 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeaning to Form: Measuring Systematicity as Information
Jul 26, 2019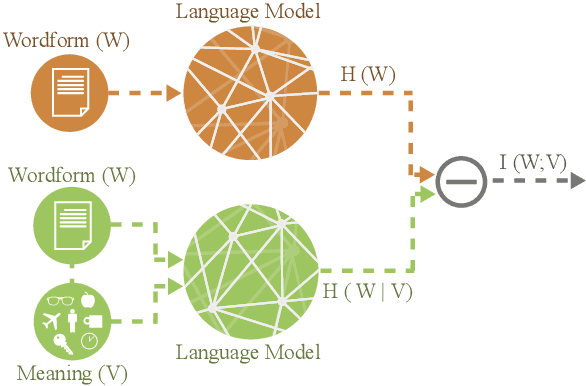
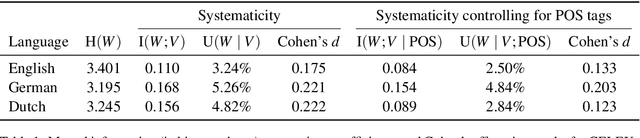
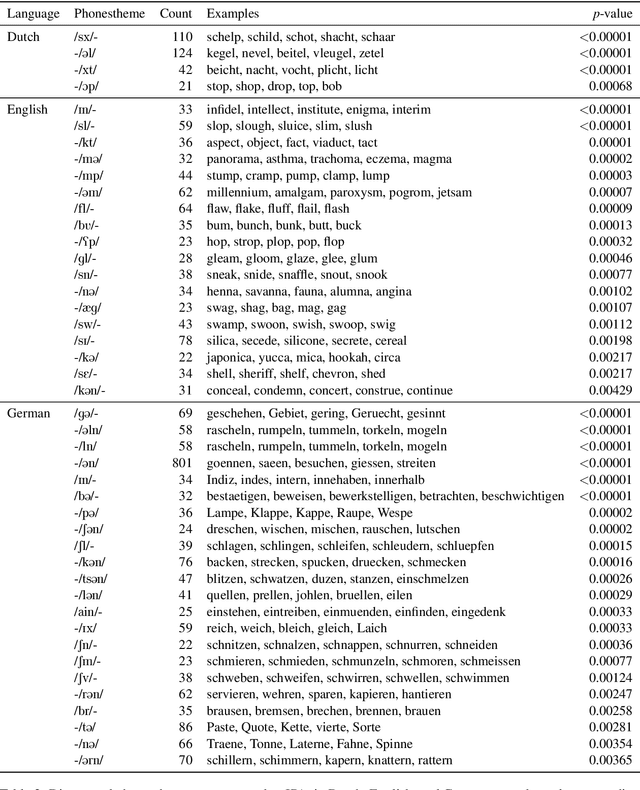
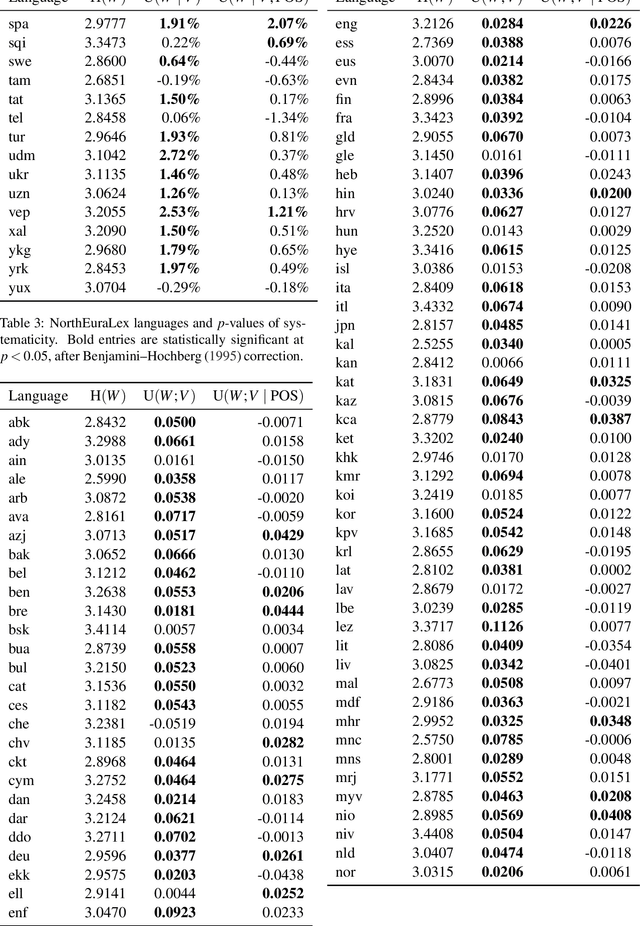
A longstanding debate in semiotics centers on the relationship between linguistic signs and their corresponding semantics: is there an arbitrary relationship between a word form and its meaning, or does some systematic phenomenon pervade? For instance, does the character bigram \textit{gl} have any systematic relationship to the meaning of words like \textit{glisten}, \textit{gleam} and \textit{glow}? In this work, we offer a holistic quantification of the systematicity of the sign using mutual information and recurrent neural networks. We employ these in a data-driven and massively multilingual approach to the question, examining 106 languages. We find a statistically significant reduction in entropy when modeling a word form conditioned on its semantic representation. Encouragingly, we also recover well-attested English examples of systematic affixes. We conclude with the meta-point: Our approximate effect size (measured in bits) is quite small---despite some amount of systematicity between form and meaning, an arbitrary relationship and its resulting benefits dominate human language.
What Kind of Language Is Hard to Language-Model?
Jun 11, 2019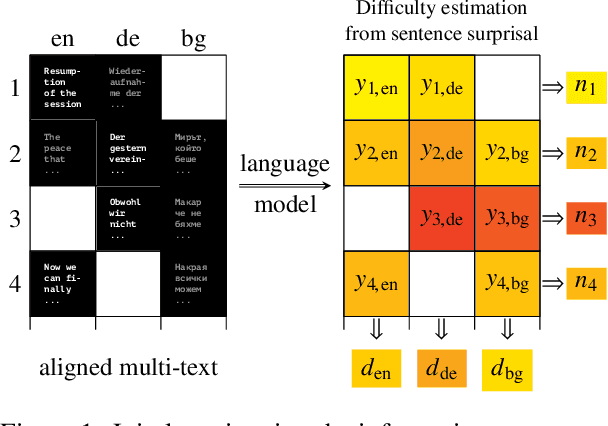
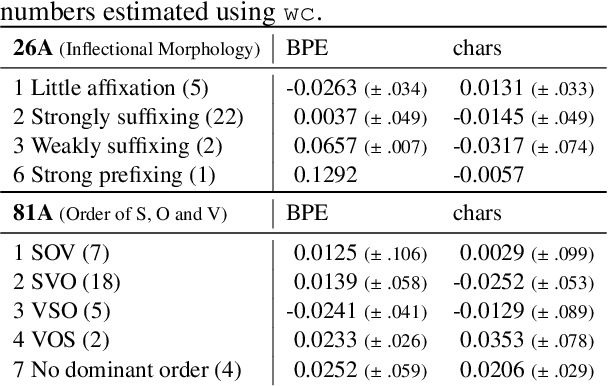
How language-agnostic are current state-of-the-art NLP tools? Are there some types of language that are easier to model with current methods? In prior work (Cotterell et al., 2018) we attempted to address this question for language modeling, and observed that recurrent neural network language models do not perform equally well over all the high-resource European languages found in the Europarl corpus. We speculated that inflectional morphology may be the primary culprit for the discrepancy. In this paper, we extend these earlier experiments to cover 69 languages from 13 language families using a multilingual Bible corpus. Methodologically, we introduce a new paired-sample multiplicative mixed-effects model to obtain language difficulty coefficients from at-least-pairwise parallel corpora. In other words, the model is aware of inter-sentence variation and can handle missing data. Exploiting this model, we show that "translationese" is not any easier to model than natively written language in a fair comparison. Trying to answer the question of what features difficult languages have in common, we try and fail to reproduce our earlier (Cotterell et al., 2018) observation about morphological complexity and instead reveal far simpler statistics of the data that seem to drive complexity in a much larger sample.
Approximating probabilistic models as weighted finite automata
May 21, 2019



Weighted finite automata (WFA) are often used to represent probabilistic models, such as $n$-gram language models, since they are efficient for recognition tasks in time and space. The probabilistic source to be represented as a WFA, however, may come in many forms. Given a generic probabilistic model over sequences, we propose an algorithm to approximate it as a weighted finite automaton such that the Kullback-Leiber divergence between the source model and the WFA target model is minimized. The proposed algorithm involves a counting step and a difference of convex optimization, both of which can be performed efficiently. We demonstrate the usefulness of our approach on various tasks, including distilling $n$-gram models from neural models, building compact language models, and building open-vocabulary character models.
Are All Languages Equally Hard to Language-Model?
Jun 10, 2018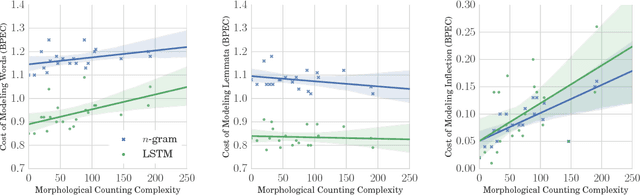
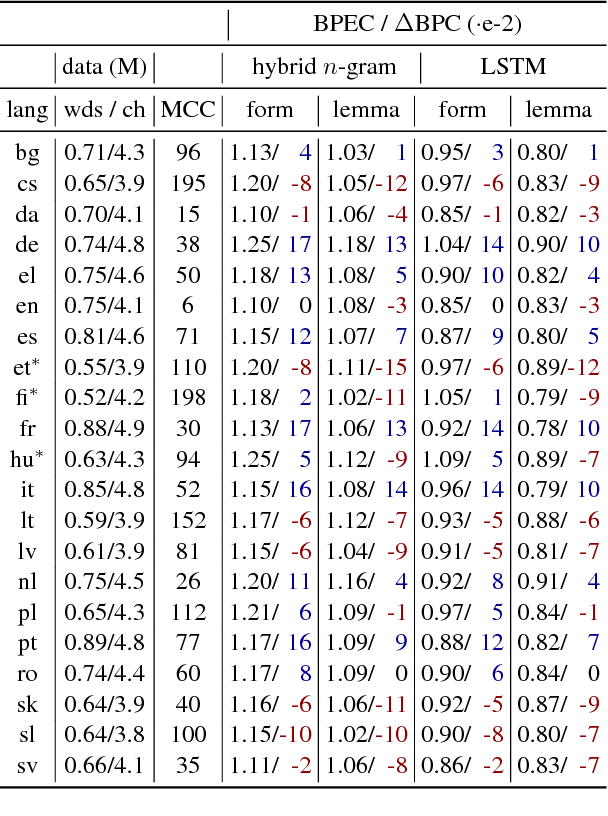
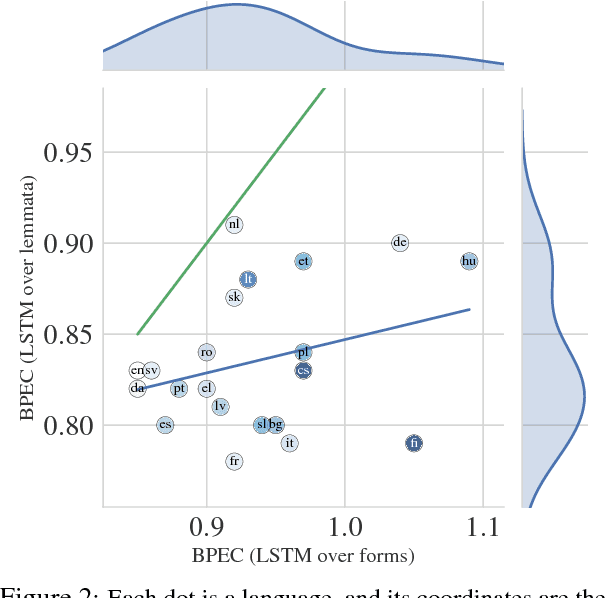
For general modeling methods applied to diverse languages, a natural question is: how well should we expect our models to work on languages with differing typological profiles? In this work, we develop an evaluation framework for fair cross-linguistic comparison of language models, using translated text so that all models are asked to predict approximately the same information. We then conduct a study on 21 languages, demonstrating that in some languages, the textual expression of the information is harder to predict with both $n$-gram and LSTM language models. We show complex inflectional morphology to be a cause of performance differences among languages.
Robust Probabilistic Predictive Syntactic Processing
May 09, 2001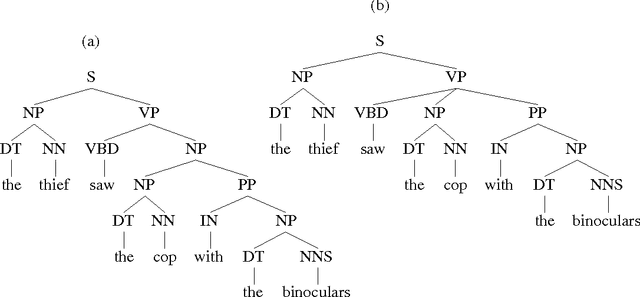
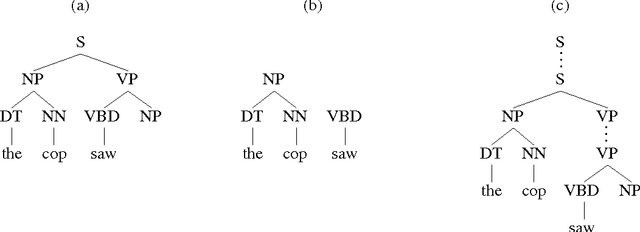
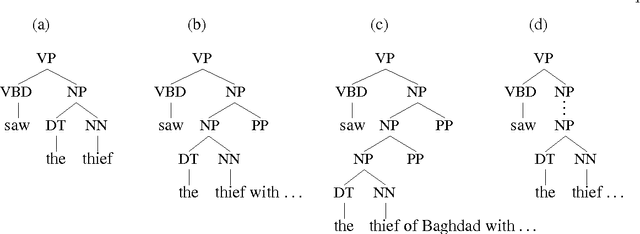
This thesis presents a broad-coverage probabilistic top-down parser, and its application to the problem of language modeling for speech recognition. The parser builds fully connected derivations incrementally, in a single pass from left-to-right across the string. We argue that the parsing approach that we have adopted is well-motivated from a psycholinguistic perspective, as a model that captures probabilistic dependencies between lexical items, as part of the process of building connected syntactic structures. The basic parser and conditional probability models are presented, and empirical results are provided for its parsing accuracy on both newspaper text and spontaneous telephone conversations. Modifications to the probability model are presented that lead to improved performance. A new language model which uses the output of the parser is then defined. Perplexity and word error rate reduction are demonstrated over trigram models, even when the trigram is trained on significantly more data. Interpolation on a word-by-word basis with a trigram model yields additional improvements.
Probabilistic top-down parsing and language modeling
May 08, 2001This paper describes the functioning of a broad-coverage probabilistic top-down parser, and its application to the problem of language modeling for speech recognition. The paper first introduces key notions in language modeling and probabilistic parsing, and briefly reviews some previous approaches to using syntactic structure for language modeling. A lexicalized probabilistic top-down parser is then presented, which performs very well, in terms of both the accuracy of returned parses and the efficiency with which they are found, relative to the best broad-coverage statistical parsers. A new language model which utilizes probabilistic top-down parsing is then outlined, and empirical results show that it improves upon previous work in test corpus perplexity. Interpolation with a trigram model yields an exceptional improvement relative to the improvement observed by other models, demonstrating the degree to which the information captured by our parsing model is orthogonal to that captured by a trigram model. A small recognition experiment also demonstrates the utility of the model.
Measuring efficiency in high-accuracy, broad-coverage statistical parsing
Aug 24, 2000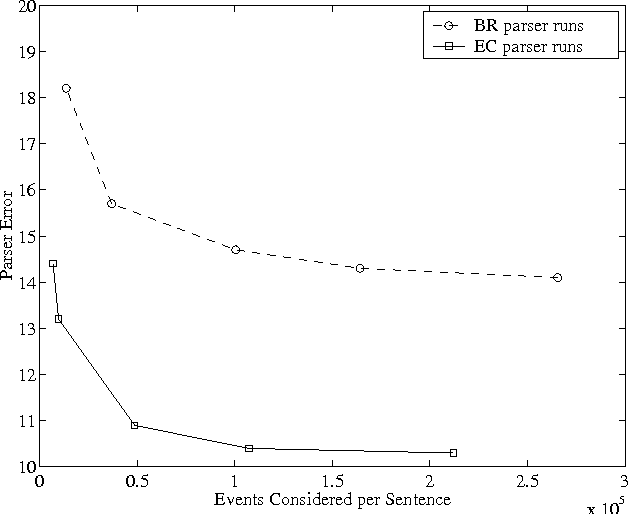
Very little attention has been paid to the comparison of efficiency between high accuracy statistical parsers. This paper proposes one machine-independent metric that is general enough to allow comparisons across very different parsing architectures. This metric, which we call ``events considered'', measures the number of ``events'', however they are defined for a particular parser, for which a probability must be calculated, in order to find the parse. It is applicable to single-pass or multi-stage parsers. We discuss the advantages of the metric, and demonstrate its usefulness by using it to compare two parsers which differ in several fundamental ways.
* 8 pages, 4 figures, 2 tables
Noun-phrase co-occurrence statistics for semi-automatic semantic lexicon construction
Aug 24, 2000
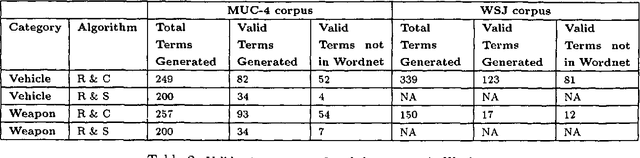
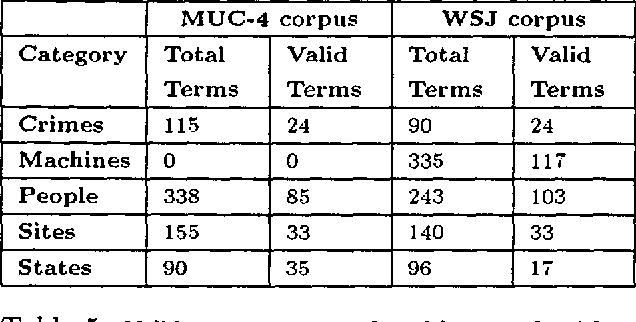
Generating semantic lexicons semi-automatically could be a great time saver, relative to creating them by hand. In this paper, we present an algorithm for extracting potential entries for a category from an on-line corpus, based upon a small set of exemplars. Our algorithm finds more correct terms and fewer incorrect ones than previous work in this area. Additionally, the entries that are generated potentially provide broader coverage of the category than would occur to an individual coding them by hand. Our algorithm finds many terms not included within Wordnet (many more than previous algorithms), and could be viewed as an ``enhancer'' of existing broad-coverage resources.
* 7 pages, 1 figure, 5 tables
Compact non-left-recursive grammars using the selective left-corner transform and factoring
Aug 22, 2000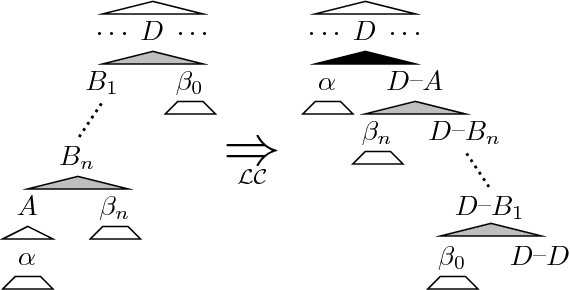

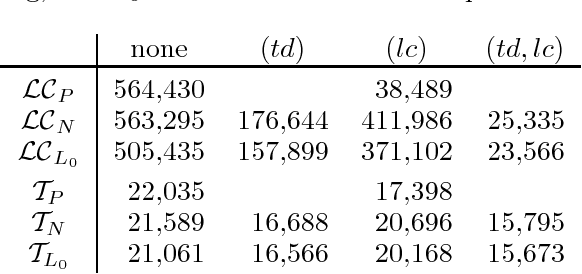
The left-corner transform removes left-recursion from (probabilistic) context-free grammars and unification grammars, permitting simple top-down parsing techniques to be used. Unfortunately the grammars produced by the standard left-corner transform are usually much larger than the original. The selective left-corner transform described in this paper produces a transformed grammar which simulates left-corner recognition of a user-specified set of the original productions, and top-down recognition of the others. Combined with two factorizations, it produces non-left-recursive grammars that are not much larger than the original.
* 7 pages, 5 tables, 2 figures
Efficient probabilistic top-down and left-corner parsing
Aug 21, 2000



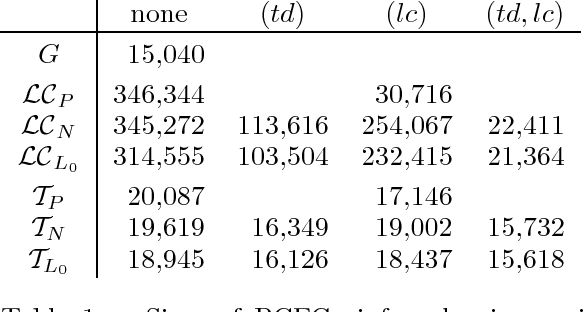
This paper examines efficient predictive broad-coverage parsing without dynamic programming. In contrast to bottom-up methods, depth-first top-down parsing produces partial parses that are fully connected trees spanning the entire left context, from which any kind of non-local dependency or partial semantic interpretation can in principle be read. We contrast two predictive parsing approaches, top-down and left-corner parsing, and find both to be viable. In addition, we find that enhancement with non-local information not only improves parser accuracy, but also substantially improves the search efficiency.
* 8 pages, 3 tables, 3 figures