 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWinner's Curse Drives False Promises in Data-Driven Decisions: A Case Study in Refugee Matching
Feb 09, 2026A major challenge in data-driven decision-making is accurate policy evaluation-i.e., guaranteeing that a learned decision-making policy achieves the promised benefits. A popular strategy is model-based policy evaluation, which estimates a model from data to infer counterfactual outcomes. This strategy is known to produce unwarrantedly optimistic estimates of the true benefit due to the winner's curse. We searched the recent literature on data-driven decision-making, identifying a sample of 55 papers published in the Management Science in the past decade; all but two relied on this flawed methodology. Several common justifications are provided: (1) the estimated models are accurate, stable, and well-calibrated, (2) the historical data uses random treatment assignment, (3) the model family is well-specified, and (4) the evaluation methodology uses sample splitting. Unfortunately, we show that no combination of these justifications avoids the winner's curse. First, we provide a theoretical analysis demonstrating that the winner's curse can cause large, spurious reported benefits even when all these justifications hold. Second, we perform a simulation study based on the recent and consequential data-driven refugee matching problem. We construct a synthetic refugee matching environment (calibrated to closely match the real setting) but designed so that no assignment policy can improve expected employment compared to random assignment. Model-based methods report large, stable gains of around 60% even when the true effect is zero; these gains are on par with improvements of 22-75% reported in the literature. Our results provide strong evidence against model-based evaluation.
Designing Algorithmic Recommendations to Achieve Human-AI Complementarity
May 02, 2024



Algorithms frequently assist, rather than replace, human decision-makers. However, the design and analysis of algorithms often focus on predicting outcomes and do not explicitly model their effect on human decisions. This discrepancy between the design and role of algorithmic assistants becomes of particular concern in light of empirical evidence that suggests that algorithmic assistants again and again fail to improve human decisions. In this article, we formalize the design of recommendation algorithms that assist human decision-makers without making restrictive ex-ante assumptions about how recommendations affect decisions. We formulate an algorithmic-design problem that leverages the potential-outcomes framework from causal inference to model the effect of recommendations on a human decision-maker's binary treatment choice. Within this model, we introduce a monotonicity assumption that leads to an intuitive classification of human responses to the algorithm. Under this monotonicity assumption, we can express the human's response to algorithmic recommendations in terms of their compliance with the algorithm and the decision they would take if the algorithm sends no recommendation. We showcase the utility of our framework using an online experiment that simulates a hiring task. We argue that our approach explains the relative performance of different recommendation algorithms in the experiment, and can help design solutions that realize human-AI complementarity.
Algorithmic Assistance with Recommendation-Dependent Preferences
Aug 16, 2022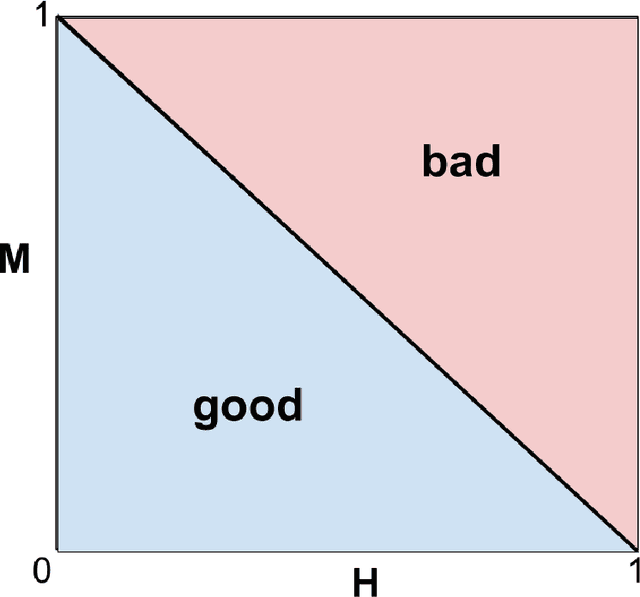
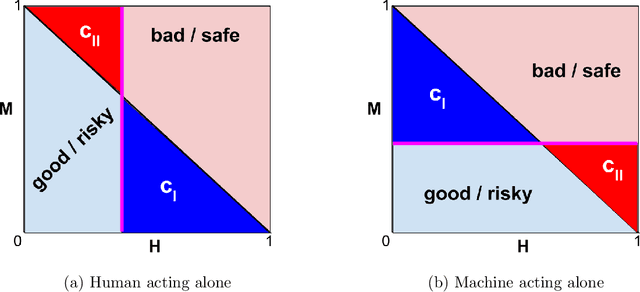
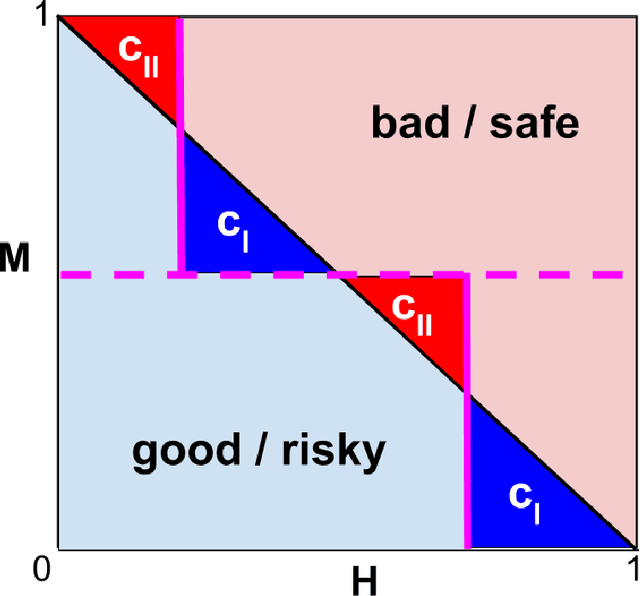
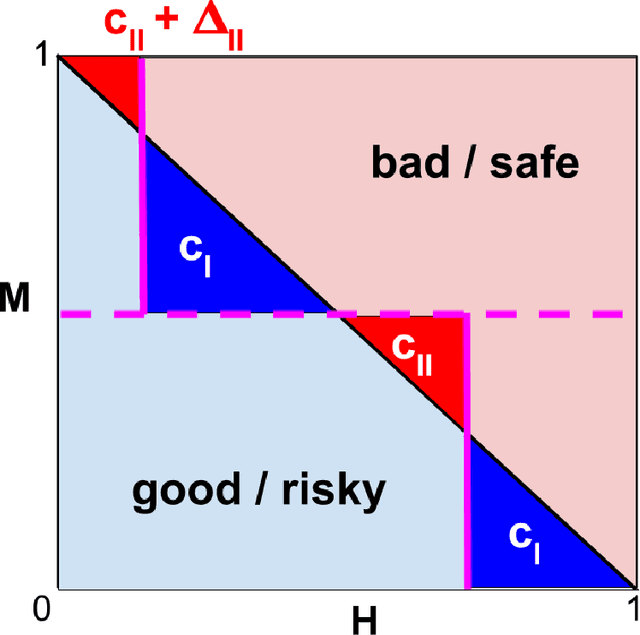
When we use algorithms to produce recommendations, we typically think of these recommendations as providing helpful information, such as when risk assessments are presented to judges or doctors. But when a decision-maker obtains a recommendation, they may not only react to the information. The decision-maker may view the recommendation as a default action, making it costly for them to deviate, for example when a judge is reluctant to overrule a high-risk assessment of a defendant or a doctor fears the consequences of deviating from recommended procedures. In this article, we consider the effect and design of recommendations when they affect choices not just by shifting beliefs, but also by altering preferences. We motivate our model from institutional factors, such as a desire to avoid audits, as well as from well-established models in behavioral science that predict loss aversion relative to a reference point, which here is set by the algorithm. We show that recommendation-dependent preferences create inefficiencies where the decision-maker is overly responsive to the recommendation, which changes the optimal design of the algorithm towards providing less conservative recommendations. As a potential remedy, we discuss an algorithm that strategically withholds recommendations, and show how it can improve the quality of final decisions.
On the Fairness of Machine-Assisted Human Decisions
Oct 28, 2021
When machine-learning algorithms are deployed in high-stakes decisions, we want to ensure that their deployment leads to fair and equitable outcomes. This concern has motivated a fast-growing literature that focuses on diagnosing and addressing disparities in machine predictions. However, many machine predictions are deployed to assist in decisions where a human decision-maker retains the ultimate decision authority. In this article, we therefore consider how properties of machine predictions affect the resulting human decisions. We show in a formal model that the inclusion of a biased human decision-maker can revert common relationships between the structure of the algorithm and the qualities of resulting decisions. Specifically, we document that excluding information about protected groups from the prediction may fail to reduce, and may even increase, ultimate disparities. While our concrete results rely on specific assumptions about the data, algorithm, and decision-maker, they show more broadly that any study of critical properties of complex decision systems, such as the fairness of machine-assisted human decisions, should go beyond focusing on the underlying algorithmic predictions in isolation.