 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Energy Efficiency and Robustness of tinyML Computer Vision using Log-Gradient Input Images
Mar 04, 2022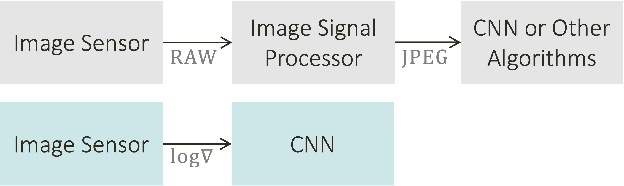
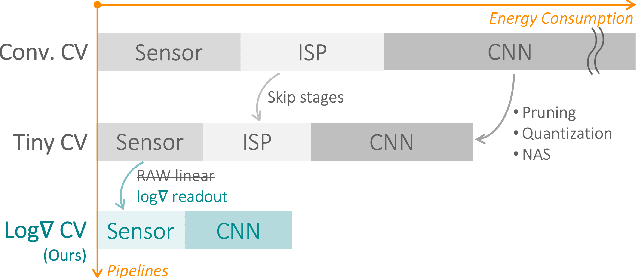
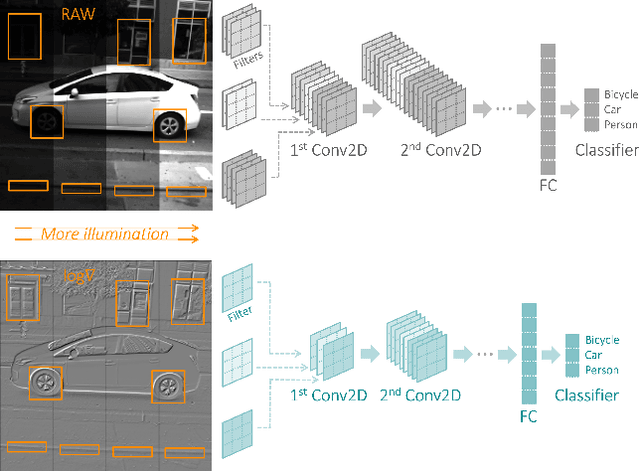

This paper studies the merits of applying log-gradient input images to convolutional neural networks (CNNs) for tinyML computer vision (CV). We show that log gradients enable: (i) aggressive 1.5-bit quantization of first-layer inputs, (ii) potential CNN resource reductions, and (iii) inherent robustness to illumination changes (1.7% accuracy loss across 1/32...8 brightness variation vs. up to 10% for JPEG). We establish these results using the PASCAL RAW image data set and through a combination of experiments using neural architecture search and a fixed three-layer network. The latter reveal that training on log-gradient images leads to higher filter similarity, making the CNN more prunable. The combined benefits of aggressive first-layer quantization, CNN resource reductions, and operation without tight exposure control and image signal processing (ISP) are helpful for pushing tinyML CV toward its ultimate efficiency limits.
Low-Rank Training of Deep Neural Networks for Emerging Memory Technology
Sep 08, 2020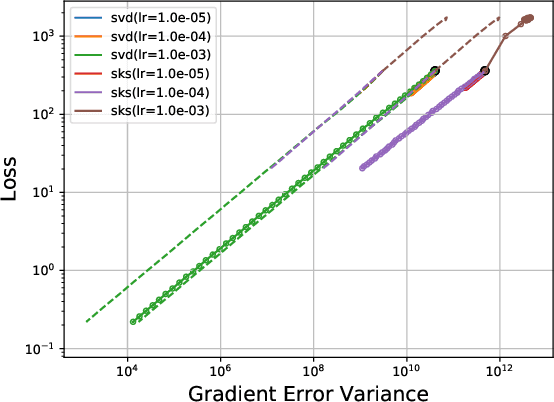
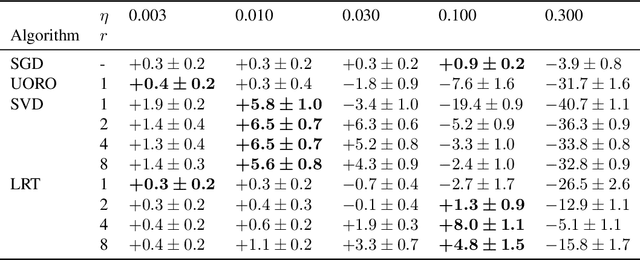
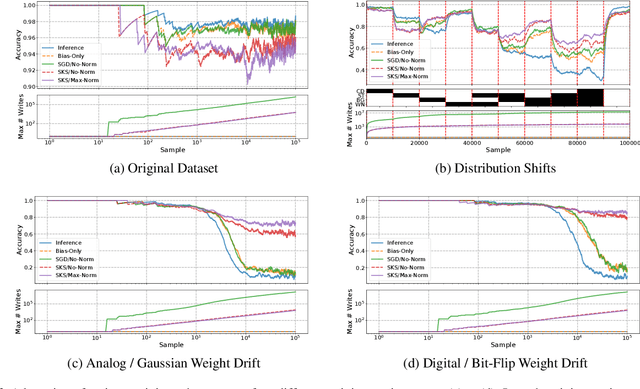
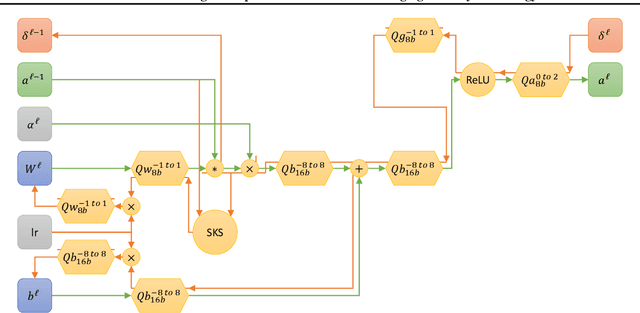
The recent success of neural networks for solving difficult decision talrt has incentivized incorporating smart decision making "at the edge." However, this work has traditionally focused on neural network inference, rather than training, due to memory and compute limitations, especially in emerging non-volatile memory systems, where writes are energetically costly and reduce lifespan. Yet, the ability to train at the edge is becoming increasingly important as it enables real-time adaptability to device drift and environmental variation, user customization, and federated learning across devices. In this work, we address two key challenges for training on edge devices with non-volatile memory: low write density and low auxiliary memory. We present a low-rank training scheme that addresses these challenges while maintaining computational efficiency. We then demonstrate the technique on a representative convolutional neural network across several adaptation problems, where it out-performs standard SGD both in accuracy and in number of weight writes.
Separating the Effects of Batch Normalization on CNN Training Speed and Stability Using Classical Adaptive Filter Theory
Feb 25, 2020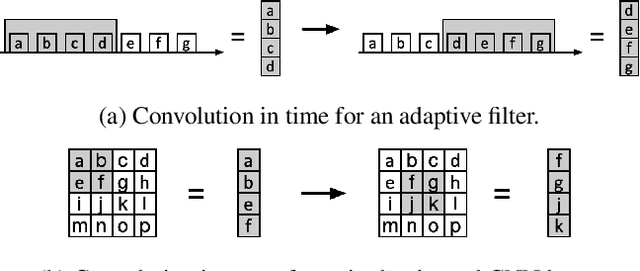
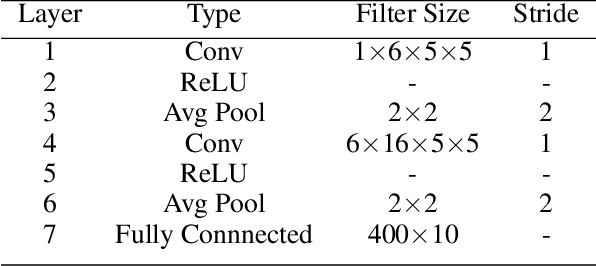
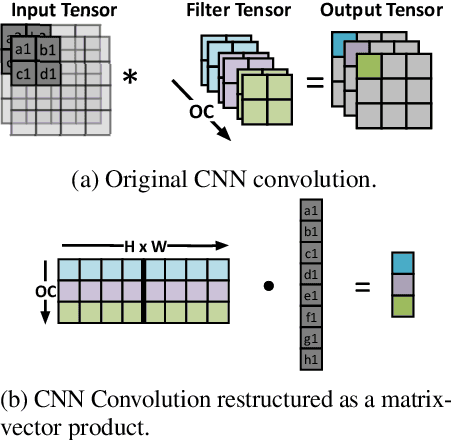
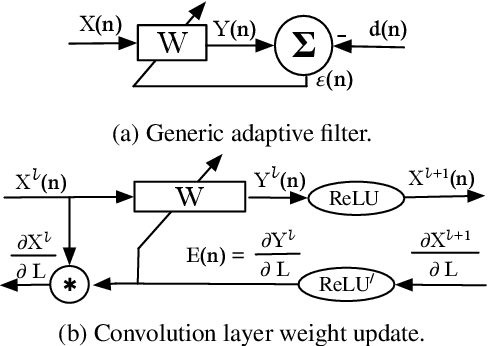
Batch Normalization (BatchNorm) is commonly used in Convolutional Neural Networks (CNNs) to improve training speed and stability. However, there is still limited consensus on why this technique is effective. This paper uses concepts from the traditional adaptive filter domain to provide insight into the dynamics and inner workings of BatchNorm. First, we show that the convolution weight updates have natural modes whose stability and convergence speed are tied to the eigenvalues of the input autocorrelation matrices, which are controlled by BatchNorm through the convolution layers' channel-wise structure. Furthermore, our experiments demonstrate that the speed and stability benefits are distinct effects. At low learning rates, it is BatchNorm's amplification of the smallest eigenvalues that improves convergence speed, while at high learning rates, it is BatchNorm's suppression of the largest eigenvalues that ensures stability. Lastly, we prove that in the first training step, when normalization is needed most, BatchNorm satisfies the same optimization as Normalized Least Mean Square (NLMS), while it continues to approximate this condition in subsequent steps. The analyses provided in this paper lay the groundwork for gaining further insight into the operation of modern neural network structures using adaptive filter theory.
BinarEye: An Always-On Energy-Accuracy-Scalable Binary CNN Processor With All Memory On Chip in 28nm CMOS
Apr 16, 2018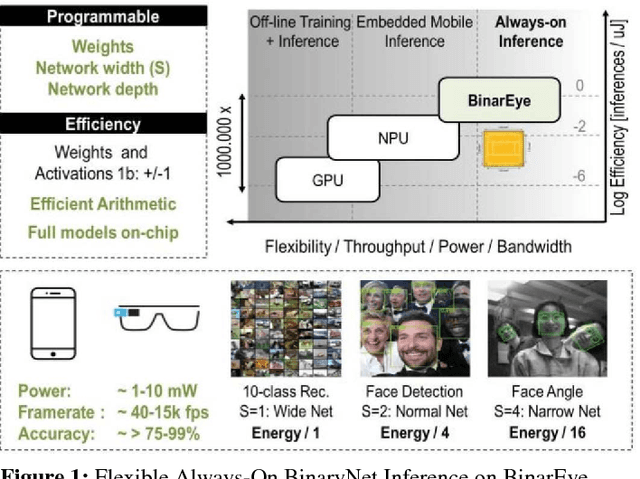
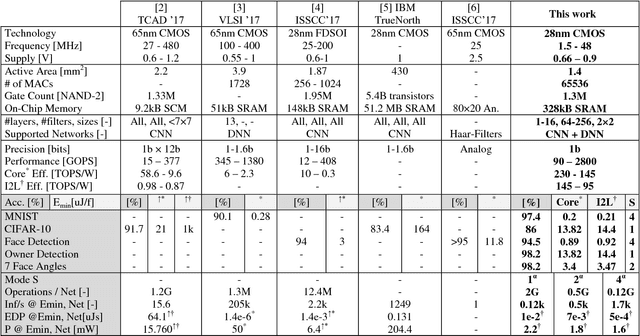
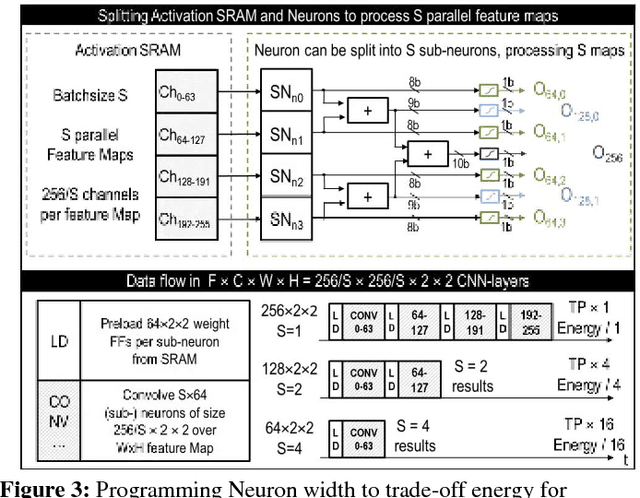
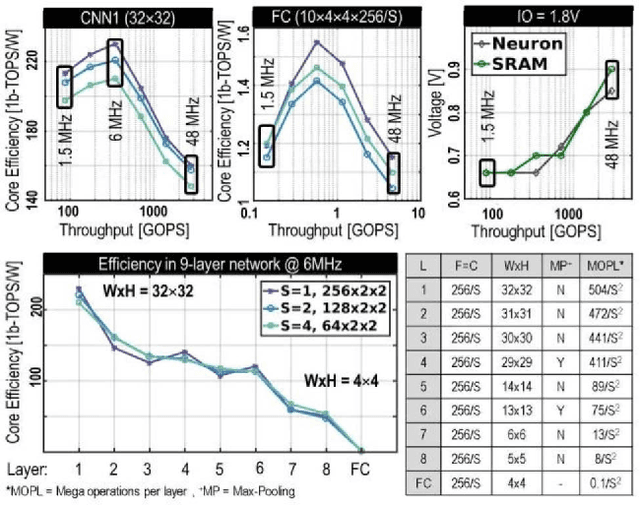
This paper introduces BinarEye: a digital processor for always-on Binary Convolutional Neural Networks. The chip maximizes data reuse through a Neuron Array exploiting local weight Flip-Flops. It stores full network models and feature maps and hence requires no off-chip bandwidth, which leads to a 230 1b-TOPS/W peak efficiency. Its 3 levels of flexibility - (a) weight reconfiguration, (b) a programmable network depth and (c) a programmable network width - allow trading energy for accuracy depending on the task's requirements. BinarEye's full system input-to-label energy consumption ranges from 14.4uJ/f for 86% CIFAR-10 and 98% owner recognition down to 0.92uJ/f for 94% face detection at up to 1700 frames per second. This is 3-12-70x more efficient than the state-of-the-art at on-par accuracy.
Convolutional Neural Networks using Logarithmic Data Representation
Mar 17, 2016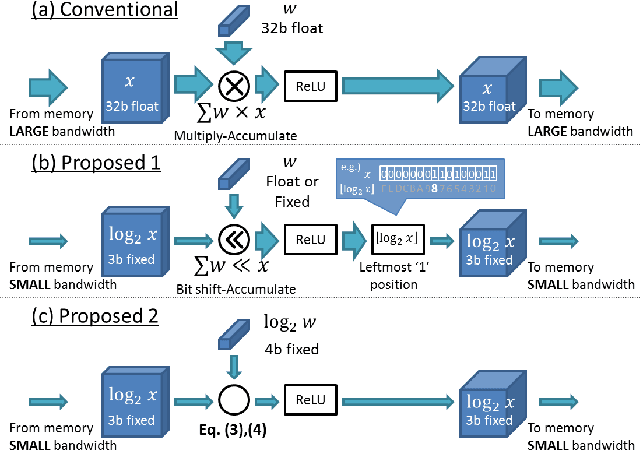
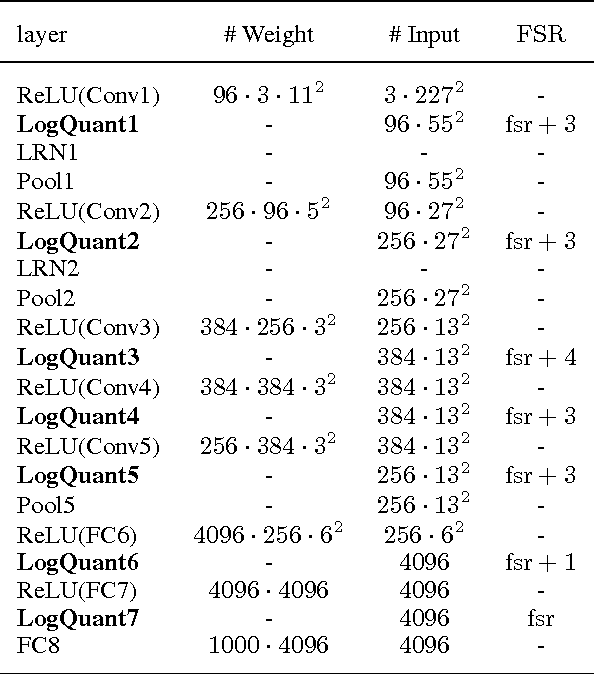
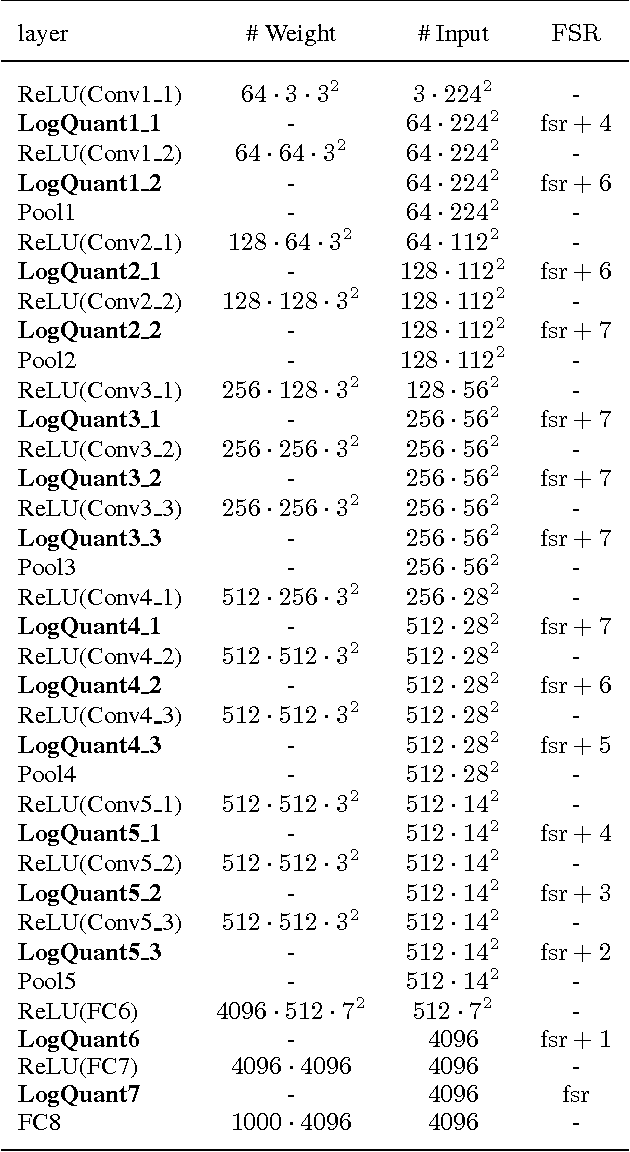
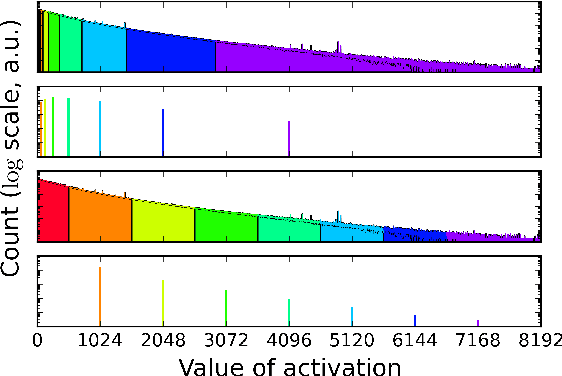
Recent advances in convolutional neural networks have considered model complexity and hardware efficiency to enable deployment onto embedded systems and mobile devices. For example, it is now well-known that the arithmetic operations of deep networks can be encoded down to 8-bit fixed-point without significant deterioration in performance. However, further reduction in precision down to as low as 3-bit fixed-point results in significant losses in performance. In this paper we propose a new data representation that enables state-of-the-art networks to be encoded to 3 bits with negligible loss in classification performance. To perform this, we take advantage of the fact that the weights and activations in a trained network naturally have non-uniform distributions. Using non-uniform, base-2 logarithmic representation to encode weights, communicate activations, and perform dot-products enables networks to 1) achieve higher classification accuracies than fixed-point at the same resolution and 2) eliminate bulky digital multipliers. Finally, we propose an end-to-end training procedure that uses log representation at 5-bits, which achieves higher final test accuracy than linear at 5-bits.