 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Efficient Hierarchical Goal-Conditioned Reinforcement Learning via Normalizing Flows
Feb 11, 2026Hierarchical goal-conditioned reinforcement learning (H-GCRL) provides a powerful framework for tackling complex, long-horizon tasks by decomposing them into structured subgoals. However, its practical adoption is hindered by poor data efficiency and limited policy expressivity, especially in offline or data-scarce regimes. In this work, Normalizing flow-based hierarchical implicit Q-learning (NF-HIQL), a novel framework that replaces unimodal gaussian policies with expressive normalizing flow policies at both the high- and low-levels of the hierarchy is introduced. This design enables tractable log-likelihood computation, efficient sampling, and the ability to model rich multimodal behaviors. New theoretical guarantees are derived, including explicit KL-divergence bounds for Real-valued non-volume preserving (RealNVP) policies and PAC-style sample efficiency results, showing that NF-HIQL preserves stability while improving generalization. Empirically, NF-HIQL is evaluted across diverse long-horizon tasks in locomotion, ball-dribbling, and multi-step manipulation from OGBench. NF-HIQL consistently outperforms prior goal-conditioned and hierarchical baselines, demonstrating superior robustness under limited data and highlighting the potential of flow-based architectures for scalable, data-efficient hierarchical reinforcement learning.
Towards Improved Generalization in Financial Markets with Synthetic Data Generation
May 24, 2019

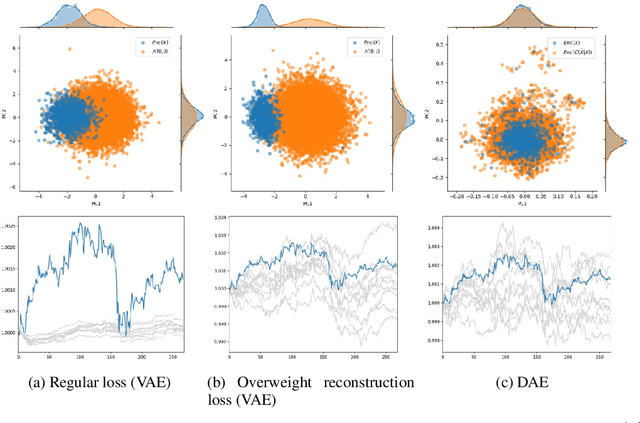

Training deep learning models that generalize well to live deployment is a challenging problem in the financial markets. The challenge arises because of high dimensionality, limited observations, changing data distributions, and a low signal-to-noise ratio. High dimensionality can be dealt with using robust feature selection or dimensionality reduction, but limited observations often result in a model that overfits due to the large parameter space of most deep neural networks. We propose a generative model for financial time series, which allows us to train deep learning models on millions of simulated paths. We show that our generative model is able to create realistic paths that embed the underlying structure of the markets in a way stochastic processes cannot.
Approximating Poker Probabilities with Deep Learning
Aug 23, 2018



Many poker systems, whether created with heuristics or machine learning, rely on the probability of winning as a key input. However calculating the precise probability using combinatorics is an intractable problem, so instead we approximate it. Monte Carlo simulation is an effective technique that can be used to approximate the probability that a player will win and/or tie a hand. However, without the use of a memory-intensive lookup table or a supercomputer, it becomes infeasible to run millions of times when training an agent with self-play. To combat the space-time tradeoff, we use deep learning to approximate the probabilities obtained from the Monte Carlo simulation with high accuracy. The learned model proves to be a lightweight alternative to Monte Carlo simulation, which ultimately allows us to use the probabilities as inputs during self-play efficiently. The source code and optimized neural network can be found at https://github.com/brandinho/Poker-Probability-Approximation