 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepAdversaries: Examining the Robustness of Deep Learning Models for Galaxy Morphology Classification
Dec 28, 2021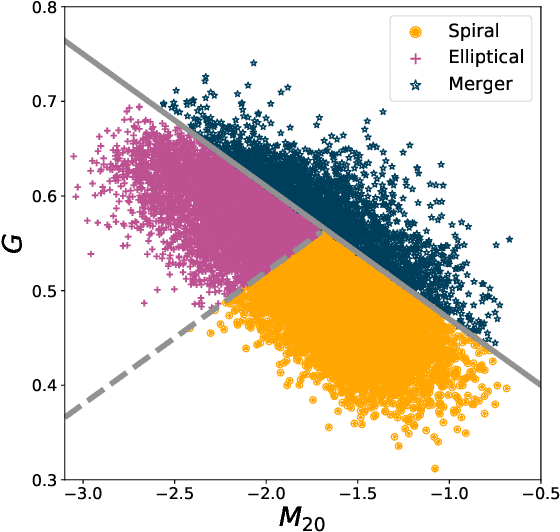
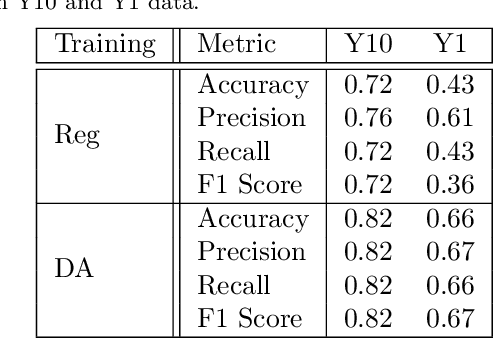
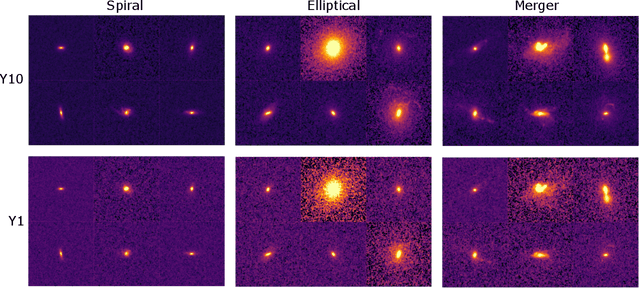
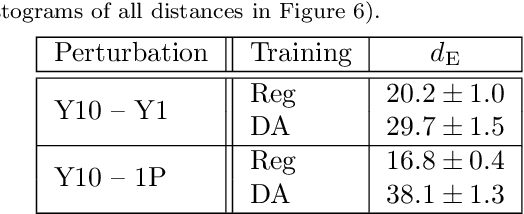
Data processing and analysis pipelines in cosmological survey experiments introduce data perturbations that can significantly degrade the performance of deep learning-based models. Given the increased adoption of supervised deep learning methods for processing and analysis of cosmological survey data, the assessment of data perturbation effects and the development of methods that increase model robustness are increasingly important. In the context of morphological classification of galaxies, we study the effects of perturbations in imaging data. In particular, we examine the consequences of using neural networks when training on baseline data and testing on perturbed data. We consider perturbations associated with two primary sources: 1) increased observational noise as represented by higher levels of Poisson noise and 2) data processing noise incurred by steps such as image compression or telescope errors as represented by one-pixel adversarial attacks. We also test the efficacy of domain adaptation techniques in mitigating the perturbation-driven errors. We use classification accuracy, latent space visualizations, and latent space distance to assess model robustness. Without domain adaptation, we find that processing pixel-level errors easily flip the classification into an incorrect class and that higher observational noise makes the model trained on low-noise data unable to classify galaxy morphologies. On the other hand, we show that training with domain adaptation improves model robustness and mitigates the effects of these perturbations, improving the classification accuracy by 23% on data with higher observational noise. Domain adaptation also increases by a factor of ~2.3 the latent space distance between the baseline and the incorrectly classified one-pixel perturbed image, making the model more robust to inadvertent perturbations.
Unsupervised Resource Allocation with Graph Neural Networks
Jun 17, 2021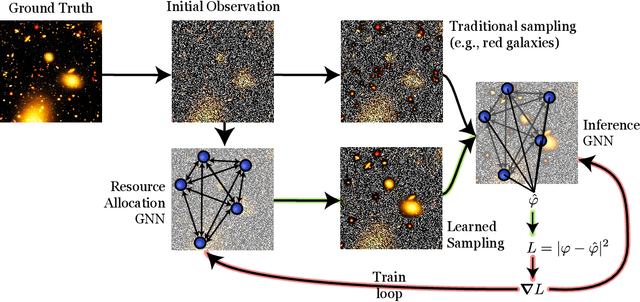

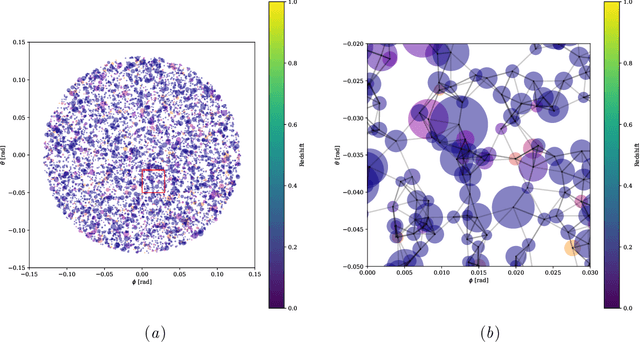
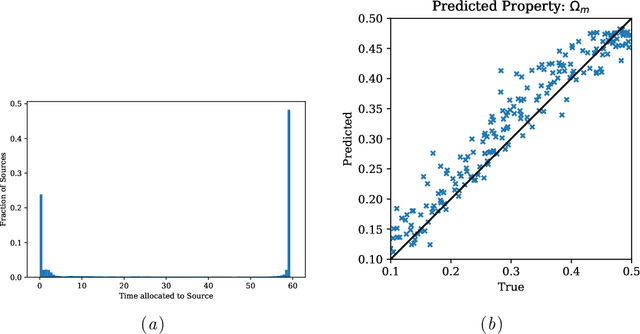
We present an approach for maximizing a global utility function by learning how to allocate resources in an unsupervised way. We expect interactions between allocation targets to be important and therefore propose to learn the reward structure for near-optimal allocation policies with a GNN. By relaxing the resource constraint, we can employ gradient-based optimization in contrast to more standard evolutionary algorithms. Our algorithm is motivated by a problem in modern astronomy, where one needs to select-based on limited initial information-among $10^9$ galaxies those whose detailed measurement will lead to optimal inference of the composition of the universe. Our technique presents a way of flexibly learning an allocation strategy by only requiring forward simulators for the physics of interest and the measurement process. We anticipate that our technique will also find applications in a range of resource allocation problems.
DeepSZ: Identification of Sunyaev-Zel'dovich Galaxy Clusters using Deep Learning
Mar 08, 2021
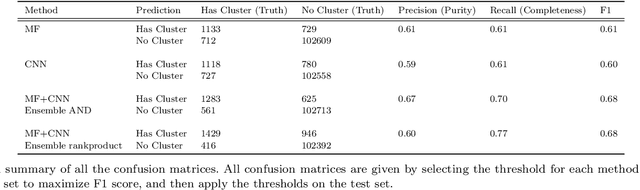


Galaxy clusters identified from the Sunyaev Zel'dovich (SZ) effect are a key ingredient in multi-wavelength cluster-based cosmology. We present a comparison between two methods of cluster identification: the standard Matched Filter (MF) method in SZ cluster finding and a method using Convolutional Neural Networks (CNN). We further implement and show results for a `combined' identifier. We apply the methods to simulated millimeter maps for several observing frequencies for an SPT-3G-like survey. There are some key differences between the methods. The MF method requires image pre-processing to remove point sources and a model for the noise, while the CNN method requires very little pre-processing of images. Additionally, the CNN requires tuning of hyperparameters in the model and takes as input, cutout images of the sky. Specifically, we use the CNN to classify whether or not an 8 arcmin $\times$ 8 arcmin cutout of the sky contains a cluster. We compare differences in purity and completeness. The MF signal-to-noise ratio depends on both mass and redshift. Our CNN, trained for a given mass threshold, captures a different set of clusters than the MF, some of which have SNR below the MF detection threshold. However, the CNN tends to mis-classify cutouts whose clusters are located near the edge of the cutout, which can be mitigated with staggered cutouts. We leverage the complementarity of the two methods, combining the scores from each method for identification. The purity and completeness of the MF alone are both 0.61, assuming a standard detection threshold. The purity and completeness of the CNN alone are 0.59 and 0.61. The combined classification method yields 0.60 and 0.77, a significant increase for completeness with a modest decrease in purity. We advocate for combined methods that increase the confidence of many lower signal-to-noise clusters.
Deep learning insights into cosmological structure formation
Nov 20, 2020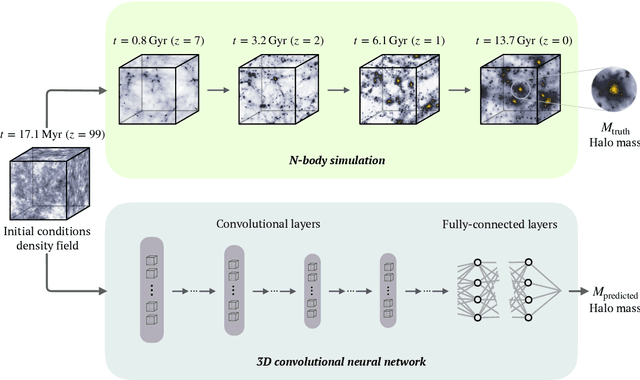
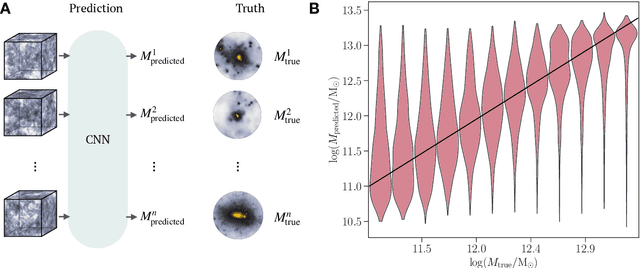
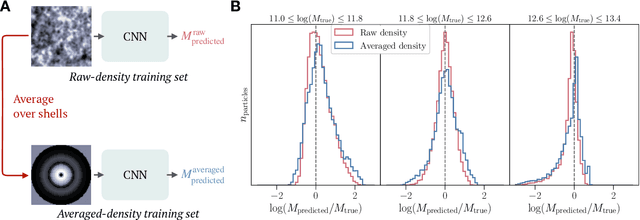
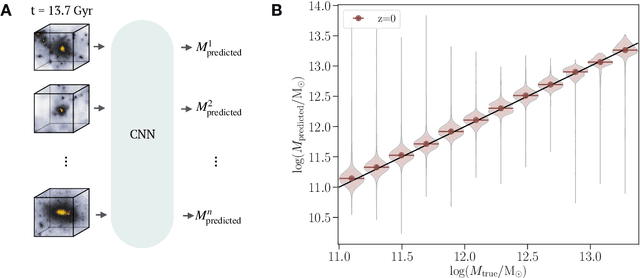
While the evolution of linear initial conditions present in the early universe into extended halos of dark matter at late times can be computed using cosmological simulations, a theoretical understanding of this complex process remains elusive. Here, we build a deep learning framework to learn this non-linear relationship, and develop techniques to physically interpret the learnt mapping. A three-dimensional convolutional neural network (CNN) is trained to predict the mass of dark matter halos from the initial conditions. We find no change in the predictive accuracy of the model if we retrain the model removing anisotropic information from the inputs. This suggests that the features learnt by the CNN are equivalent to spherical averages over the initial conditions. Our results indicate that interpretable deep learning frameworks can provide a powerful tool for extracting insight into cosmological structure formation.
Deeply Uncertain: Comparing Methods of Uncertainty Quantification in Deep Learning Algorithms
May 04, 2020
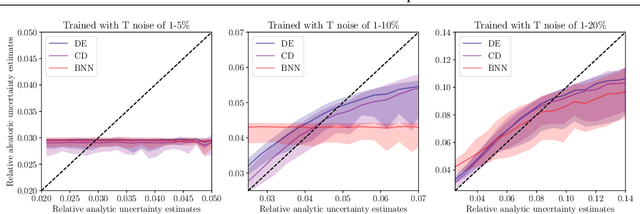
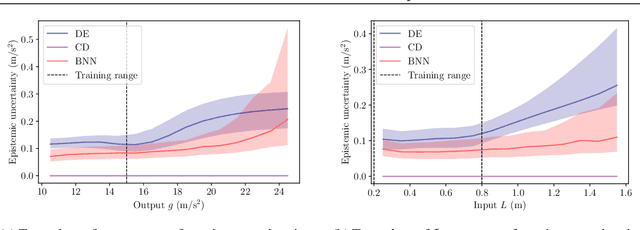

We present a comparison of methods for uncertainty quantification (UQ) in deep learning algorithms in the context of a simple physical system. Three of the most common uncertainty quantification methods - Bayesian Neural Networks (BNN), Concrete Dropout (CD), and Deep Ensembles (DE) - are compared to the standard analytic error propagation. We discuss this comparison in terms endemic to both machine learning ("epistemic" and "aleatoric") and the physical sciences ("statistical" and "systematic"). The comparisons are presented in terms of simulated experimental measurements of a single pendulum - a prototypical physical system for studying measurement and analysis techniques. Our results highlight some pitfalls that may occur when using these UQ methods. For example, when the variation of noise in the training set is small, all methods predicted the same relative uncertainty independently of the inputs. This issue is particularly hard to avoid in BNN. On the other hand, when the test set contains samples far from the training distribution, we found that no methods sufficiently increased the uncertainties associated to their predictions. This problem was particularly clear for CD. In light of these results, we make some recommendations for usage and interpretation of UQ methods.
Restricted Boltzmann Machines for galaxy morphology classification with a quantum annealer
Nov 14, 2019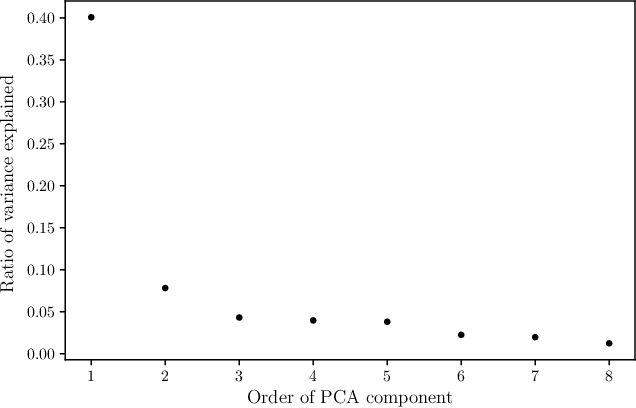


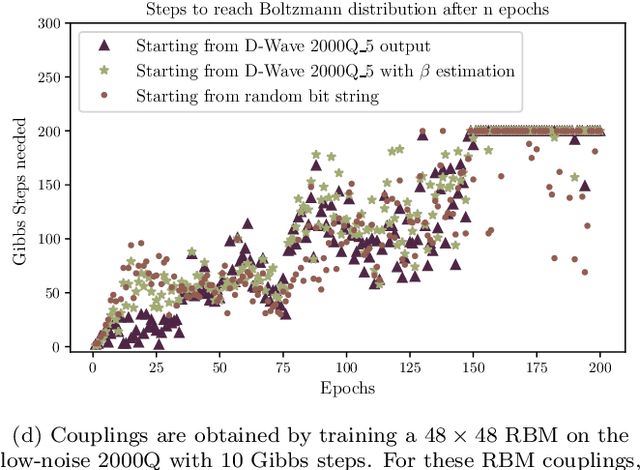
We present the application of Restricted Boltzmann Machines (RBMs) to the task of astronomical image classification using a quantum annealer built by D-Wave Systems. Morphological analysis of galaxies provides critical information for studying their formation and evolution across cosmic time scales. We compress the images using principal component analysis to fit a representation on the quantum hardware. Then, we train RBMs with discriminative and generative algorithms, including contrastive divergence and hybrid generative-discriminative approaches. We compare these methods to Quantum Annealing (QA), Markov Chain Monte Carlo (MCMC) Gibbs Sampling, Simulated Annealing (SA) as well as machine learning algorithms like gradient boosted decision trees. We find that RBMs implemented on D-wave hardware perform well, and that they show some classification performance advantages on small datasets, but they don't offer a broadly strategic advantage for this task. During this exploration, we analyzed the steps required for Boltzmann sampling with the D-Wave 2000Q, including a study of temperature estimation, and examined the impact of qubit noise by comparing and contrasting the original D-Wave 2000Q to the lower-noise version recently made available. While these analyses ultimately had minimal impact on the performance of the RBMs, we include them for reference.
Algorithms and Statistical Models for Scientific Discovery in the Petabyte Era
Nov 05, 2019The field of astronomy has arrived at a turning point in terms of size and complexity of both datasets and scientific collaboration. Commensurately, algorithms and statistical models have begun to adapt --- e.g., via the onset of artificial intelligence --- which itself presents new challenges and opportunities for growth. This white paper aims to offer guidance and ideas for how we can evolve our technical and collaborative frameworks to promote efficient algorithmic development and take advantage of opportunities for scientific discovery in the petabyte era. We discuss challenges for discovery in large and complex data sets; challenges and requirements for the next stage of development of statistical methodologies and algorithmic tool sets; how we might change our paradigms of collaboration and education; and the ethical implications of scientists' contributions to widely applicable algorithms and computational modeling. We start with six distinct recommendations that are supported by the commentary following them. This white paper is related to a larger corpus of effort that has taken place within and around the Petabytes to Science Workshops (https://petabytestoscience.github.io/).