 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix Adaptive Synthesis Filter for Uniform Filter Bank
Sep 22, 2022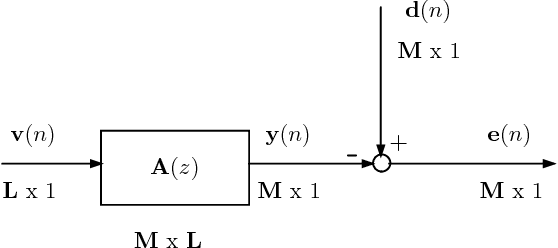
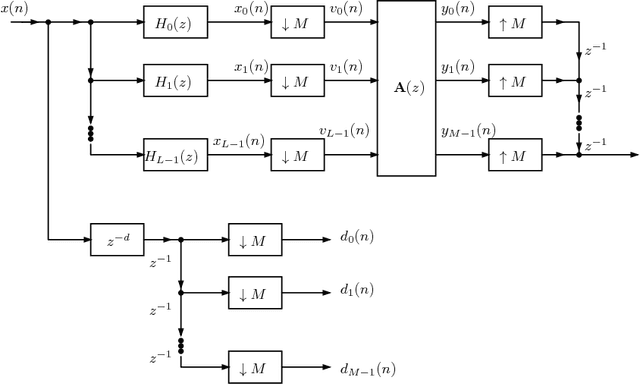
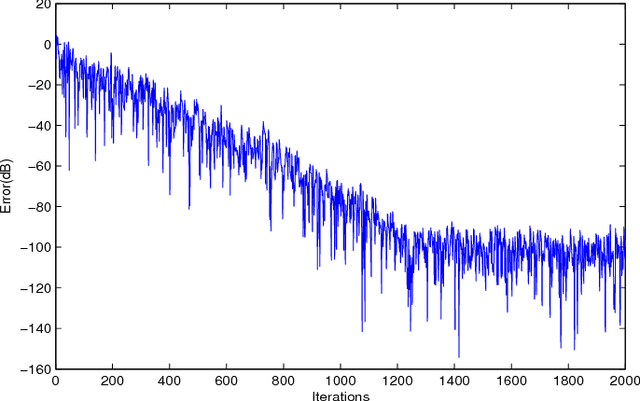
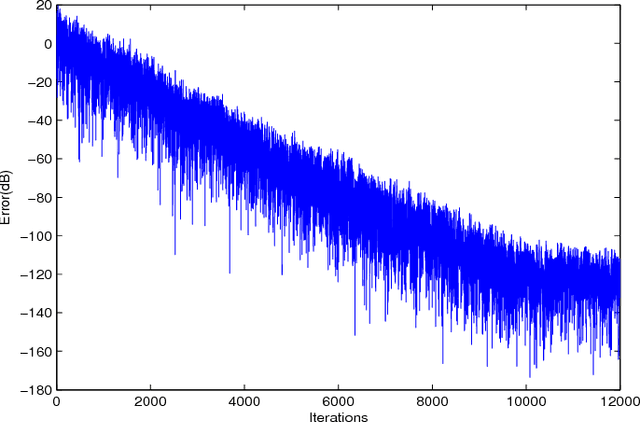
In this paper, we use a matrix adaptive filter as the synthesis stage of a Uniform Filter Bank (UFB) to reconstruct the input signal. We first develop the mathematical theory behind it by applying the model of optimal filtering at the synthesis stage of the UFB and obtaining an expression for the matrix Wiener filter. We have developed a theorem which we use to simplify the expression further. In the absence of required information about the analysis stage, we use adaptive filtering to arrive at the Wiener solution. We use the Least Mean Square (LMS) algorithm to update the filter coefficients. Through experimental results, we find that the adaptive filter is convergent for a stable Wiener filter.
Robust Prototypical Few-Shot Organ Segmentation with Regularized Neural-ODEs
Aug 26, 2022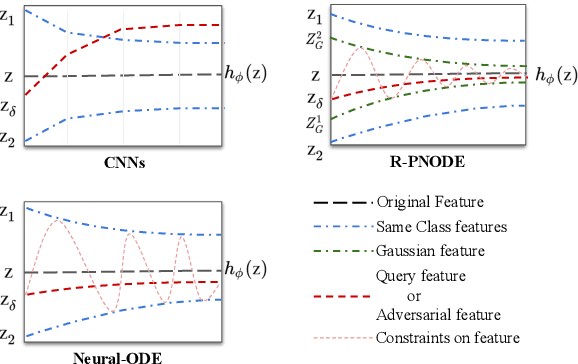
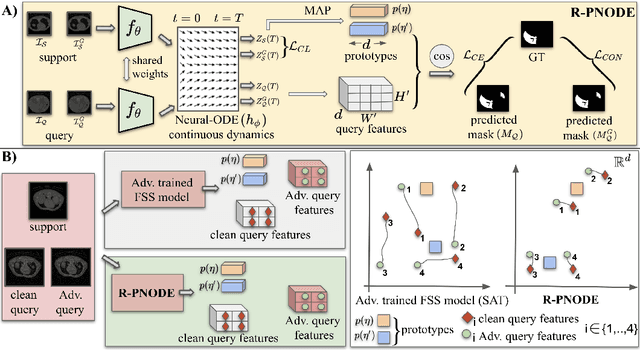


Despite the tremendous progress made by deep learning models in image semantic segmentation, they typically require large annotated examples, and increasing attention is being diverted to problem settings like Few-Shot Learning (FSL) where only a small amount of annotation is needed for generalisation to novel classes. This is especially seen in medical domains where dense pixel-level annotations are expensive to obtain. In this paper, we propose Regularized Prototypical Neural Ordinary Differential Equation (R-PNODE), a method that leverages intrinsic properties of Neural-ODEs, assisted and enhanced by additional cluster and consistency losses to perform Few-Shot Segmentation (FSS) of organs. R-PNODE constrains support and query features from the same classes to lie closer in the representation space thereby improving the performance over the existing Convolutional Neural Network (CNN) based FSS methods. We further demonstrate that while many existing Deep CNN based methods tend to be extremely vulnerable to adversarial attacks, R-PNODE exhibits increased adversarial robustness for a wide array of these attacks. We experiment with three publicly available multi-organ segmentation datasets in both in-domain and cross-domain FSS settings to demonstrate the efficacy of our method. In addition, we perform experiments with seven commonly used adversarial attacks in various settings to demonstrate R-PNODE's robustness. R-PNODE outperforms the baselines for FSS by significant margins and also shows superior performance for a wide array of attacks varying in intensity and design.
MaskMTL: Attribute prediction in masked facial images with deep multitask learning
Jan 11, 2022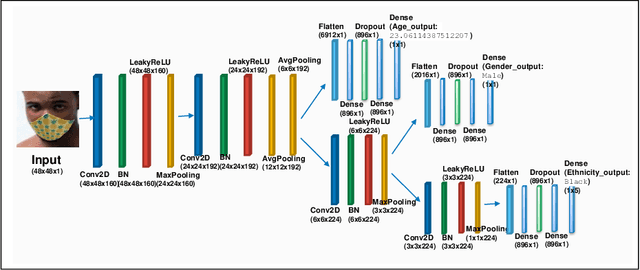
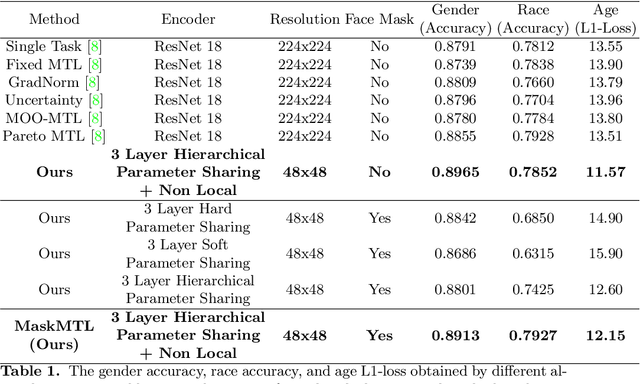

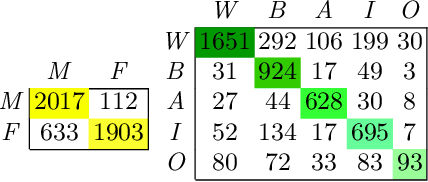
Predicting attributes in the landmark free facial images is itself a challenging task which gets further complicated when the face gets occluded due to the usage of masks. Smart access control gates which utilize identity verification or the secure login to personal electronic gadgets may utilize face as a biometric trait. Particularly, the Covid-19 pandemic increasingly validates the essentiality of hygienic and contactless identity verification. In such cases, the usage of masks become more inevitable and performing attribute prediction helps in segregating the target vulnerable groups from community spread or ensuring social distancing for them in a collaborative environment. We create a masked face dataset by efficiently overlaying masks of different shape, size and textures to effectively model variability generated by wearing mask. This paper presents a deep Multi-Task Learning (MTL) approach to jointly estimate various heterogeneous attributes from a single masked facial image. Experimental results on benchmark face attribute UTKFace dataset demonstrate that the proposed approach supersedes in performance to other competing techniques. The source code is available at https://github.com/ritikajha/Attribute-prediction-in-masked-facial-images-with-deep-multitask-learning
Softmax Gradient Tampering: Decoupling the Backward Pass for Improved Fitting
Nov 24, 2021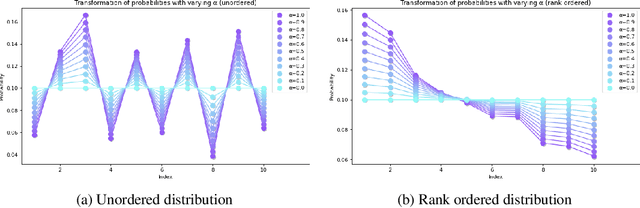
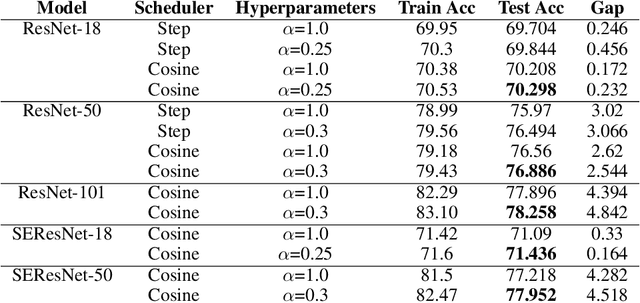
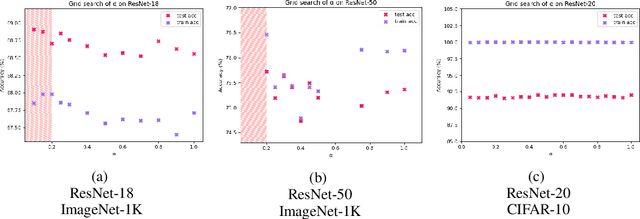

We introduce Softmax Gradient Tampering, a technique for modifying the gradients in the backward pass of neural networks in order to enhance their accuracy. Our approach transforms the predicted probability values using a power-based probability transformation and then recomputes the gradients in the backward pass. This modification results in a smoother gradient profile, which we demonstrate empirically and theoretically. We do a grid search for the transform parameters on residual networks. We demonstrate that modifying the softmax gradients in ConvNets may result in increased training accuracy, thus increasing the fit across the training data and maximally utilizing the learning capacity of neural networks. We get better test metrics and lower generalization gaps when combined with regularization techniques such as label smoothing. Softmax gradient tampering improves ResNet-50's test accuracy by $0.52\%$ over the baseline on the ImageNet dataset. Our approach is very generic and may be used across a wide range of different network architectures and datasets.
Estimation and Prediction of Deterministic Human Intent Signal to augment Haptic Glove aided Control of Robotic Hand
Oct 15, 2021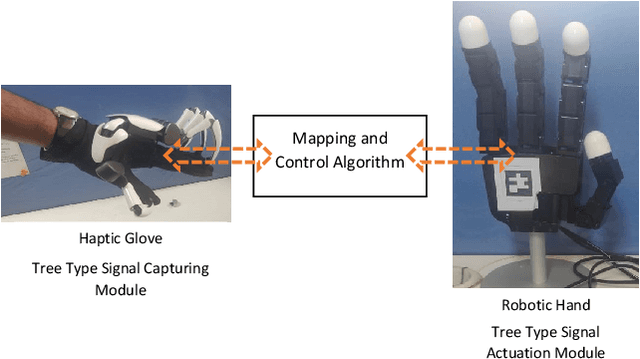
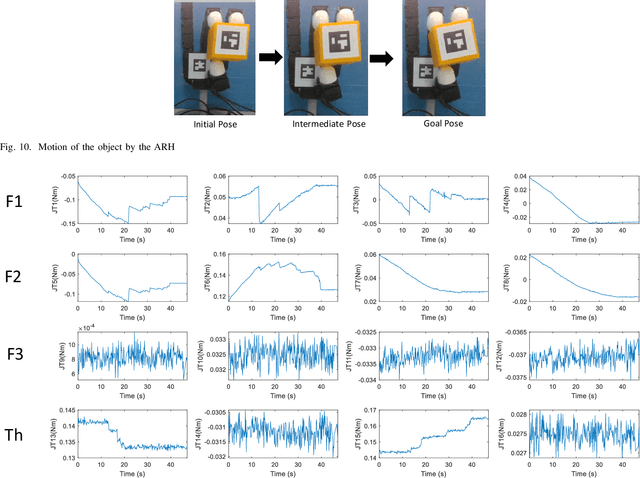
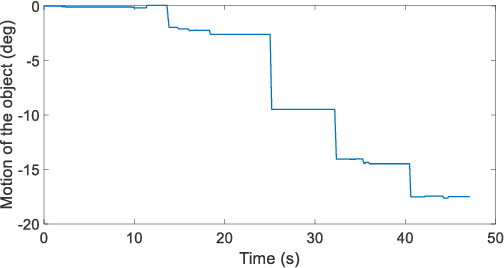
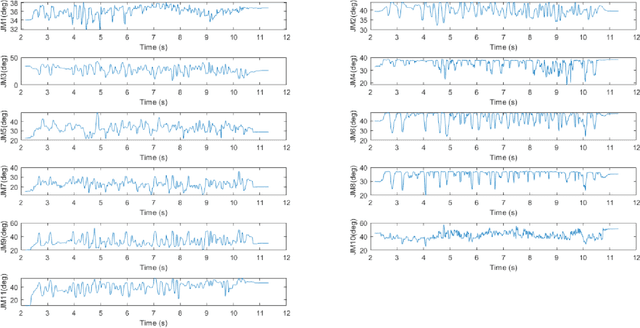
The paper focuses on Haptic Glove (HG) based control of a Robotic Hand (RH) executing in-hand manipulation. A control algorithm is presented to allow the RH relocate the object held to a goal pose. The motion signals for both the HG and the RH are high dimensional. The RH kinematics is usually different from the HG kinematics. The variability of kinematics of the two devices, added with the incomplete information about the human hand kinematics result in difficulty in direct mapping of the high dimensional motion signal of the HG to the RH. Hence, a method is proposed to estimate the human intent from the high dimensional HG motion signal and reconstruct the signal at the RH to ensure object relocation. It is also shown that the lag in synthesis of the motion signal of the human hand added with the control latency of the RH leads to a requirement of the prediction of the human intent signal. Then, a recurrent neural network (RNN) is proposed to predict the human intent signal ahead of time.
ADAADepth: Adapting Data Augmentation and Attention for Self-Supervised Monocular Depth Estimation
Mar 01, 2021
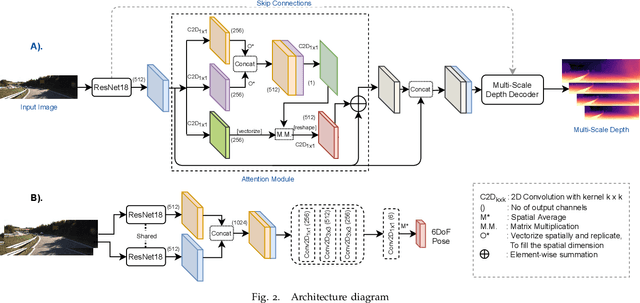
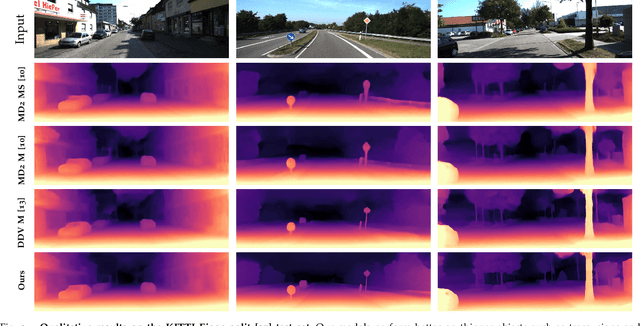
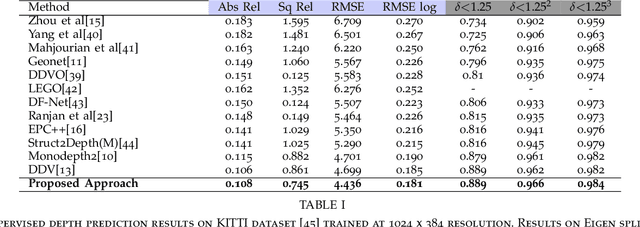
Self-supervised learning of depth has been a highly studied topic of research as it alleviates the requirement of having ground truth annotations for predicting depth. Depth is learnt as an intermediate solution to the task of view synthesis, utilising warped photometric consistency. Although it gives good results when trained using stereo data, the predicted depth is still sensitive to noise, illumination changes and specular reflections. Also, occlusion can be tackled better by learning depth from a single camera. We propose ADAA, utilising depth augmentation as depth supervision for learning accurate and robust depth. We propose a relational self-attention module that learns rich contextual features and further enhances depth results. We also optimize the auto-masking strategy across all losses by enforcing L1 regularisation over mask. Our novel progressive training strategy first learns depth at a lower resolution and then progresses to the original resolution with slight training. We utilise a ResNet18 encoder, learning features for prediction of both depth and pose. We evaluate our predicted depth on the standard KITTI driving dataset and achieve state-of-the-art results for monocular depth estimation whilst having significantly lower number of trainable parameters in our deep learning framework. We also evaluate our model on Make3D dataset showing better generalization than other methods.
One Shot Audio to Animated Video Generation
Feb 19, 2021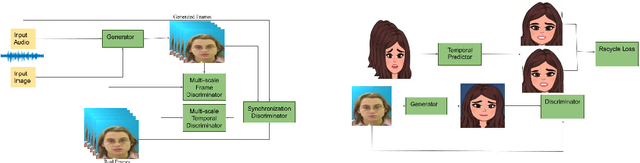


We consider the challenging problem of audio to animated video generation. We propose a novel method OneShotAu2AV to generate an animated video of arbitrary length using an audio clip and a single unseen image of a person as an input. The proposed method consists of two stages. In the first stage, OneShotAu2AV generates the talking-head video in the human domain given an audio and a person's image. In the second stage, the talking-head video from the human domain is converted to the animated domain. The model architecture of the first stage consists of spatially adaptive normalization based multi-level generator and multiple multilevel discriminators along with multiple adversarial and non-adversarial losses. The second stage leverages attention based normalization driven GAN architecture along with temporal predictor based recycle loss and blink loss coupled with lipsync loss, for unsupervised generation of animated video. In our approach, the input audio clip is not restricted to any specific language, which gives the method multilingual applicability. OneShotAu2AV can generate animated videos that have: (a) lip movements that are in sync with the audio, (b) natural facial expressions such as blinks and eyebrow movements, (c) head movements. Experimental evaluation demonstrates superior performance of OneShotAu2AV as compared to U-GAT-IT and RecycleGan on multiple quantitative metrics including KID(Kernel Inception Distance), Word error rate, blinks/sec
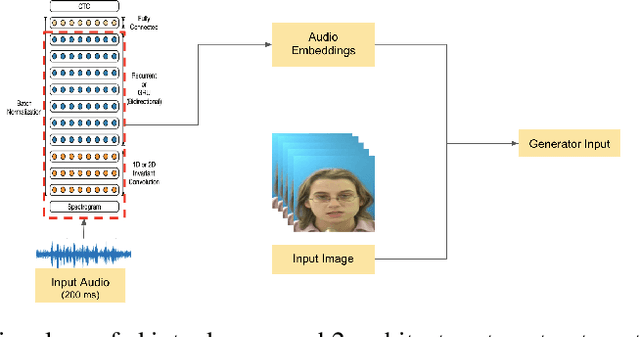
Multi Modal Adaptive Normalization for Audio to Video Generation
Dec 14, 2020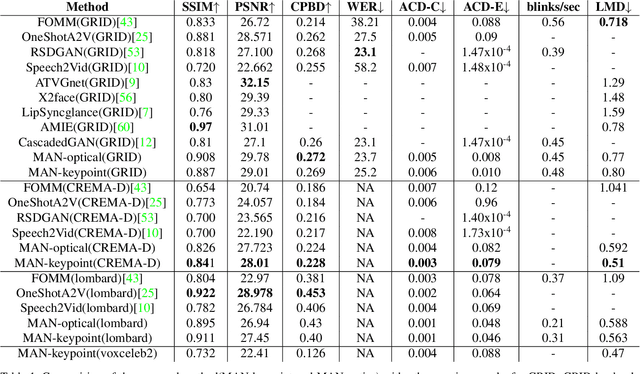

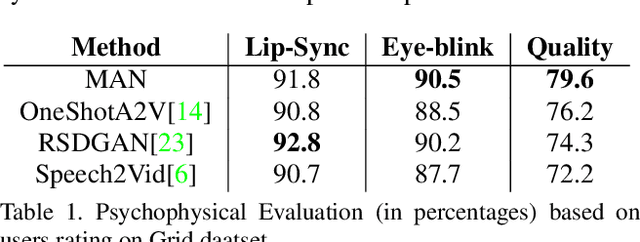
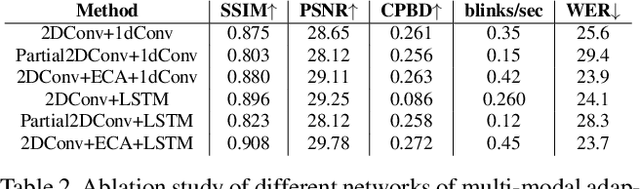
Speech-driven facial video generation has been a complex problem due to its multi-modal aspects namely audio and video domain. The audio comprises lots of underlying features such as expression, pitch, loudness, prosody(speaking style) and facial video has lots of variability in terms of head movement, eye blinks, lip synchronization and movements of various facial action units along with temporal smoothness. Synthesizing highly expressive facial videos from the audio input and static image is still a challenging task for generative adversarial networks. In this paper, we propose a multi-modal adaptive normalization(MAN) based architecture to synthesize a talking person video of arbitrary length using as input: an audio signal and a single image of a person. The architecture uses the multi-modal adaptive normalization, keypoint heatmap predictor, optical flow predictor and class activation map[58] based layers to learn movements of expressive facial components and hence generates a highly expressive talking-head video of the given person. The multi-modal adaptive normalization uses the various features of audio and video such as Mel spectrogram, pitch, energy from audio signals and predicted keypoint heatmap/optical flow and a single image to learn the respective affine parameters to generate highly expressive video. Experimental evaluation demonstrates superior performance of the proposed method as compared to Realistic Speech-Driven Facial Animation with GANs(RSDGAN) [53], Speech2Vid [10], and other approaches, on multiple quantitative metrics including: SSIM (structural similarity index), PSNR (peak signal to noise ratio), CPBD (image sharpness), WER(word error rate), blinks/sec and LMD(landmark distance). Further, qualitative evaluation and Online Turing tests demonstrate the efficacy of our approach.
Few Shot Adaptive Normalization Driven Multi-Speaker Speech Synthesis
Dec 14, 2020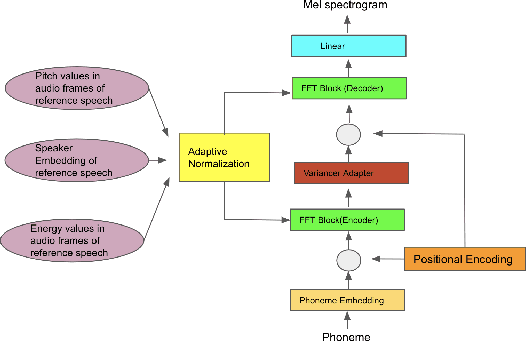

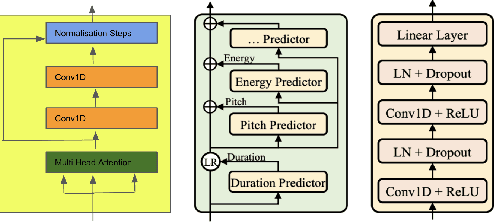
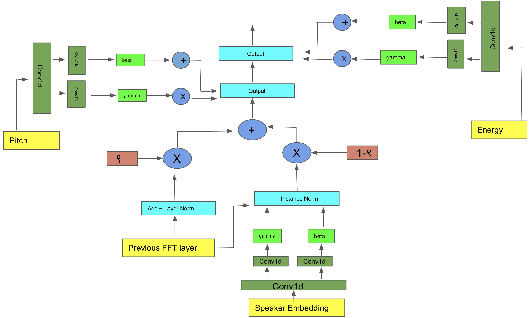
The style of the speech varies from person to person and every person exhibits his or her own style of speaking that is determined by the language, geography, culture and other factors. Style is best captured by prosody of a signal. High quality multi-speaker speech synthesis while considering prosody and in a few shot manner is an area of active research with many real-world applications. While multiple efforts have been made in this direction, it remains an interesting and challenging problem. In this paper, we present a novel few shot multi-speaker speech synthesis approach (FSM-SS) that leverages adaptive normalization architecture with a non-autoregressive multi-head attention model. Given an input text and a reference speech sample of an unseen person, FSM-SS can generate speech in that person's style in a few shot manner. Additionally, we demonstrate how the affine parameters of normalization help in capturing the prosodic features such as energy and fundamental frequency in a disentangled fashion and can be used to generate morphed speech output. We demonstrate the efficacy of our proposed architecture on multi-speaker VCTK and LibriTTS datasets, using multiple quantitative metrics that measure generated speech distortion and MoS, along with speaker embedding analysis of the generated speech vs the actual speech samples.
Deep Learning for Automated Screening of Tuberculosis from Indian Chest X-rays: Analysis and Update
Nov 19, 2020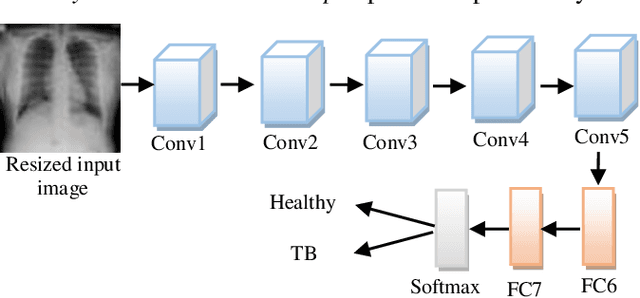
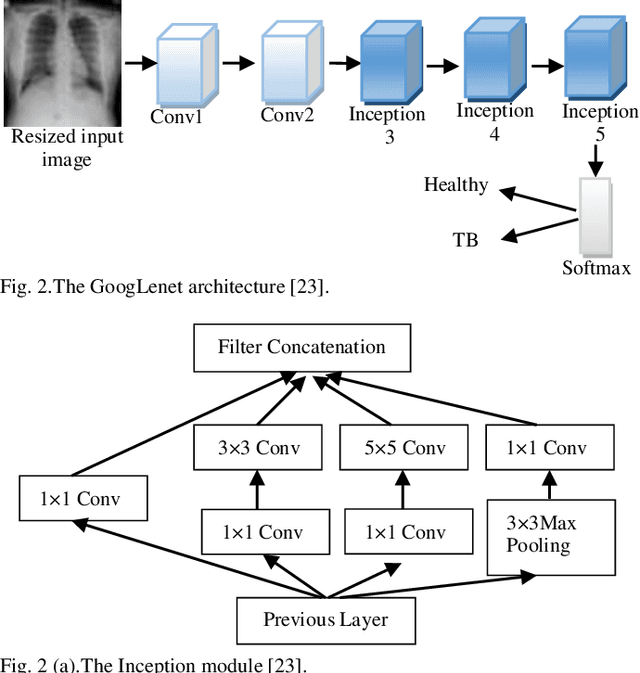
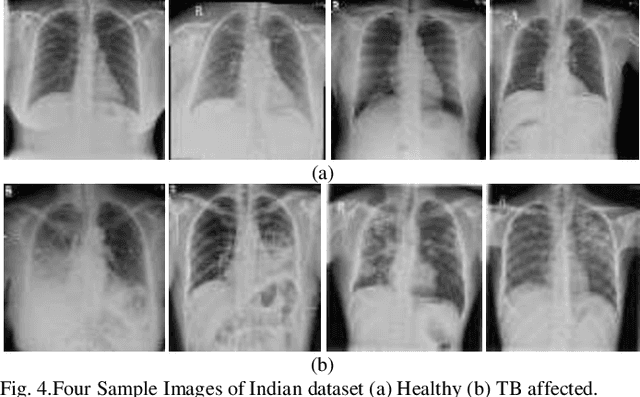
Background and Objective: Tuberculosis (TB) is a significant public health issue and a leading cause of death worldwide. Millions of deaths can be averted by early diagnosis and successful treatment of TB patients. Automated diagnosis of TB holds vast potential to assist medical experts in expediting and improving its diagnosis, especially in developing countries like India, where there is a shortage of trained medical experts and radiologists. To date, several deep learning based methods for automated detection of TB from chest radiographs have been proposed. However, the performance of a few of these methods on the Indian chest radiograph data set has been suboptimal, possibly due to different texture of the lungs on chest radiographs of Indian subjects compared to other countries. Thus deep learning for accurate and automated diagnosis of TB on Indian datasets remains an important subject of research. Methods: The proposed work explores the performance of convolutional neural networks (CNNs) for the diagnosis of TB in Indian chest x-ray images. Three different pre-trained neural network models, AlexNet, GoogLenet, and ResNet are used to classify chest x-ray images into healthy or TB infected. The proposed approach does not require any pre-processing technique. Also, other works use pre-trained NNs as a tool for crafting features and then apply standard classification techniques. However, we attempt an end to end NN model based diagnosis of TB from chest x-rays. The proposed visualization tool can also be used by radiologists in the screening of large datasets. Results: The proposed method achieved 93.40% accuracy with 98.60% sensitivity to diagnose TB for the Indian population. Conclusions: The performance of the proposed method is also tested against techniques described in the literature. The proposed method outperforms the state of art on Indian and Shenzhen datasets.