 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRespondeoQA: a Benchmark for Bilingual Latin-English Question Answering
Apr 22, 2026We introduce a benchmark dataset for question answering and translation in bilingual Latin and English settings, containing about 7,800 question-answer pairs. The questions are drawn from Latin pedagogical sources, including exams, quizbowl-style trivia, and textbooks ranging from the 1800s to the present. After automated extraction, cleaning, and manual review, the dataset covers a diverse range of question types: knowledge- and skill-based, multihop reasoning, constrained translation, and mixed language pairs. To our knowledge, this is the first QA benchmark centered on Latin. As a case study, we evaluate three large language models -- LLaMa 3, Qwen QwQ, and OpenAI's o3-mini -- finding that all perform worse on skill-oriented questions. Although the reasoning models perform better on scansion and literary-device tasks, they offer limited improvement overall. QwQ performs slightly better on questions asked in Latin, but LLaMa3 and o3-mini are more task dependent. This dataset provides a new resource for assessing model capabilities in a specialized linguistic and cultural domain, and the creation process can be easily adapted for other languages. The dataset is available at: https://github.com/slanglab/RespondeoQA
Contextual morphologically-guided tokenization for Latin encoder models
Nov 12, 2025Tokenization is a critical component of language model pretraining, yet standard tokenization methods often prioritize information-theoretical goals like high compression and low fertility rather than linguistic goals like morphological alignment. In fact, they have been shown to be suboptimal for morphologically rich languages, where tokenization quality directly impacts downstream performance. In this work, we investigate morphologically-aware tokenization for Latin, a morphologically rich language that is medium-resource in terms of pretraining data, but high-resource in terms of curated lexical resources -- a distinction that is often overlooked but critical in discussions of low-resource language modeling. We find that morphologically-guided tokenization improves overall performance on four downstream tasks. Performance gains are most pronounced for out of domain texts, highlighting our models' improved generalization ability. Our findings demonstrate the utility of linguistic resources to improve language modeling for morphologically complex languages. For low-resource languages that lack large-scale pretraining data, the development and incorporation of linguistic resources can serve as a feasible alternative to improve LM performance.
Evaluating Morphological Alignment of Tokenizers in 70 Languages
Jul 08, 2025While tokenization is a key step in language modeling, with effects on model training and performance, it remains unclear how to effectively evaluate tokenizer quality. One proposed dimension of tokenizer quality is the extent to which tokenizers preserve linguistically meaningful subwords, aligning token boundaries with morphological boundaries within a word. We expand MorphScore (Arnett & Bergen, 2025), which previously covered 22 languages, to support a total of 70 languages. The updated MorphScore offers more flexibility in evaluation and addresses some of the limitations of the original version. We then correlate our alignment scores with downstream task performance for five pre-trained languages models on seven tasks, with at least one task in each of the languages in our sample. We find that morphological alignment does not explain very much variance in model performance, suggesting that morphological alignment alone does not measure dimensions of tokenization quality relevant to model performance.
Identifying and Investigating Global News Coverage of Critical Events Such as Disasters and Terrorist Attacks
Jun 15, 2025



Comparative studies of news coverage are challenging to conduct because methods to identify news articles about the same event in different languages require expertise that is difficult to scale. We introduce an AI-powered method for identifying news articles based on an event FINGERPRINT, which is a minimal set of metadata required to identify critical events. Our event coverage identification method, FINGERPRINT TO ARTICLE MATCHING FOR EVENTS (FAME), efficiently identifies news articles about critical world events, specifically terrorist attacks and several types of natural disasters. FAME does not require training data and is able to automatically and efficiently identify news articles that discuss an event given its fingerprint: time, location, and class (such as storm or flood). The method achieves state-of-the-art performance and scales to massive databases of tens of millions of news articles and hundreds of events happening globally. We use FAME to identify 27,441 articles that cover 470 natural disaster and terrorist attack events that happened in 2020. To this end, we use a massive database of news articles in three languages from MediaCloud, and three widely used, expert-curated databases of critical events: EM-DAT, USGS, and GTD. Our case study reveals patterns consistent with prior literature: coverage of disasters and terrorist attacks correlates to death counts, to the GDP of a country where the event occurs, and to trade volume between the reporting country and the country where the event occurred. We share our NLP annotations and cross-country media attention data to support the efforts of researchers and media monitoring organizations.
Understanding the Effect of Knowledge Graph Extraction Error on Downstream Graph Analyses: A Case Study on Affiliation Graphs
Jun 14, 2025Knowledge graphs (KGs) are useful for analyzing social structures, community dynamics, institutional memberships, and other complex relationships across domains from sociology to public health. While recent advances in large language models (LLMs) have improved the scalability and accessibility of automated KG extraction from large text corpora, the impacts of extraction errors on downstream analyses are poorly understood, especially for applied scientists who depend on accurate KGs for real-world insights. To address this gap, we conducted the first evaluation of KG extraction performance at two levels: (1) micro-level edge accuracy, which is consistent with standard NLP evaluations, and manual identification of common error sources; (2) macro-level graph metrics that assess structural properties such as community detection and connectivity, which are relevant to real-world applications. Focusing on affiliation graphs of person membership in organizations extracted from social register books, our study identifies a range of extraction performance where biases across most downstream graph analysis metrics are near zero. However, as extraction performance declines, we find that many metrics exhibit increasingly pronounced biases, with each metric tending toward a consistent direction of either over- or under-estimation. Through simulations, we further show that error models commonly used in the literature do not capture these bias patterns, indicating the need for more realistic error models for KG extraction. Our findings provide actionable insights for practitioners and underscores the importance of advancing extraction methods and error modeling to ensure reliable and meaningful downstream analyses.
Relation Extraction Across Entire Books to Reconstruct Community Networks: The AffilKG Datasets
May 16, 2025
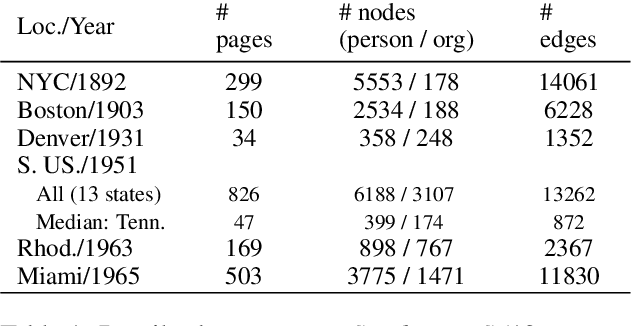

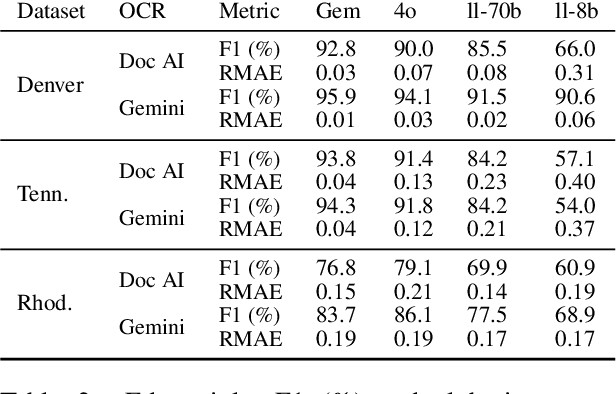
When knowledge graphs (KGs) are automatically extracted from text, are they accurate enough for downstream analysis? Unfortunately, current annotated datasets can not be used to evaluate this question, since their KGs are highly disconnected, too small, or overly complex. To address this gap, we introduce AffilKG (https://doi.org/10.5281/zenodo.15427977), which is a collection of six datasets that are the first to pair complete book scans with large, labeled knowledge graphs. Each dataset features affiliation graphs, which are simple KGs that capture Member relationships between Person and Organization entities -- useful in studies of migration, community interactions, and other social phenomena. In addition, three datasets include expanded KGs with a wider variety of relation types. Our preliminary experiments demonstrate significant variability in model performance across datasets, underscoring AffilKG's ability to enable two critical advances: (1) benchmarking how extraction errors propagate to graph-level analyses (e.g., community structure), and (2) validating KG extraction methods for real-world social science research.
Multilingualism, Transnationality, and K-pop in the Online #StopAsianHate Movement
Mar 04, 2025



The #StopAsianHate (SAH) movement is a broad social movement against violence targeting Asians and Asian Americans, beginning in 2021 in response to racial discrimination related to COVID-19 and sparking worldwide conversation about anti-Asian hate. However, research on the online SAH movement has focused on English-speaking participants so the spread of the movement outside of the United States is largely unknown. In addition, there have been no long-term studies of SAH so the extent to which it has been successfully sustained over time is not well understood. We present an analysis of 6.5 million "#StopAsianHate" tweets from 2.2 million users all over the globe and spanning 60 different languages, constituting the first study of the non-English and transnational component of the online SAH movement. Using a combination of topic modeling, user modeling, and hand annotation, we identify and characterize the dominant discussions and users participating in the movement and draw comparisons of English versus non-English topics and users. We discover clear differences in events driving topics, where spikes in English tweets are driven by violent crimes in the US but spikes in non-English tweets are driven by transnational incidents of anti-Asian sentiment towards symbolic representatives of Asian nations. We also find that global K-pop fans were quick to adopt the SAH movement and, in fact, sustained it for longer than any other user group. Our work contributes to understanding the transnationality and evolution of the SAH movement, and more generally to exploring upward scale shift and public attention in large-scale multilingual online activism.
A Semantic Parsing Algorithm to Solve Linear Ordering Problems
Feb 12, 2025



We develop an algorithm to semantically parse linear ordering problems, which require a model to arrange entities using deductive reasoning. Our method takes as input a number of premises and candidate statements, parsing them to a first-order logic of an ordering domain, and then utilizes constraint logic programming to infer the truth of proposed statements about the ordering. Our semantic parser transforms Heim and Kratzer's syntax-based compositional formal semantic rules to a computational algorithm. This transformation involves introducing abstract types and templates based on their rules, and introduces a dynamic component to interpret entities within a contextual framework. Our symbolic system, the Formal Semantic Logic Inferer (FSLI), is applied to answer multiple choice questions in BIG-bench's logical_deduction multiple choice problems, achieving perfect accuracy, compared to 67.06% for the best-performing LLM (GPT-4) and 87.63% for the hybrid system Logic-LM. These promising results demonstrate the benefit of developing a semantic parsing algorithm driven by first-order logic constructs.
Latin Treebanks in Review: An Evaluation of Morphological Tagging Across Time
Aug 13, 2024



Existing Latin treebanks draw from Latin's long written tradition, spanning 17 centuries and a variety of cultures. Recent efforts have begun to harmonize these treebanks' annotations to better train and evaluate morphological taggers. However, the heterogeneity of these treebanks must be carefully considered to build effective and reliable data. In this work, we review existing Latin treebanks to identify the texts they draw from, identify their overlap, and document their coverage across time and genre. We additionally design automated conversions of their morphological feature annotations into the conventions of standard Latin grammar. From this, we build new time-period data splits that draw from the existing treebanks which we use to perform a broad cross-time analysis for POS and morphological feature tagging. We find that BERT-based taggers outperform existing taggers while also being more robust to cross-domain shifts.
Where on Earth Do Users Say They Are?: Geo-Entity Linking for Noisy Multilingual User Input
Apr 29, 2024



Geo-entity linking is the task of linking a location mention to the real-world geographic location. In this paper we explore the challenging task of geo-entity linking for noisy, multilingual social media data. There are few open-source multilingual geo-entity linking tools available and existing ones are often rule-based, which break easily in social media settings, or LLM-based, which are too expensive for large-scale datasets. We present a method which represents real-world locations as averaged embeddings from labeled user-input location names and allows for selective prediction via an interpretable confidence score. We show that our approach improves geo-entity linking on a global and multilingual social media dataset, and discuss progress and problems with evaluating at different geographic granularities.