 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelation Extraction Across Entire Books to Reconstruct Community Networks: The AffilKG Datasets
Paper and Code
May 16, 2025
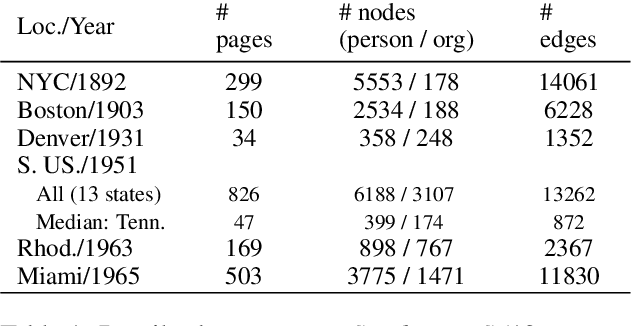

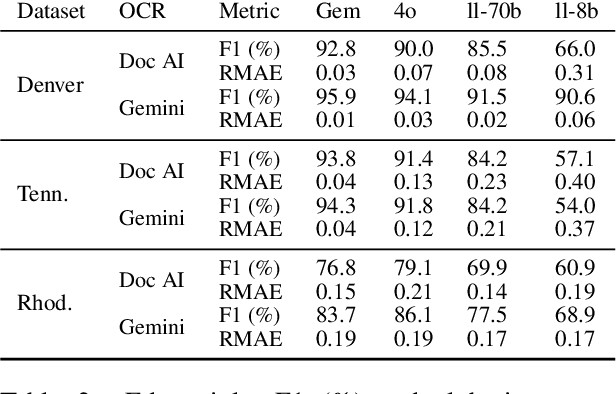
When knowledge graphs (KGs) are automatically extracted from text, are they accurate enough for downstream analysis? Unfortunately, current annotated datasets can not be used to evaluate this question, since their KGs are highly disconnected, too small, or overly complex. To address this gap, we introduce AffilKG (https://doi.org/10.5281/zenodo.15427977), which is a collection of six datasets that are the first to pair complete book scans with large, labeled knowledge graphs. Each dataset features affiliation graphs, which are simple KGs that capture Member relationships between Person and Organization entities -- useful in studies of migration, community interactions, and other social phenomena. In addition, three datasets include expanded KGs with a wider variety of relation types. Our preliminary experiments demonstrate significant variability in model performance across datasets, underscoring AffilKG's ability to enable two critical advances: (1) benchmarking how extraction errors propagate to graph-level analyses (e.g., community structure), and (2) validating KG extraction methods for real-world social science research.