 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning on Heterogenous Data using Chest CT
Mar 23, 2023Large data have accelerated advances in AI. While it is well known that population differences from genetics, sex, race, diet, and various environmental factors contribute significantly to disease, AI studies in medicine have largely focused on locoregional patient cohorts with less diverse data sources. Such limitation stems from barriers to large-scale data share in medicine and ethical concerns over data privacy. Federated learning (FL) is one potential pathway for AI development that enables learning across hospitals without data share. In this study, we show the results of various FL strategies on one of the largest and most diverse COVID-19 chest CT datasets: 21 participating hospitals across five continents that comprise >10,000 patients with >1 million images. We present three techniques: Fed Averaging (FedAvg), Incremental Institutional Learning (IIL), and Cyclical Incremental Institutional Learning (CIIL). We also propose an FL strategy that leverages synthetically generated data to overcome class imbalances and data size disparities across centers. We show that FL can achieve comparable performance to Centralized Data Sharing (CDS) while maintaining high performance across sites with small, underrepresented data. We investigate the strengths and weaknesses for all technical approaches on this heterogeneous dataset including the robustness to non-Independent and identically distributed (non-IID) diversity of data. We also describe the sources of data heterogeneity such as age, sex, and site locations in the context of FL and show how even among the correctly labeled populations, disparities can arise due to these biases.
NanoBatch DPSGD: Exploring Differentially Private learning on ImageNet with low batch sizes on the IPU
Sep 24, 2021
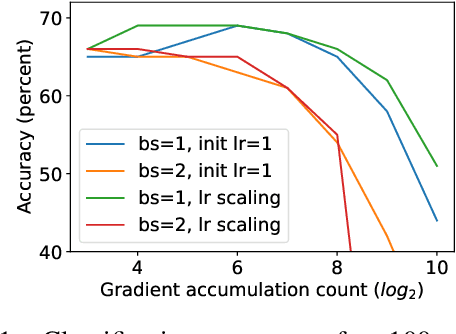
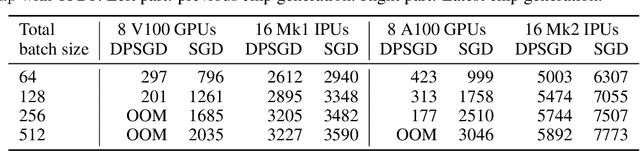

Differentially private SGD (DPSGD) has recently shown promise in deep learning. However, compared to non-private SGD, the DPSGD algorithm places computational overheads that can undo the benefit of batching in GPUs. Microbatching is a standard method to alleviate this and is fully supported in the TensorFlow Privacy library (TFDP). However, this technique, while improving training times also reduces the quality of the gradients and degrades the classification accuracy. Recent works that for example use the JAX framework show promise in also alleviating this but still show degradation in throughput from non-private to private SGD on CNNs, and have not yet shown ImageNet implementations. In our work, we argue that low batch sizes using group normalization on ResNet-50 can yield high accuracy and privacy on Graphcore IPUs. This enables DPSGD training of ResNet-50 on ImageNet in just 6 hours (100 epochs) on an IPU-POD16 system.
Convolutional Neural Networks using Logarithmic Data Representation
Mar 17, 2016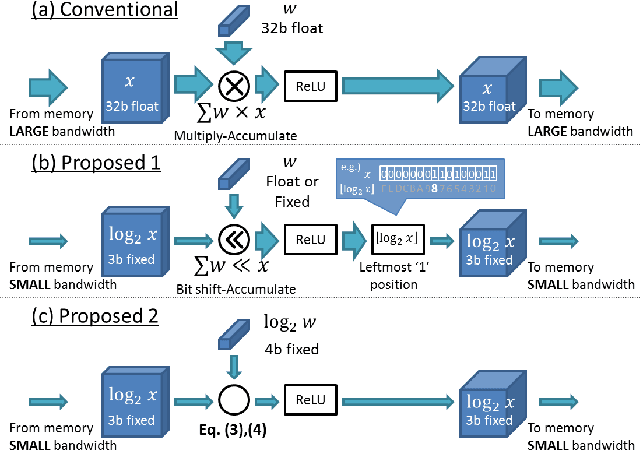
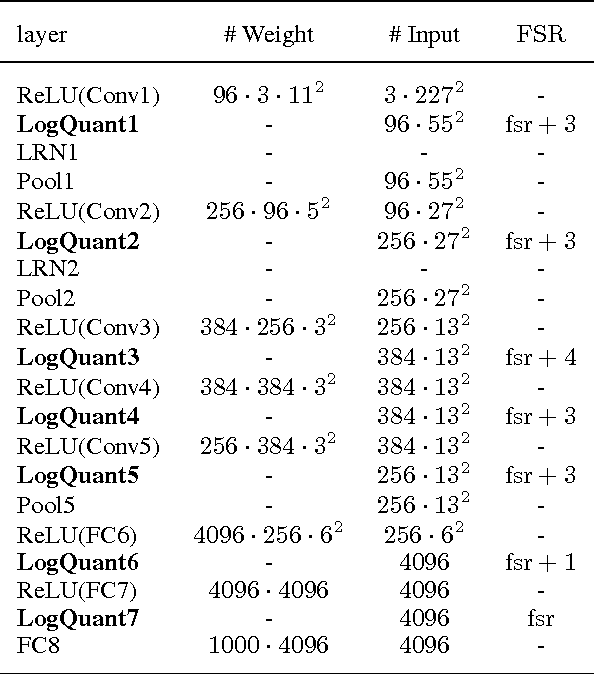
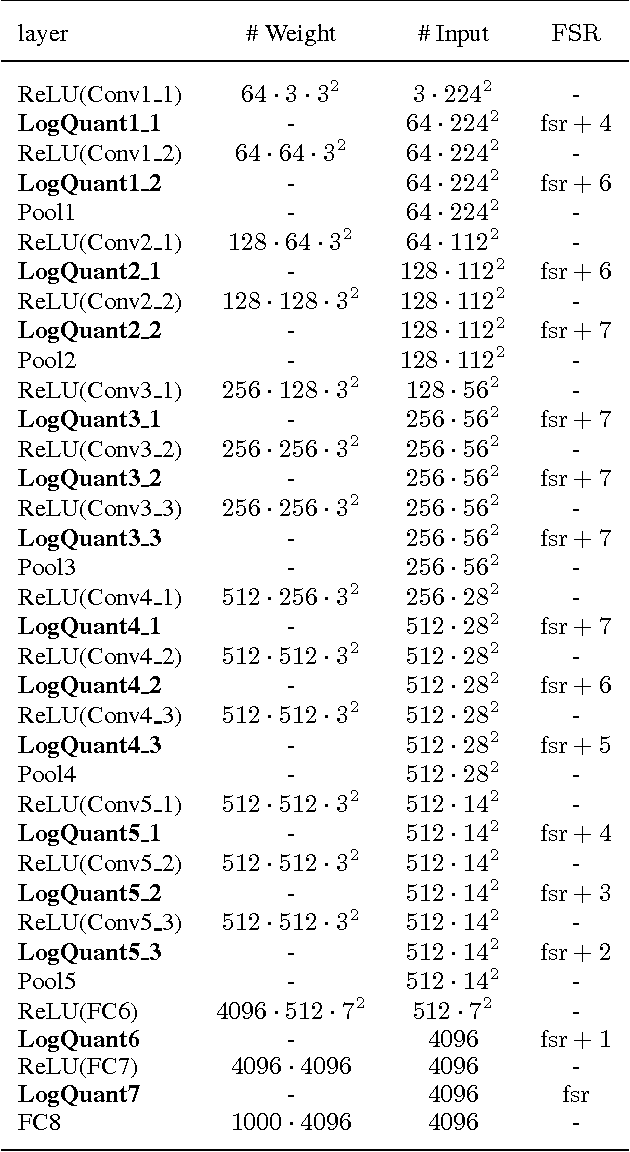
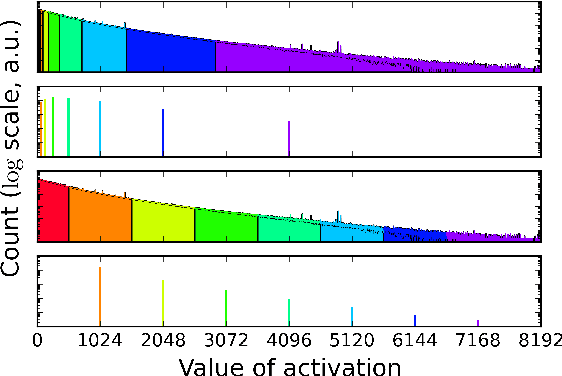
Recent advances in convolutional neural networks have considered model complexity and hardware efficiency to enable deployment onto embedded systems and mobile devices. For example, it is now well-known that the arithmetic operations of deep networks can be encoded down to 8-bit fixed-point without significant deterioration in performance. However, further reduction in precision down to as low as 3-bit fixed-point results in significant losses in performance. In this paper we propose a new data representation that enables state-of-the-art networks to be encoded to 3 bits with negligible loss in classification performance. To perform this, we take advantage of the fact that the weights and activations in a trained network naturally have non-uniform distributions. Using non-uniform, base-2 logarithmic representation to encode weights, communicate activations, and perform dot-products enables networks to 1) achieve higher classification accuracies than fixed-point at the same resolution and 2) eliminate bulky digital multipliers. Finally, we propose an end-to-end training procedure that uses log representation at 5-bits, which achieves higher final test accuracy than linear at 5-bits.