 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Semantic Segmentation from Multiple Datasets with Label Shifts
Feb 28, 2022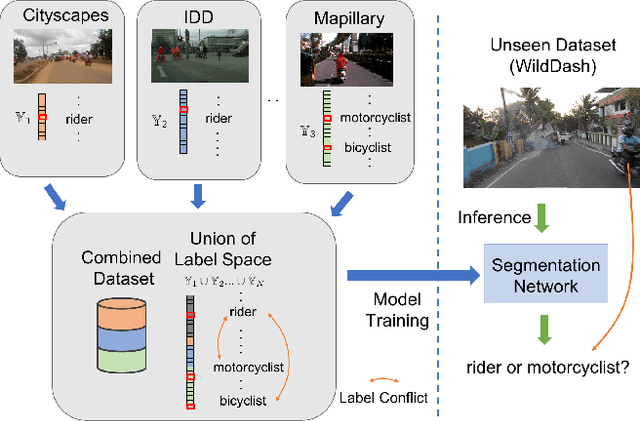
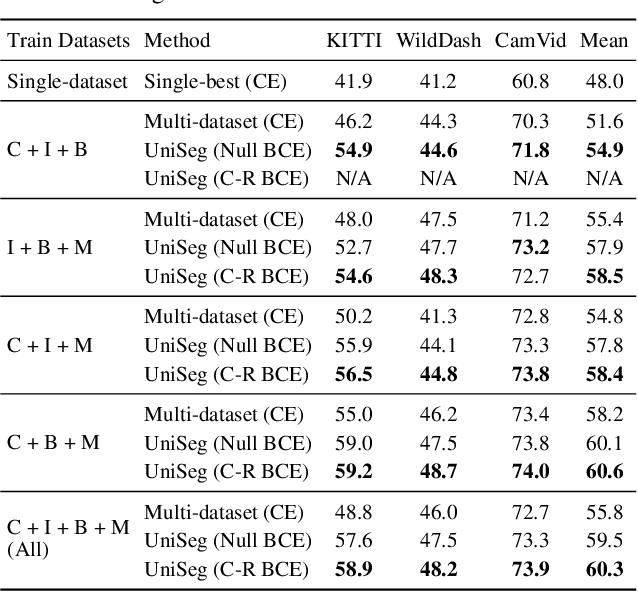
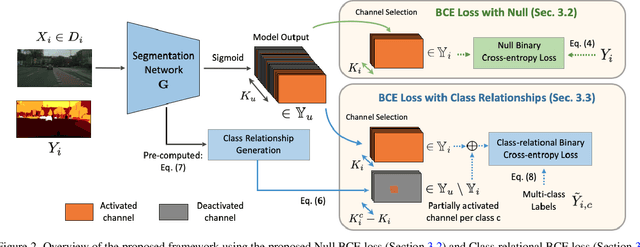
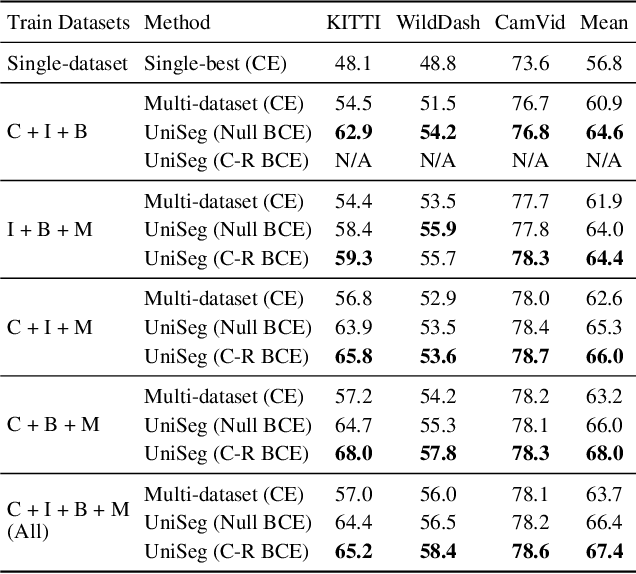
With increasing applications of semantic segmentation, numerous datasets have been proposed in the past few years. Yet labeling remains expensive, thus, it is desirable to jointly train models across aggregations of datasets to enhance data volume and diversity. However, label spaces differ across datasets and may even be in conflict with one another. This paper proposes UniSeg, an effective approach to automatically train models across multiple datasets with differing label spaces, without any manual relabeling efforts. Specifically, we propose two losses that account for conflicting and co-occurring labels to achieve better generalization performance in unseen domains. First, a gradient conflict in training due to mismatched label spaces is identified and a class-independent binary cross-entropy loss is proposed to alleviate such label conflicts. Second, a loss function that considers class-relationships across datasets is proposed for a better multi-dataset training scheme. Extensive quantitative and qualitative analyses on road-scene datasets show that UniSeg improves over multi-dataset baselines, especially on unseen datasets, e.g., achieving more than 8% gain in IoU on KITTI averaged over all the settings.
Communication-Efficient Federated Learning with Acceleration of Global Momentum
Jan 10, 2022
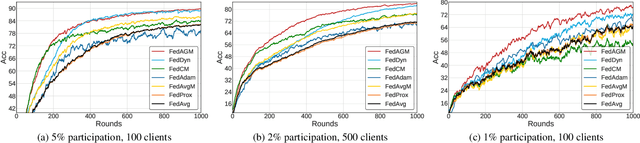
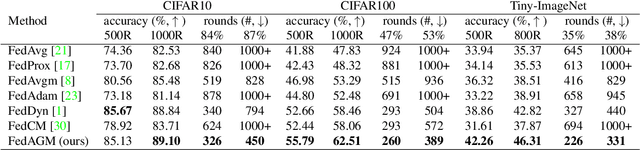
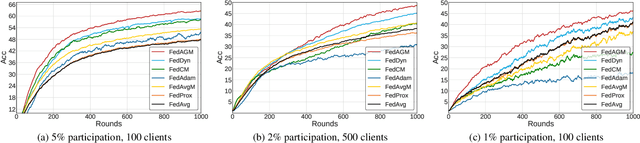
Federated learning often suffers from unstable and slow convergence due to heterogeneous characteristics of participating clients. Such tendency is aggravated when the client participation ratio is low since the information collected from the clients at each round is prone to be more inconsistent. To tackle the challenge, we propose a novel federated learning framework, which improves the stability of the server-side aggregation step, which is achieved by sending the clients an accelerated model estimated with the global gradient to guide the local gradient updates. Our algorithm naturally aggregates and conveys the global update information to participants with no additional communication cost and does not require to store the past models in the clients. We also regularize local update to further reduce the bias and improve the stability of local updates. We perform comprehensive empirical studies on real data under various settings and demonstrate the remarkable performance of the proposed method in terms of accuracy and communication-efficiency compared to the state-of-the-art methods, especially with low client participation rates. Our code is available at https://github.com/ ninigapa0/FedAGM
Information-Theoretic Bias Reduction via Causal View of Spurious Correlation
Jan 10, 2022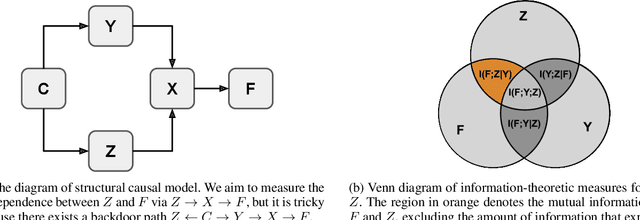
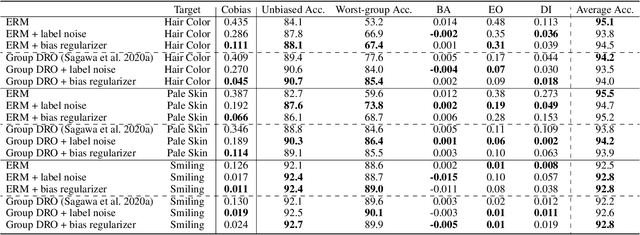
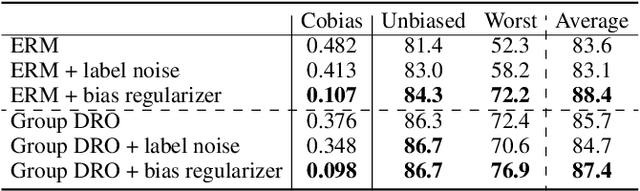

We propose an information-theoretic bias measurement technique through a causal interpretation of spurious correlation, which is effective to identify the feature-level algorithmic bias by taking advantage of conditional mutual information. Although several bias measurement methods have been proposed and widely investigated to achieve algorithmic fairness in various tasks such as face recognition, their accuracy- or logit-based metrics are susceptible to leading to trivial prediction score adjustment rather than fundamental bias reduction. Hence, we design a novel debiasing framework against the algorithmic bias, which incorporates a bias regularization loss derived by the proposed information-theoretic bias measurement approach. In addition, we present a simple yet effective unsupervised debiasing technique based on stochastic label noise, which does not require the explicit supervision of bias information. The proposed bias measurement and debiasing approaches are validated in diverse realistic scenarios through extensive experiments on multiple standard benchmarks.
InfoNeRF: Ray Entropy Minimization for Few-Shot Neural Volume Rendering
Dec 31, 2021



We present an information-theoretic regularization technique for few-shot novel view synthesis based on neural implicit representation. The proposed approach minimizes potential reconstruction inconsistency that happens due to insufficient viewpoints by imposing the entropy constraint of the density in each ray. In addition, to alleviate the potential degenerate issue when all training images are acquired from almost redundant viewpoints, we further incorporate the spatially smoothness constraint into the estimated images by restricting information gains from a pair of rays with slightly different viewpoints. The main idea of our algorithm is to make reconstructed scenes compact along individual rays and consistent across rays in the neighborhood. The proposed regularizers can be plugged into most of existing neural volume rendering techniques based on NeRF in a straightforward way. Despite its simplicity, we achieve consistently improved performance compared to existing neural view synthesis methods by large margins on multiple standard benchmarks. Our project website is available at \url{http://cvlab.snu.ac.kr/research/InfoNeRF}.
Learning Debiased and Disentangled Representations for Semantic Segmentation
Oct 31, 2021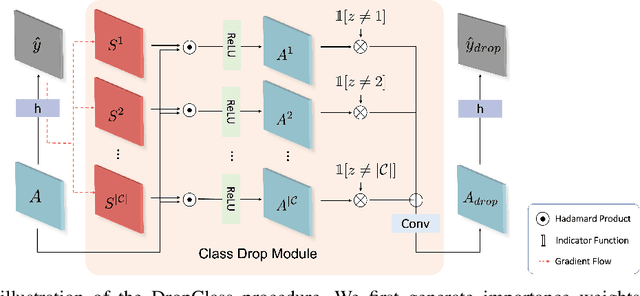
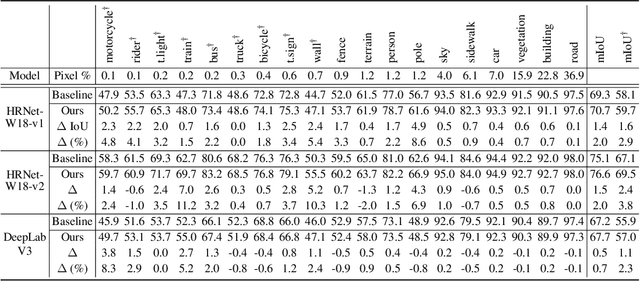
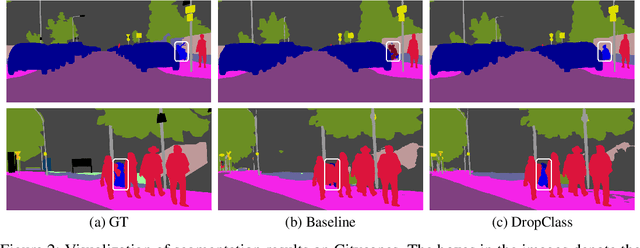

Deep neural networks are susceptible to learn biased models with entangled feature representations, which may lead to subpar performances on various downstream tasks. This is particularly true for under-represented classes, where a lack of diversity in the data exacerbates the tendency. This limitation has been addressed mostly in classification tasks, but there is little study on additional challenges that may appear in more complex dense prediction problems including semantic segmentation. To this end, we propose a model-agnostic and stochastic training scheme for semantic segmentation, which facilitates the learning of debiased and disentangled representations. For each class, we first extract class-specific information from the highly entangled feature map. Then, information related to a randomly sampled class is suppressed by a feature selection process in the feature space. By randomly eliminating certain class information in each training iteration, we effectively reduce feature dependencies among classes, and the model is able to learn more debiased and disentangled feature representations. Models trained with our approach demonstrate strong results on multiple semantic segmentation benchmarks, with especially notable performance gains on under-represented classes.
Variable-Rate Deep Image Compression through Spatially-Adaptive Feature Transform
Aug 21, 2021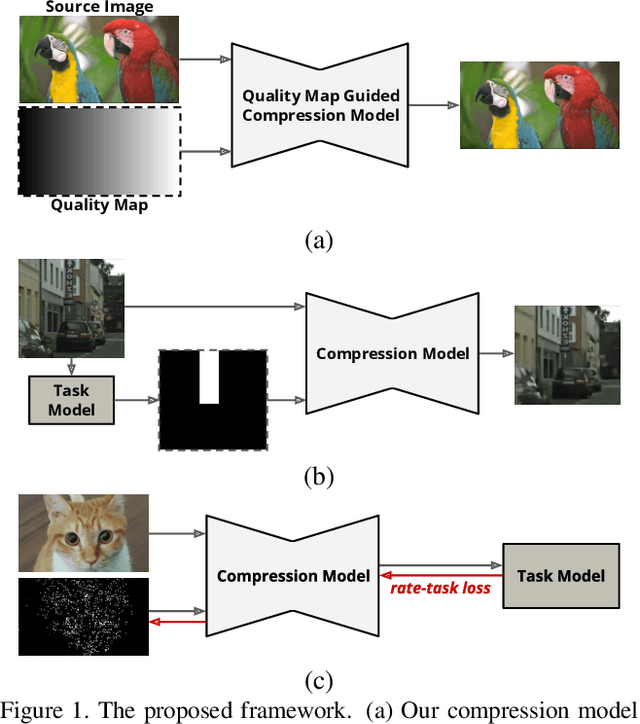


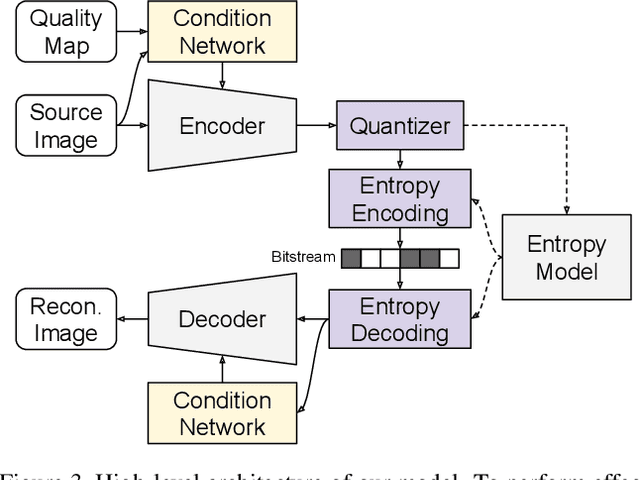
We propose a versatile deep image compression network based on Spatial Feature Transform (SFT arXiv:1804.02815), which takes a source image and a corresponding quality map as inputs and produce a compressed image with variable rates. Our model covers a wide range of compression rates using a single model, which is controlled by arbitrary pixel-wise quality maps. In addition, the proposed framework allows us to perform task-aware image compressions for various tasks, e.g., classification, by efficiently estimating optimized quality maps specific to target tasks for our encoding network. This is even possible with a pretrained network without learning separate models for individual tasks. Our algorithm achieves outstanding rate-distortion trade-off compared to the approaches based on multiple models that are optimized separately for several different target rates. At the same level of compression, the proposed approach successfully improves performance on image classification and text region quality preservation via task-aware quality map estimation without additional model training. The code is available at the project website: https://github.com/micmic123/QmapCompression
Unsupervised Learning of Debiased Representations with Pseudo-Attributes
Aug 06, 2021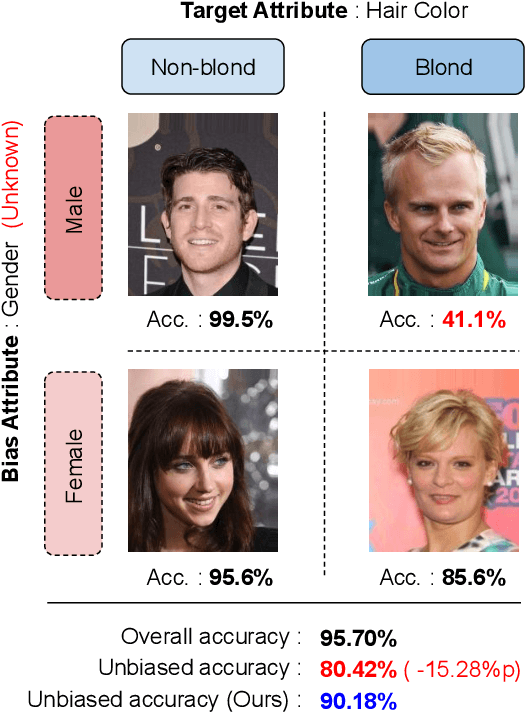
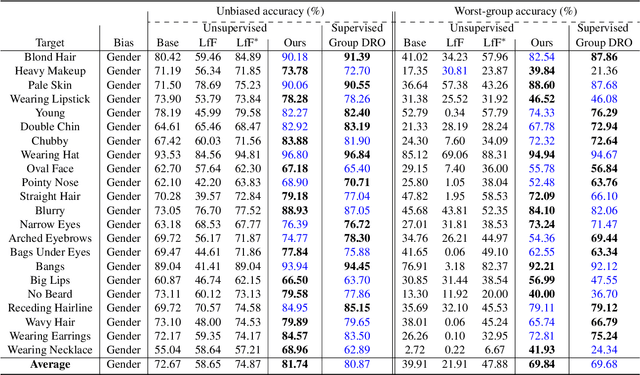

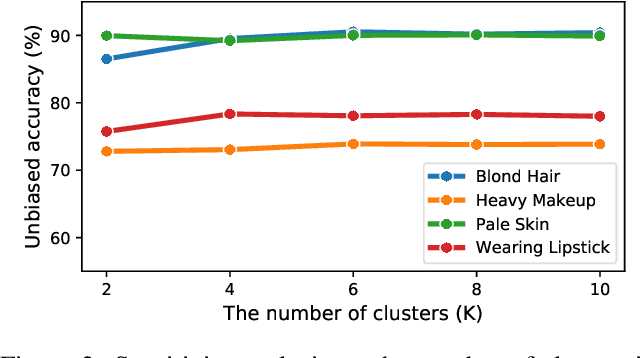
Dataset bias is a critical challenge in machine learning, and its negative impact is aggravated when models capture unintended decision rules with spurious correlations. Although existing works often handle this issue using human supervision, the availability of the proper annotations is impractical and even unrealistic. To better tackle this challenge, we propose a simple but effective debiasing technique in an unsupervised manner. Specifically, we perform clustering on the feature embedding space and identify pseudoattributes by taking advantage of the clustering results even without an explicit attribute supervision. Then, we employ a novel cluster-based reweighting scheme for learning debiased representation; this prevents minority groups from being discounted for minimizing the overall loss, which is desirable for worst-case generalization. The extensive experiments demonstrate the outstanding performance of our approach on multiple standard benchmarks, which is even as competitive as the supervised counterpart.
MCL-GAN: Generative Adversarial Networks with Multiple Specialized Discriminators
Jul 15, 2021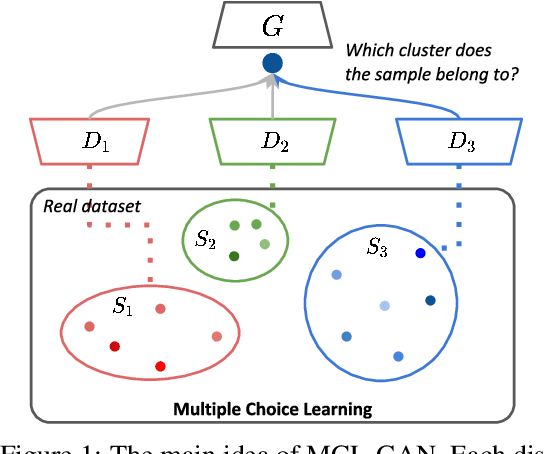
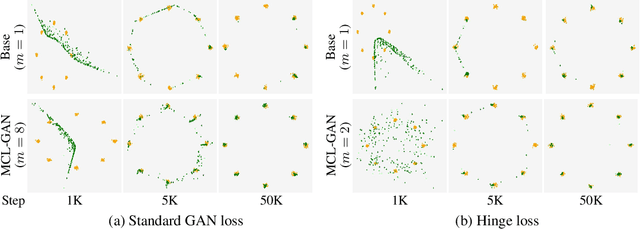
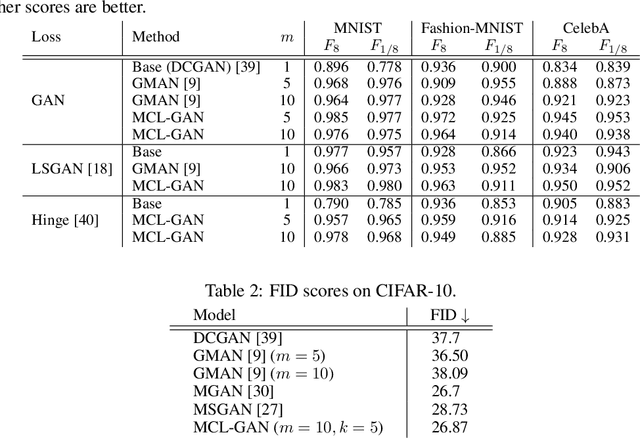
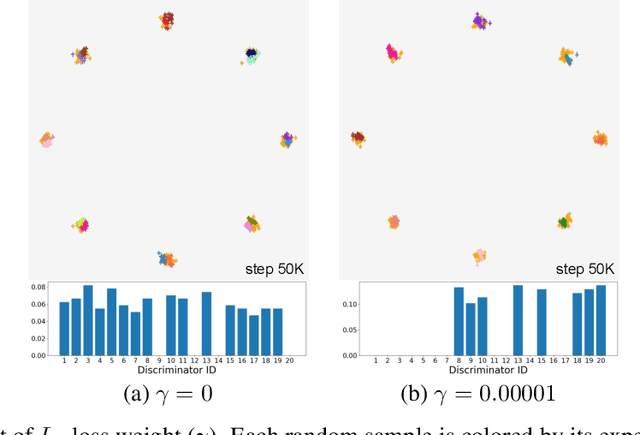
We propose a generative adversarial network with multiple discriminators, where each discriminator is specialized to distinguish the subset of a real dataset. This approach facilitates learning a generator coinciding with the underlying data distribution and thus mitigates the chronic mode collapse problem. From the inspiration of multiple choice learning, we guide each discriminator to have expertise in the subset of the entire data and allow the generator to find reasonable correspondences between the latent and real data spaces automatically without supervision for training examples and the number of discriminators. Despite the use of multiple discriminators, the backbone networks are shared across the discriminators and the increase of training cost is minimized. We demonstrate the effectiveness of our algorithm in the standard datasets using multiple evaluation metrics.
Open-Set Representation Learning through Combinatorial Embedding
Jun 29, 2021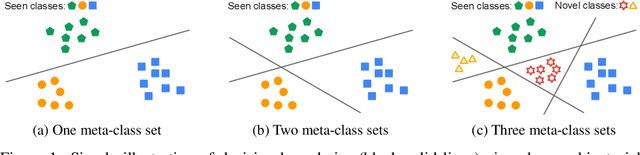
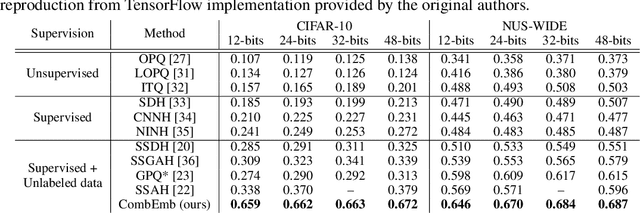

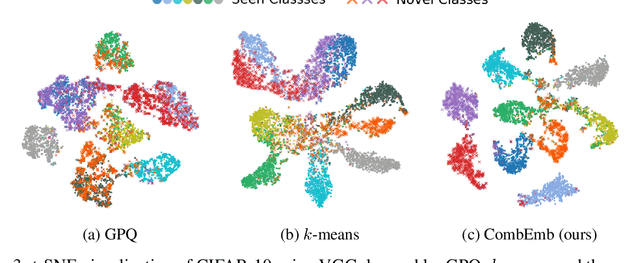
Visual recognition tasks are often limited to dealing with a small subset of classes simply because the labels for the remaining classes are unavailable. We are interested in identifying novel concepts in a dataset through representation learning based on the examples in both labeled and unlabeled classes, and extending the horizon of recognition to both known and novel classes. To address this challenging task, we propose a combinatorial learning approach, which naturally clusters the examples in unseen classes using the compositional knowledge given by multiple supervised meta-classifiers on heterogeneous label spaces. We also introduce a metric learning strategy to estimate pairwise pseudo-labels for improving representations of unlabeled examples, which preserves semantic relations across known and novel classes effectively. The proposed algorithm discovers novel concepts via a joint optimization of enhancing the discrimitiveness of unseen classes as well as learning the representations of known classes generalizable to novel ones. Our extensive experiments demonstrate remarkable performance gains by the proposed approach in multiple image retrieval and novel class discovery benchmarks.
Exemplar-Based Open-Set Panoptic Segmentation Network
May 19, 2021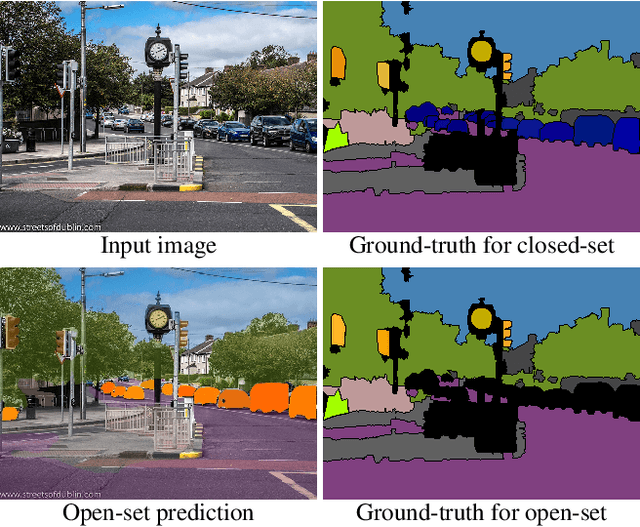
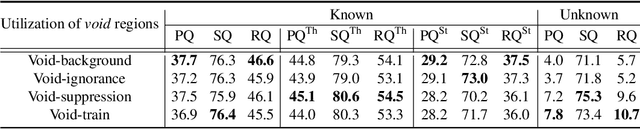
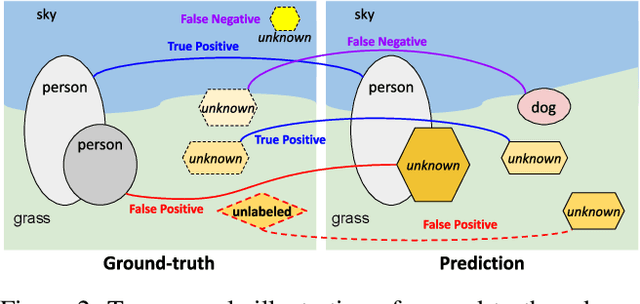
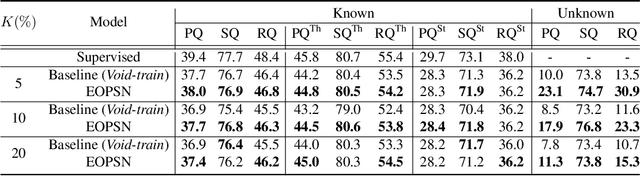
We extend panoptic segmentation to the open-world and introduce an open-set panoptic segmentation (OPS) task. This task requires performing panoptic segmentation for not only known classes but also unknown ones that have not been acknowledged during training. We investigate the practical challenges of the task and construct a benchmark on top of an existing dataset, COCO. In addition, we propose a novel exemplar-based open-set panoptic segmentation network (EOPSN) inspired by exemplar theory. Our approach identifies a new class based on exemplars, which are identified by clustering and employed as pseudo-ground-truths. The size of each class increases by mining new exemplars based on the similarities to the existing ones associated with the class. We evaluate EOPSN on the proposed benchmark and demonstrate the effectiveness of our proposals. The primary goal of our work is to draw the attention of the community to the recognition in the open-world scenarios. The implementation of our algorithm is available on the project webpage: https://cv.snu.ac.kr/research/EOPSN.