 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTABED: Test-Time Adaptive Ensemble Drafting for Robust Speculative Decoding in LVLMs
Jan 28, 2026Speculative decoding (SD) has proven effective for accelerating LLM inference by quickly generating draft tokens and verifying them in parallel. However, SD remains largely unexplored for Large Vision-Language Models (LVLMs), which extend LLMs to process both image and text prompts. To address this gap, we benchmark existing inference methods with small draft models on 11 datasets across diverse input scenarios and observe scenario-specific performance fluctuations. Motivated by these findings, we propose Test-time Adaptive Batched Ensemble Drafting (TABED), which dynamically ensembles multiple drafts obtained via batch inference by leveraging deviations from past ground truths available in the SD setting. The dynamic ensemble method achieves an average robust walltime speedup of 1.74x over autoregressive decoding and a 5% improvement over single drafting methods, while remaining training-free and keeping ensembling costs negligible through parameter sharing. With its plug-and-play compatibility, we further enhance TABED by integrating advanced verification and alternative drafting methods. Code and custom-trained models are available at https://github.com/furiosa-ai/TABED.
UNCAGE: Contrastive Attention Guidance for Masked Generative Transformers in Text-to-Image Generation
Aug 07, 2025Text-to-image (T2I) generation has been actively studied using Diffusion Models and Autoregressive Models. Recently, Masked Generative Transformers have gained attention as an alternative to Autoregressive Models to overcome the inherent limitations of causal attention and autoregressive decoding through bidirectional attention and parallel decoding, enabling efficient and high-quality image generation. However, compositional T2I generation remains challenging, as even state-of-the-art Diffusion Models often fail to accurately bind attributes and achieve proper text-image alignment. While Diffusion Models have been extensively studied for this issue, Masked Generative Transformers exhibit similar limitations but have not been explored in this context. To address this, we propose Unmasking with Contrastive Attention Guidance (UNCAGE), a novel training-free method that improves compositional fidelity by leveraging attention maps to prioritize the unmasking of tokens that clearly represent individual objects. UNCAGE consistently improves performance in both quantitative and qualitative evaluations across multiple benchmarks and metrics, with negligible inference overhead. Our code is available at https://github.com/furiosa-ai/uncage.
Invertible Monotone Operators for Normalizing Flows
Oct 15, 2022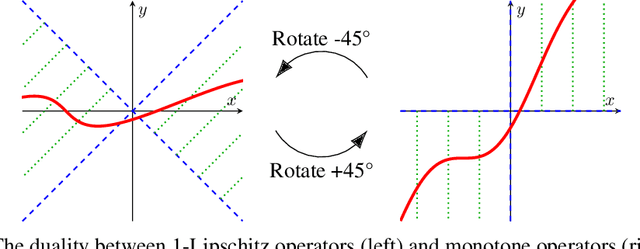
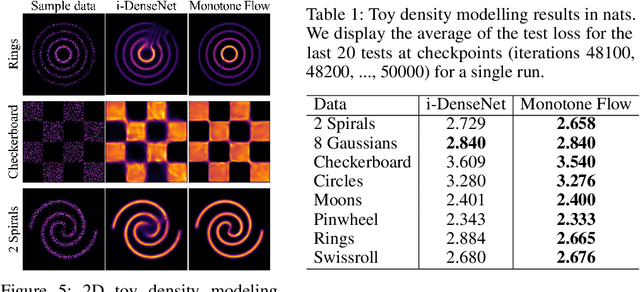
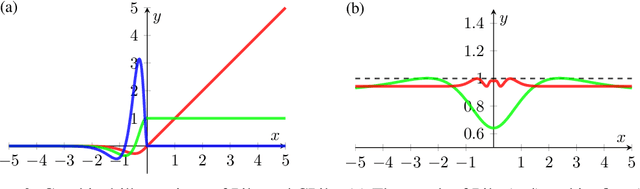
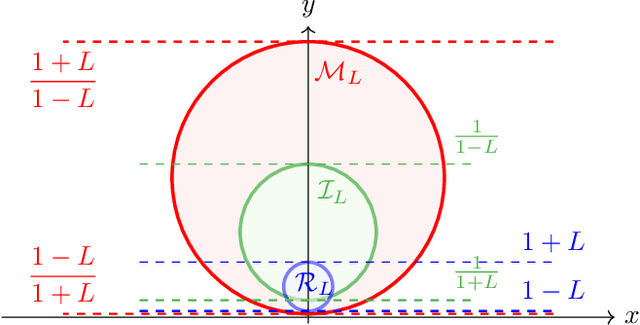
Normalizing flows model probability distributions by learning invertible transformations that transfer a simple distribution into complex distributions. Since the architecture of ResNet-based normalizing flows is more flexible than that of coupling-based models, ResNet-based normalizing flows have been widely studied in recent years. Despite their architectural flexibility, it is well-known that the current ResNet-based models suffer from constrained Lipschitz constants. In this paper, we propose the monotone formulation to overcome the issue of the Lipschitz constants using monotone operators and provide an in-depth theoretical analysis. Furthermore, we construct an activation function called Concatenated Pila (CPila) to improve gradient flow. The resulting model, Monotone Flows, exhibits an excellent performance on multiple density estimation benchmarks (MNIST, CIFAR-10, ImageNet32, ImageNet64). Code is available at https://github.com/mlvlab/MonotoneFlows.