 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep LF-Net: Semantic Lung Segmentation from Indian Chest Radiographs Including Severely Unhealthy Images
Nov 19, 2020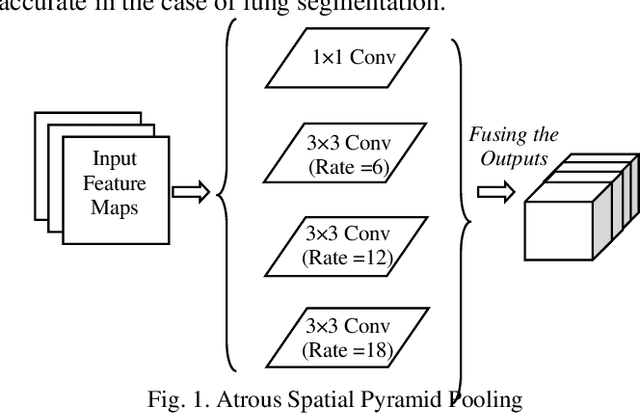
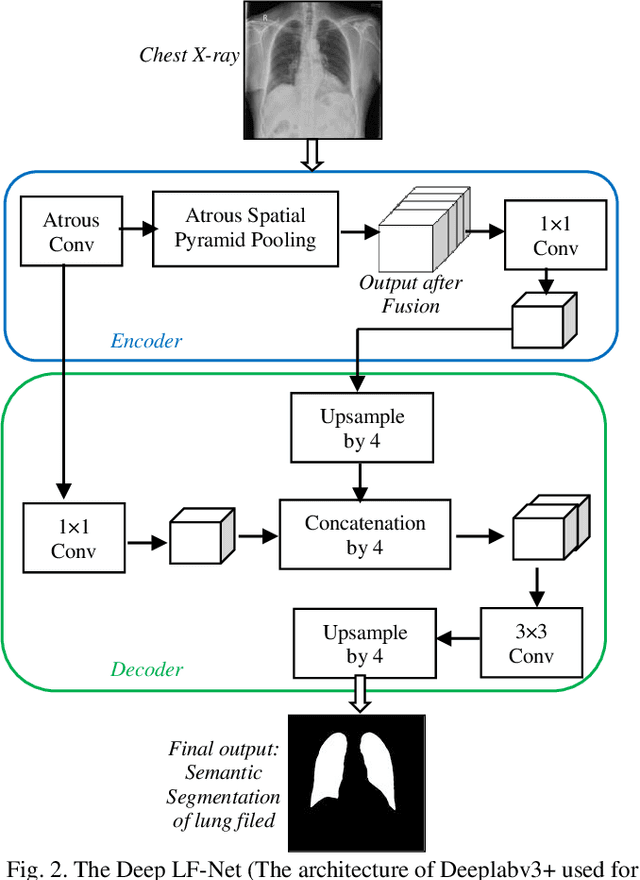
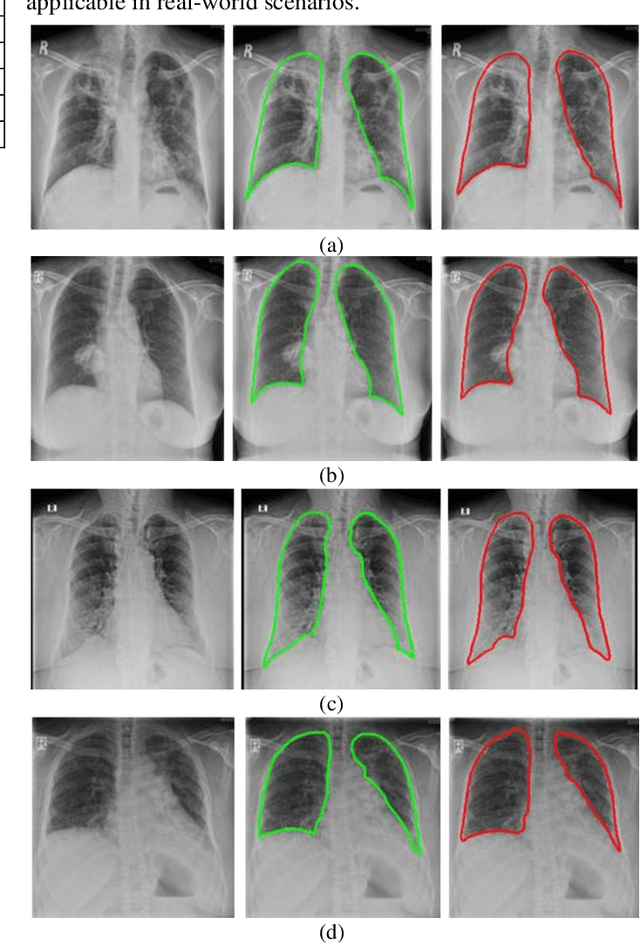
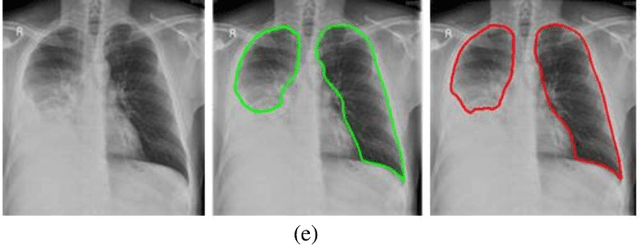
A chest radiograph, commonly called chest x-ray (CxR), plays a vital role in the diagnosis of various lung diseases, such as lung cancer, tuberculosis, pneumonia, and many more. Automated segmentation of the lungs is an important step to design a computer-aided diagnostic tool for examination of a CxR. Precise lung segmentation is considered extremely challenging because of variance in the shape of the lung caused by health issues, age, and gender. The proposed work investigates the use of an efficient deep convolutional neural network for accurate segmentation of lungs from CxR. We attempt an end to end DeepLabv3+ network which integrates DeepLab architecture, encoder-decoder, and dilated convolution for semantic lung segmentation with fast training and high accuracy. We experimented with the different pre-trained base networks: Resnet18 and Mobilenetv2, associated with the Deeplabv3+ model for performance analysis. The proposed approach does not require any pre-processing technique on chest x-ray images before being fed to a neural network. Morphological operations were used to remove false positives that occurred during semantic segmentation. We construct a CxR dataset of the Indian population that contain healthy and unhealthy CxRs of clinically confirmed patients of tuberculosis, chronic obstructive pulmonary disease, interstitial lung disease, pleural effusion, and lung cancer. The proposed method is tested on 688 images of our Indian CxR dataset including images with severe abnormal findings to validate its robustness. We also experimented on commonly used benchmark datasets such as Japanese Society of Radiological Technology; Montgomery County, USA; and Shenzhen, China for state-of-the-art comparison. The performance of our method is tested against techniques described in the literature and achieved the highest accuracy for lung segmentation on Indian and public datasets.
PerceptionGAN: Real-world Image Construction from Provided Text through Perceptual Understanding
Jul 02, 2020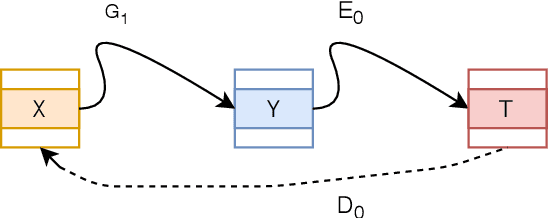
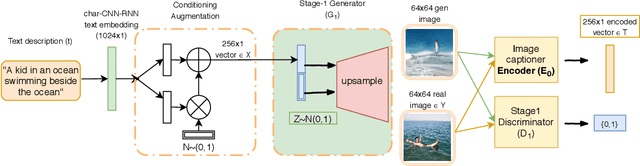
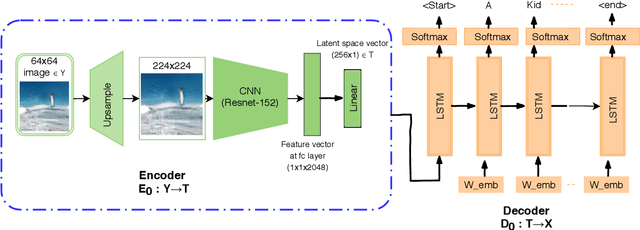
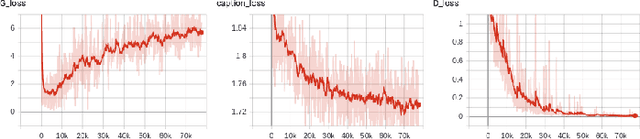
Generating an image from a provided descriptive text is quite a challenging task because of the difficulty in incorporating perceptual information (object shapes, colors, and their interactions) along with providing high relevancy related to the provided text. Current methods first generate an initial low-resolution image, which typically has irregular object shapes, colors, and interaction between objects. This initial image is then improved by conditioning on the text. However, these methods mainly address the problem of using text representation efficiently in the refinement of the initially generated image, while the success of this refinement process depends heavily on the quality of the initially generated image, as pointed out in the DM-GAN paper. Hence, we propose a method to provide good initialized images by incorporating perceptual understanding in the discriminator module. We improve the perceptual information at the first stage itself, which results in significant improvement in the final generated image. In this paper, we have applied our approach to the novel StackGAN architecture. We then show that the perceptual information included in the initial image is improved while modeling image distribution at multiple stages. Finally, we generated realistic multi-colored images conditioned by text. These images have good quality along with containing improved basic perceptual information. More importantly, the proposed method can be integrated into the pipeline of other state-of-the-art text-based-image-generation models to generate initial low-resolution images. We also worked on improving the refinement process in StackGAN by augmenting the third stage of the generator-discriminator pair in the StackGAN architecture. Our experimental analysis and comparison with the state-of-the-art on a large but sparse dataset MS COCO further validate the usefulness of our proposed approach.
* Proceedings of IEEE International Conference on Imaging, Vision & Pattern Recognition, (IVPR 2020, Japan)
Image fusion using symmetric skip autoencodervia an Adversarial Regulariser
Jun 04, 2020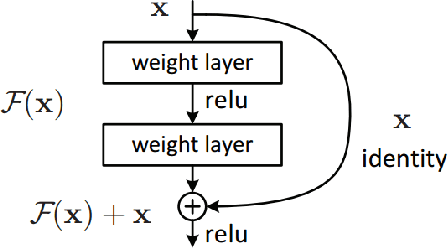
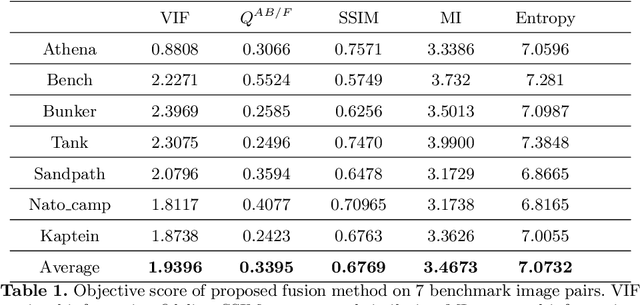
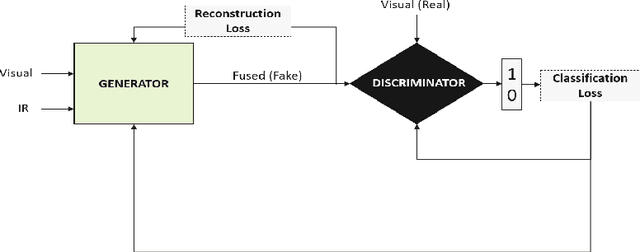
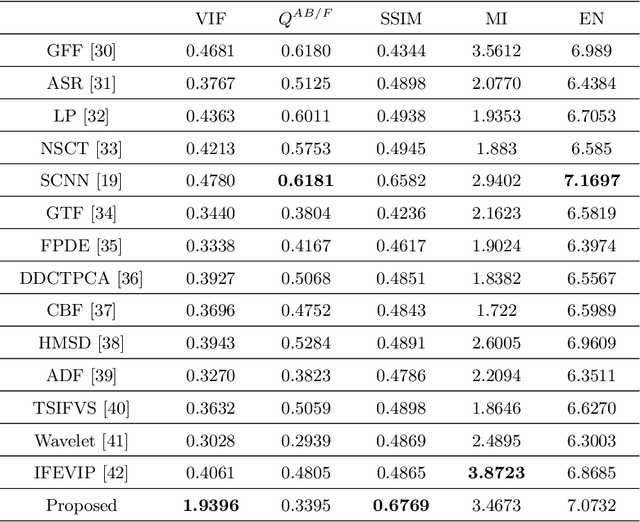
It is a challenging task to extract the best of both worlds by combining the spatial characteristics of a visible image and the spectral content of an infrared image. In this work, we propose a spatially constrained adversarial autoencoder that extracts deep features from the infrared and visible images to obtain a more exhaustive and global representation. In this paper, we propose a residual autoencoder architecture, regularised by a residual adversarial network, to generate a more realistic fused image. The residual module serves as primary building for the encoder, decoder and adversarial network, as an add on the symmetric skip connections perform the functionality of embedding the spatial characteristics directly from the initial layers of encoder structure to the decoder part of the network. The spectral information in the infrared image is incorporated by adding the feature maps over several layers in the encoder part of the fusion structure, which makes inference on both the visual and infrared images separately. In order to efficiently optimize the parameters of the network, we propose an adversarial regulariser network which would perform supervised learning on the fused image and the original visual image.
Deep feature fusion for self-supervised monocular depth prediction
May 16, 2020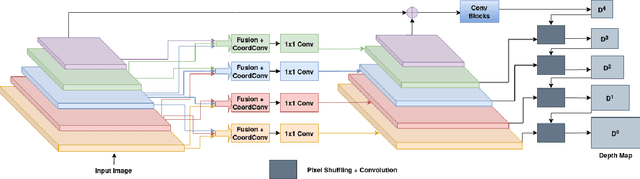
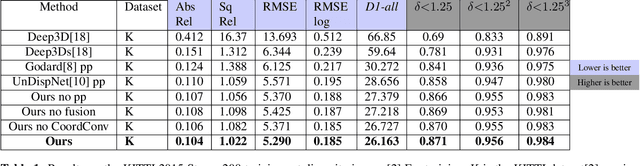

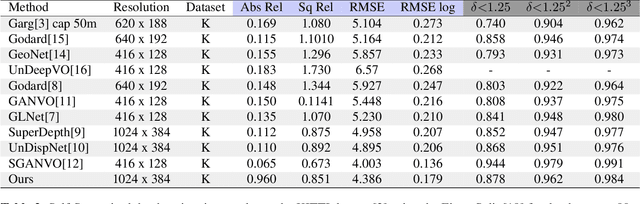
Recent advances in end-to-end unsupervised learning has significantly improved the performance of monocular depth prediction and alleviated the requirement of ground truth depth. Although a plethora of work has been done in enforcing various structural constraints by incorporating multiple losses utilising smoothness, left-right consistency, regularisation and matching surface normals, a few of them take into consideration multi-scale structures present in real world images. Most works utilise a VGG16 or ResNet50 model pre-trained on ImageNet weights for predicting depth. We propose a deep feature fusion method utilising features at multiple scales for learning self-supervised depth from scratch. Our fusion network selects features from both upper and lower levels at every level in the encoder network, thereby creating multiple feature pyramid sub-networks that are fed to the decoder after applying the CoordConv solution. We also propose a refinement module learning higher scale residual depth from a combination of higher level deep features and lower level residual depth using a pixel shuffling framework that super-resolves lower level residual depth. We select the KITTI dataset for evaluation and show that our proposed architecture can produce better or comparable results in depth prediction.
Compressive sensing based privacy for fall detection
Jan 10, 2020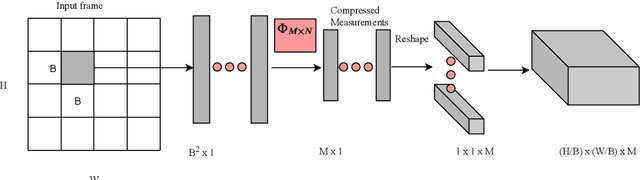

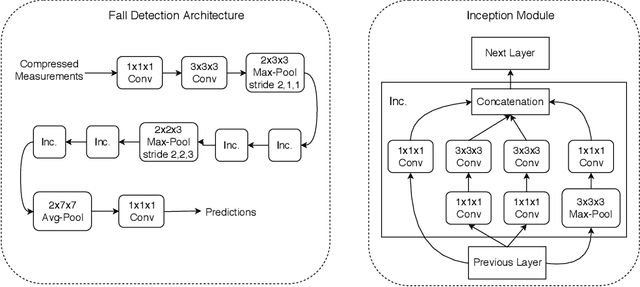
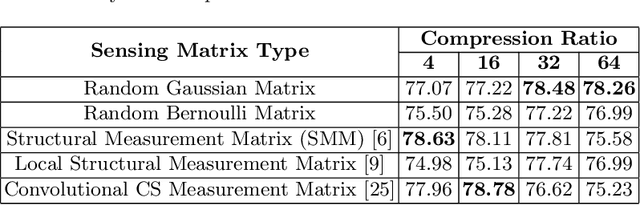
Fall detection holds immense importance in the field of healthcare, where timely detection allows for instant medical assistance. In this context, we propose a 3D ConvNet architecture which consists of 3D Inception modules for fall detection. The proposed architecture is a custom version of Inflated 3D (I3D) architecture, that takes compressed measurements of video sequence as spatio-temporal input, obtained from compressive sensing framework, rather than video sequence as input, as in the case of I3D convolutional neural network. This is adopted since privacy raises a huge concern for patients being monitored through these RGB cameras. The proposed framework for fall detection is flexible enough with respect to a wide variety of measurement matrices. Ten action classes randomly selected from Kinetics-400 with no fall examples, are employed to train our 3D ConvNet post compressive sensing with different types of sensing matrices on the original video clips. Our results show that 3D ConvNet performance remains unchanged with different sensing matrices. Also, the performance obtained with Kinetics pre-trained 3D ConvNet on compressively sensed fall videos from benchmark datasets is better than the state-of-the-art techniques.
Aerial multi-object tracking by detection using deep association networks
Sep 04, 2019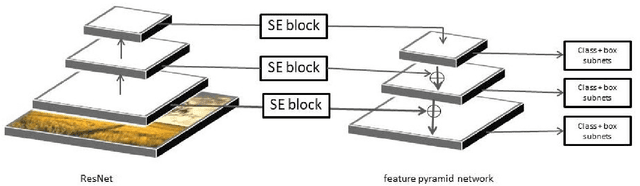
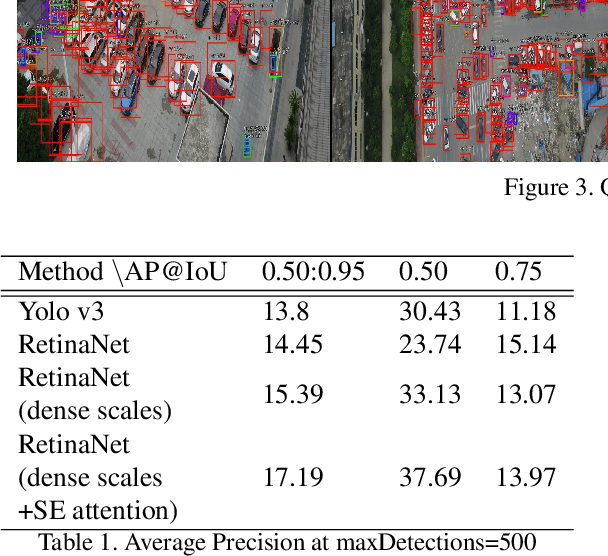
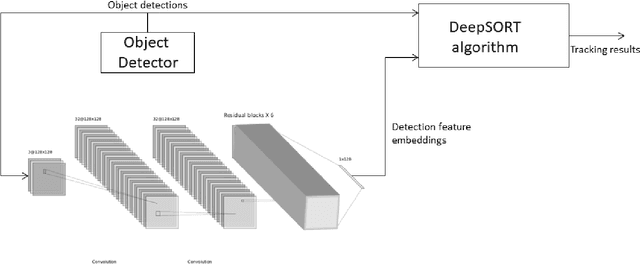
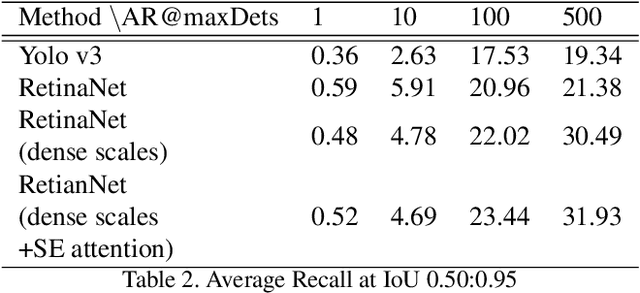
A lot a research is focused on object detection and it has achieved significant advances with deep learning techniques in recent years. Inspite of the existing research, these algorithms are not usually optimal for dealing with sequences or images captured by drone-based platforms, due to various challenges such as view point change, scales, density of object distribution and occlusion. In this paper, we develop a model for detection of objects in drone images using the VisDrone2019 DET dataset. Using the RetinaNet model as our base, we modify the anchor scales to better handle the detection of dense distribution and small size of the objects. We explicitly model the channel interdependencies by using "Squeeze-and-Excitation" (SE) blocks that adaptively recalibrates channel-wise feature responses. This helps to bring significant improvements in performance at a slight additional computational cost. Using this architecture for object detection, we build a custom DeepSORT network for object detection on the VisDrone2019 MOT dataset by training a custom Deep Association network for the algorithm.
Learning Activation Functions: A new paradigm for understanding Neural Networks
Jul 08, 2019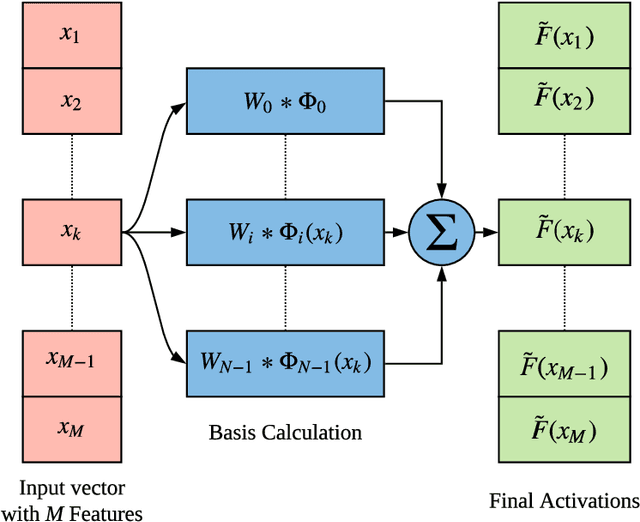

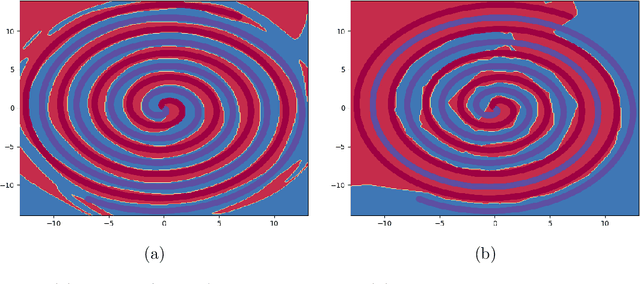

The scope of research in the domain of activation functions remains limited and centered around improving the ease of optimization or generalization quality of neural networks (NNs). However, to develop a deeper understanding of deep learning, it becomes important to look at the non linear component of NNs more carefully. In this paper, we aim to provide a generic form of activation function along with appropriate mathematical grounding so as to allow for insights into the working of NNs in future. We propose ``Self-Learnable Activation Functions'' (SLAF), which are learned during training and are capable of approximating most of the existing activation functions. SLAF is given as a weighted sum of pre-defined basis elements which can serve for a good approximation of the optimal activation function. The coefficients for these basis elements allow a search in the entire space of continuous functions (consisting of all the conventional activations). We propose various training routines which can be used to achieve performance with SLAF equipped neural networks (SLNNs). We prove that SLNNs can approximate any neural network with lipschitz continuous activations, to any arbitrary error highlighting their capacity and possible equivalence with standard NNs. Also, SLNNs can be completely represented as a collections of finite degree polynomial upto the very last layer obviating several hyper parameters like width and depth. Since the optimization of SLNNs is still a challenge, we show that using SLAF along with standard activations (like ReLU) can provide performance improvements with only a small increase in number of parameters.
Few Shot Speaker Recognition using Deep Neural Networks
Apr 17, 2019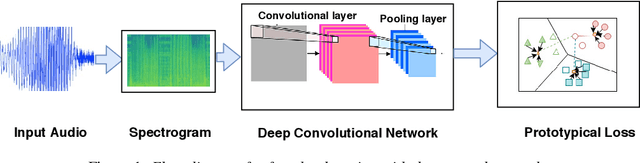
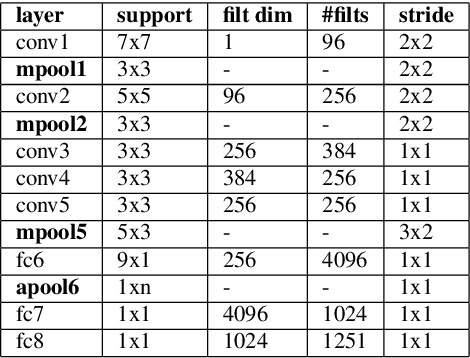

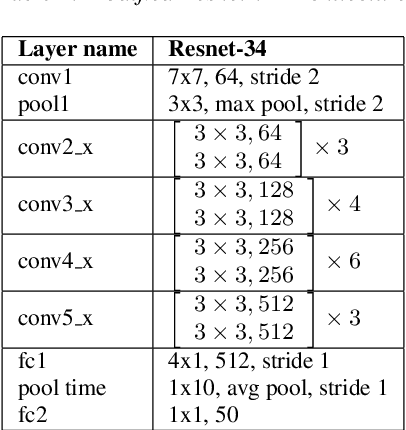
The recent advances in deep learning are mostly driven by availability of large amount of training data. However, availability of such data is not always possible for specific tasks such as speaker recognition where collection of large amount of data is not possible in practical scenarios. Therefore, in this paper, we propose to identify speakers by learning from only a few training examples. To achieve this, we use a deep neural network with prototypical loss where the input to the network is a spectrogram. For output, we project the class feature vectors into a common embedding space, followed by classification. Further, we show the effectiveness of capsule net in a few shot learning setting. To this end, we utilize an auto-encoder to learn generalized feature embeddings from class-specific embeddings obtained from capsule network. We provide exhaustive experiments on publicly available datasets and competitive baselines, demonstrating the superiority and generalization ability of the proposed few shot learning pipelines.
VayuAnukulani: Adaptive Memory Networks for Air Pollution Forecasting
Apr 08, 2019
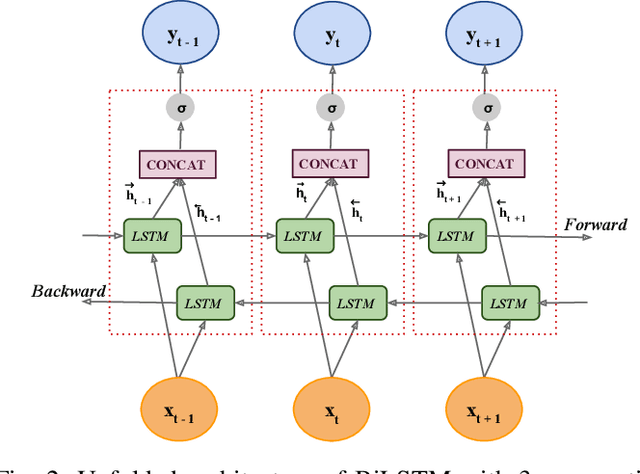
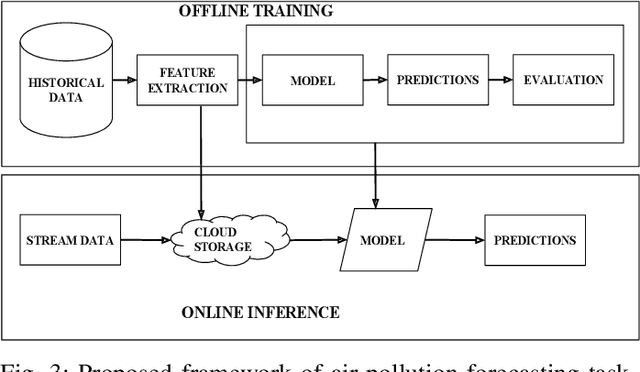
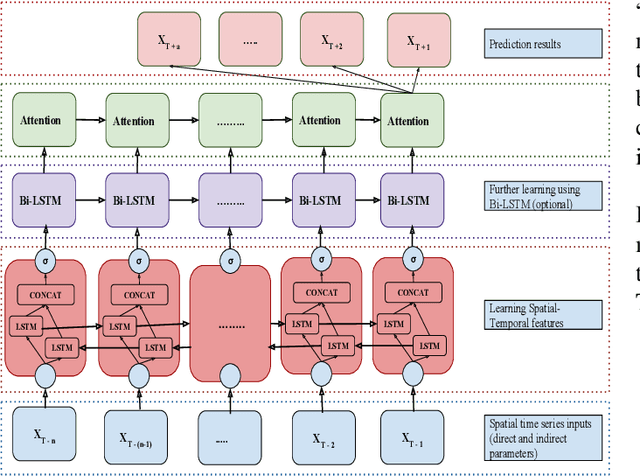
Air pollution is the leading environmental health hazard globally due to various sources which include factory emissions, car exhaust and cooking stoves. As a precautionary measure, air pollution forecast serves as the basis for taking effective pollution control measures, and accurate air pollution forecasting has become an important task. In this paper, we forecast fine-grained ambient air quality information for 5 prominent locations in Delhi based on the historical and real-time ambient air quality and meteorological data reported by Central Pollution Control board. We present VayuAnukulani system, a novel end-to-end solution to predict air quality for next 24 hours by estimating the concentration and level of different air pollutants including nitrogen dioxide ($NO_2$), particulate matter ($PM_{2.5}$ and $PM_{10}$) for Delhi. Extensive experiments on data sources obtained in Delhi demonstrate that the proposed adaptive attention based Bidirectional LSTM Network outperforms several baselines for classification and regression models. The accuracy of the proposed adaptive system is $\sim 15 - 20\%$ better than the same offline trained model. We compare the proposed methodology on several competing baselines, and show that the network outperforms conventional methods by $\sim 3 - 5 \%$.
DSAL-GAN: Denoising based Saliency Prediction with Generative Adversarial Networks
Apr 02, 2019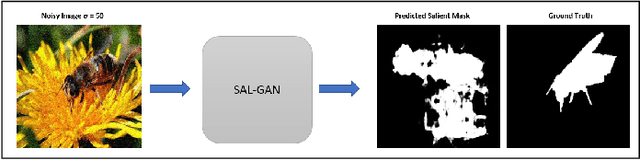

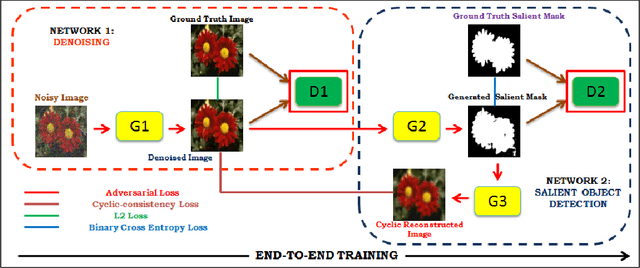

Synthesizing high quality saliency maps from noisy images is a challenging problem in computer vision and has many practical applications. Samples generated by existing techniques for saliency detection cannot handle the noise perturbations smoothly and fail to delineate the salient objects present in the given scene. In this paper, we present a novel end-to-end coupled Denoising based Saliency Prediction with Generative Adversarial Network (DSAL-GAN) framework to address the problem of salient object detection in noisy images. DSAL-GAN consists of two generative adversarial-networks (GAN) trained end-to-end to perform denoising and saliency prediction altogether in a holistic manner. The first GAN consists of a generator which denoises the noisy input image, and in the discriminator counterpart we check whether the output is a denoised image or ground truth original image. The second GAN predicts the saliency maps from raw pixels of the input denoised image using a data-driven metric based on saliency prediction method with adversarial loss. Cycle consistency loss is also incorporated to further improve salient region prediction. We demonstrate with comprehensive evaluation that the proposed framework outperforms several baseline saliency models on various performance benchmarks.