 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCHG: Tri-Trust Conditioned Heterogeneous Graph Learning for Reliable Dynamic Trust Prediction
Jun 15, 2026Trust prediction infers latent user-user trust relations and provides important support for social recommendation, fake-review and manipulation detection, and risk identification. Graph neural networks have become a prominent approach to trust prediction because of their ability to learn network structures and complex trust dependencies. However, existing methods often rely on a unified representation of trust signals and do not disentangle heterogeneous trust evidence into separate evidence channels, failing to exploit the distinct roles that different evidence channels should play during trust modeling. To address this gap, this paper argues that trust evidence should not be treated as an undifferentiated input, but should be decomposed and used as functional control factors over graph propagation. We propose TCHG, a tri-trust conditioned heterogeneous graph learning framework that decomposes trust evidence into three channels and assigns them distinct functional roles in propagation: entity reliability governs message admission, interaction-behavior reliability modulates propagation strength, and contextual trust adjusts the propagation mode through context-conditioned operator selection. Since the three evidence channels evolve at different temporal scales, TCHG maintains independent temporal states with non-uniform decay rates to prevent rapidly changing contextual signals from overwriting slowly accumulated entity reliability. It further predicts trust probability and calibrates the output probability, improving predictive confidence under sparse or conflicting evidence. Extensive experiments on multiple public trust datasets show that TCHG achieves effective and reliable trust prediction compared with representative trust prediction and heterogeneous graph baselines.
EIT: Efficiently Lead Inductive Biases to ViT
Mar 14, 2022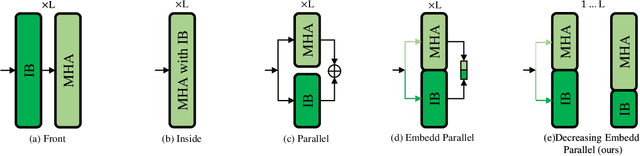
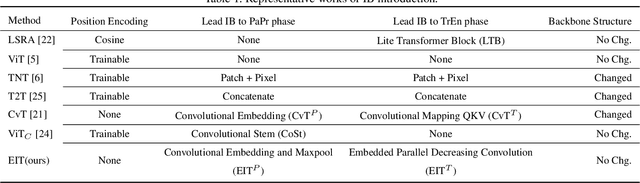
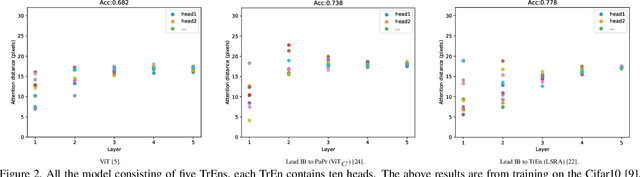

Vision Transformer (ViT) depends on properties similar to the inductive bias inherent in Convolutional Neural Networks to perform better on non-ultra-large scale datasets. In this paper, we propose an architecture called Efficiently lead Inductive biases to ViT (EIT), which can effectively lead the inductive biases to both phases of ViT. In the Patches Projection phase, a convolutional max-pooling structure is used to produce overlapping patches. In the Transformer Encoder phase, we design a novel inductive bias introduction structure called decreasing convolution, which is introduced parallel to the multi-headed attention module, by which the embedding's different channels are processed respectively. In four popular small-scale datasets, compared with ViT, EIT has an accuracy improvement of 12.6% on average with fewer parameters and FLOPs. Compared with ResNet, EIT exhibits higher accuracy with only 17.7% parameters and fewer FLOPs. Finally, ablation studies show that the EIT is efficient and does not require position embedding. Code is coming soon: https://github.com/MrHaiPi/EIT