate state-of-the-art performance in image classification, object detection, and multi-modal retrieval compared to recent self-supervised or naturally-supervised approaches.
Unsupervised Learning of Face Representations
Mar 03, 2018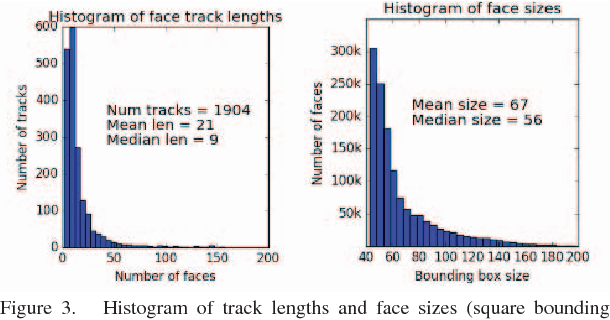
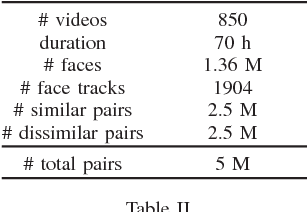
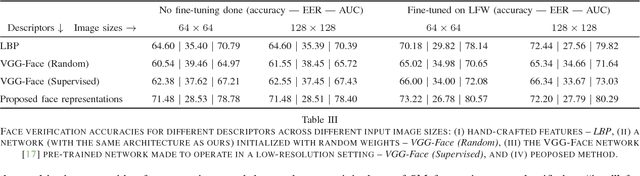
We present an approach for unsupervised training of CNNs in order to learn discriminative face representations. We mine supervised training data by noting that multiple faces in the same video frame must belong to different persons and the same face tracked across multiple frames must belong to the same person. We obtain millions of face pairs from hundreds of videos without using any manual supervision. Although faces extracted from videos have a lower spatial resolution than those which are available as part of standard supervised face datasets such as LFW and CASIA-WebFace, the former represent a much more realistic setting, e.g. in surveillance scenarios where most of the faces detected are very small. We train our CNNs with the relatively low resolution faces extracted from video frames collected, and achieve a higher verification accuracy on the benchmark LFW dataset cf. hand-crafted features such as LBPs, and even surpasses the performance of state-of-the-art deep networks such as VGG-Face, when they are made to work with low resolution input images.
Efficient Optimization for Rank-based Loss Functions
Feb 28, 2018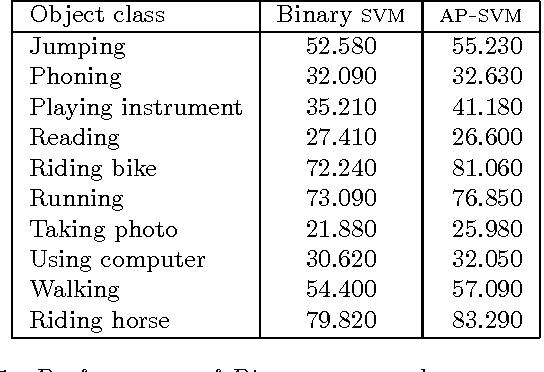
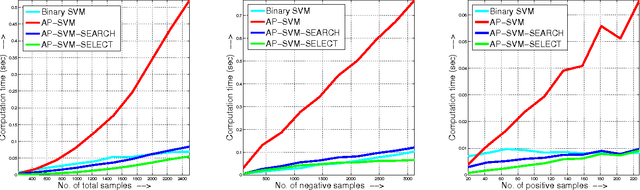
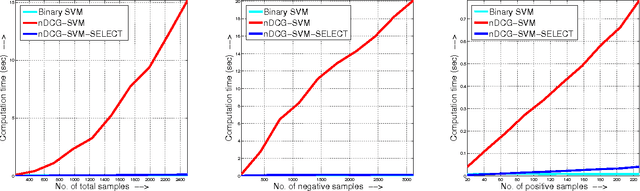

The accuracy of information retrieval systems is often measured using complex loss functions such as the average precision (AP) or the normalized discounted cumulative gain (NDCG). Given a set of positive and negative samples, the parameters of a retrieval system can be estimated by minimizing these loss functions. However, the non-differentiability and non-decomposability of these loss functions does not allow for simple gradient based optimization algorithms. This issue is generally circumvented by either optimizing a structured hinge-loss upper bound to the loss function or by using asymptotic methods like the direct-loss minimization framework. Yet, the high computational complexity of loss-augmented inference, which is necessary for both the frameworks, prohibits its use in large training data sets. To alleviate this deficiency, we present a novel quicksort flavored algorithm for a large class of non-decomposable loss functions. We provide a complete characterization of the loss functions that are amenable to our algorithm, and show that it includes both AP and NDCG based loss functions. Furthermore, we prove that no comparison based algorithm can improve upon the computational complexity of our approach asymptotically. We demonstrate the effectiveness of our approach in the context of optimizing the structured hinge loss upper bound of AP and NDCG loss for learning models for a variety of vision tasks. We show that our approach provides significantly better results than simpler decomposable loss functions, while requiring a comparable training time.