 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDOBE: Infectious Disease Outbreak forecasting Benchmark Ecosystem
Apr 20, 2026Epidemic forecasting has become an integral part of real-time infectious disease outbreak response. While collaborative ensembles composed of statistical and machine learning models have become the norm for real-time forecasting, standardized benchmark datasets for evaluating such methods are lacking. Further, there is limited understanding on performance of these methods for novel outbreaks with limited historical data. In this paper, we propose IDOBE, a curated collection of epidemiological time series focused on outbreak forecasting. IDOBE compiles from multiple data repositories spanning over a century of surveillance and across U.S. states and global locations. We perform derivative-based segmentation to generate over 10,000 outbreaks covering multiple outcomes such as cases and hospitalizations for 13 diseases. We consider a variety of information-theoretic and distributional measures to quantify the epidemiological diversity of the dataset. Finally, we perform multi-horizon short-term forecasting (1- to 4-week-ahead) through the progression of the outbreak using 11 baseline models and report on their performance. In addition to standard metrics such as NMSE and MAPE for point forecasts, we include probabilistic scoring rules such as Normalized Weighted Interval Score (NWIS) to quantify the performance. We find that MLP-based methods have the most robust performance, with statistical methods having a slight edge during the pre-peak phase. IDOBE dataset along with baselines are released publicly on https://github.com/NSSAC/IDOBE to enable standardized, reproducible benchmarking of outbreak forecasting methods.
Examining Deep Learning Models with Multiple Data Sources for COVID-19 Forecasting
Oct 27, 2020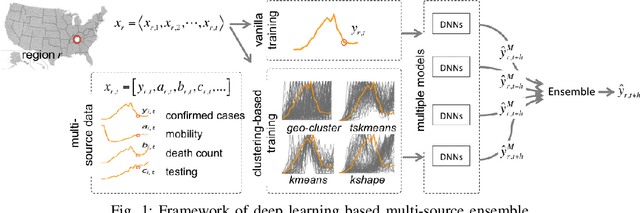
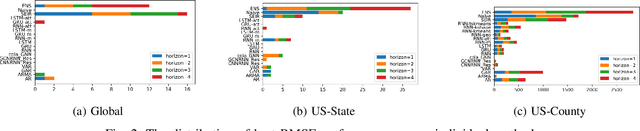
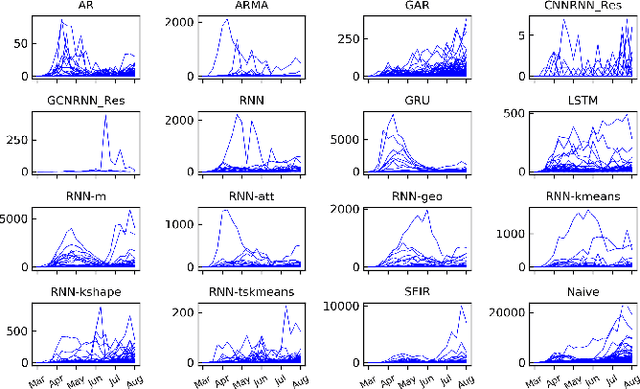
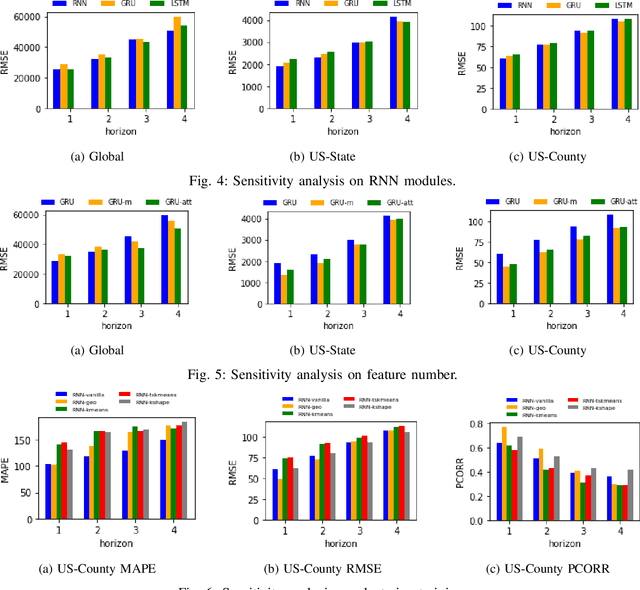
The COVID-19 pandemic represents the most significant public health disaster since the 1918 influenza pandemic. During pandemics such as COVID-19, timely and reliable spatio-temporal forecasting of epidemic dynamics is crucial. Deep learning-based time series models for forecasting have recently gained popularity and have been successfully used for epidemic forecasting. Here we focus on the design and analysis of deep learning-based models for COVID-19 forecasting. We implement multiple recurrent neural network-based deep learning models and combine them using the stacking ensemble technique. In order to incorporate the effects of multiple factors in COVID-19 spread, we consider multiple sources such as COVID-19 testing data and human mobility data for better predictions. To overcome the sparsity of training data and to address the dynamic correlation of the disease, we propose clustering-based training for high-resolution forecasting. The methods help us to identify the similar trends of certain groups of regions due to various spatio-temporal effects. We examine the proposed method for forecasting weekly COVID-19 new confirmed cases at county-, state-, and country-level. A comprehensive comparison between different time series models in COVID-19 context is conducted and analyzed. The results show that simple deep learning models can achieve comparable or better performance when compared with more complicated models. We are currently integrating our methods as a part of our weekly forecasts that we provide state and federal authorities.
Models for COVID-19 Pandemic: A Comparative Analysis
Sep 21, 2020
COVID-19 pandemic represents an unprecedented global health crisis in the last 100 years. Its economic, social and health impact continues to grow and is likely to end up as one of the worst global disasters since the 1918 pandemic and the World Wars. Mathematical models have played an important role in the ongoing crisis; they have been used to inform public policies and have been instrumental in many of the social distancing measures that were instituted worldwide. In this article we review some of the important mathematical models used to support the ongoing planning and response efforts. These models differ in their use, their mathematical form and their scope.
Scatter Matrix Concordance: A Diagnostic for Regressions on Subsets of Data
Jul 12, 2015
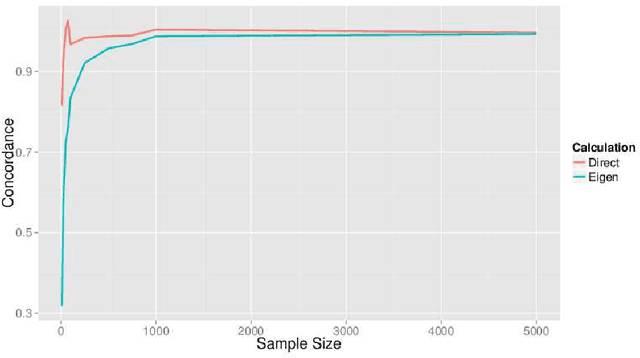
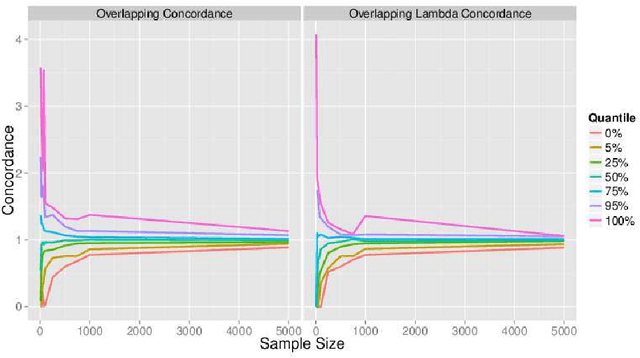
Linear regression models depend directly on the design matrix and its properties. Techniques that efficiently estimate model coefficients by partitioning rows of the design matrix are increasingly popular for large-scale problems because they fit well with modern parallel computing architectures. We propose a simple measure of {\em concordance} between a design matrix and a subset of its rows that estimates how well a subset captures the variance-covariance structure of a larger data set. We illustrate the use of this measure in a heuristic method for selecting row partition sizes that balance statistical and computational efficiency goals in real-world problems.