 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTicketTalk: Toward human-level performance with end-to-end, transaction-based dialog systems
Dec 27, 2020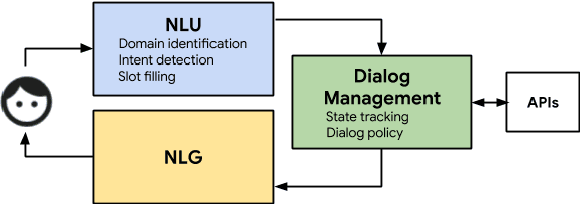
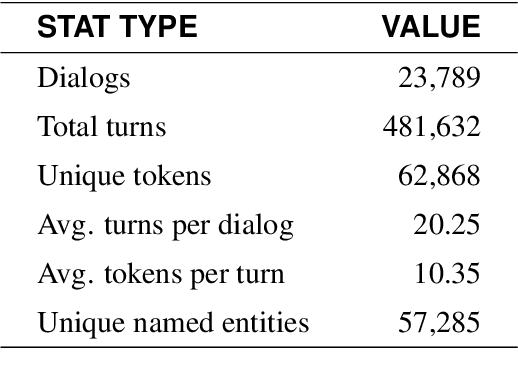

We present a data-driven, end-to-end approach to transaction-based dialog systems that performs at near-human levels in terms of verbal response quality and factual grounding accuracy. We show that two essential components of the system produce these results: a sufficiently large and diverse, in-domain labeled dataset, and a neural network-based, pre-trained model that generates both verbal responses and API call predictions. In terms of data, we introduce TicketTalk, a movie ticketing dialog dataset with 23,789 annotated conversations. The movie ticketing conversations range from completely open-ended and unrestricted to more structured, both in terms of their knowledge base, discourse features, and number of turns. In qualitative human evaluations, model-generated responses trained on just 10,000 TicketTalk dialogs were rated to "make sense" 86.5 percent of the time, almost the same as human responses in the same contexts. Our simple, API-focused annotation schema results in a much easier labeling task making it faster and more cost effective. It is also the key component for being able to predict API calls accurately. We handle factual grounding by incorporating API calls in the training data, allowing our model to learn which actions to take and when. Trained on the same 10,000-dialog set, the model's API call predictions were rated to be correct 93.9 percent of the time in our evaluations, surpassing the ratings for the corresponding human labels. We show how API prediction and response generation scores improve as the dataset size incrementally increases from 5000 to 21,000 dialogs. Our analysis also clearly illustrates the benefits of pre-training. We are publicly releasing the TicketTalk dataset with this paper to facilitate future work on transaction-based dialogs.
The Teacher-Student Chatroom Corpus
Nov 13, 2020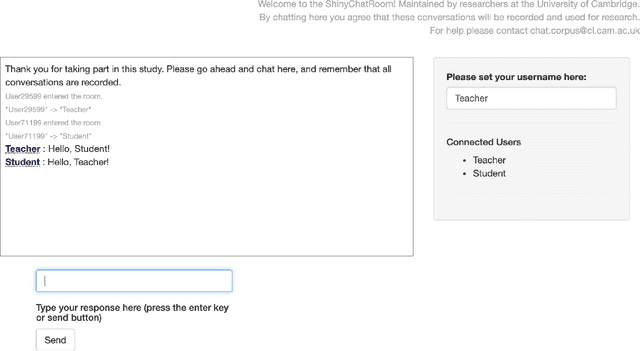
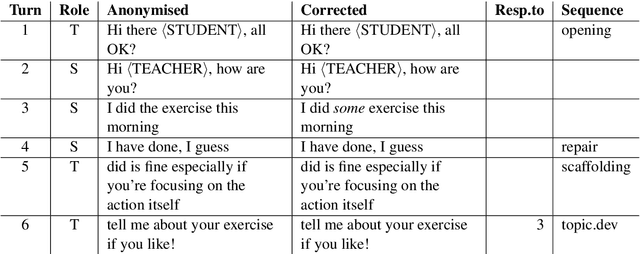
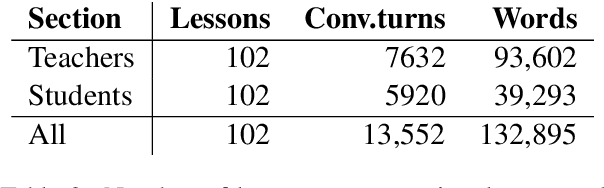
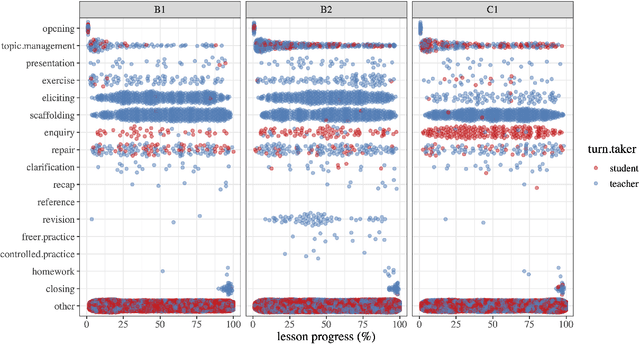
The Teacher-Student Chatroom Corpus (TSCC) is a collection of written conversations captured during one-to-one lessons between teachers and learners of English. The lessons took place in an online chatroom and therefore involve more interactive, immediate and informal language than might be found in asynchronous exchanges such as email correspondence. The fact that the lessons were one-to-one means that the teacher was able to focus exclusively on the linguistic abilities and errors of the student, and to offer personalised exercises, scaffolding and correction. The TSCC contains more than one hundred lessons between two teachers and eight students, amounting to 13.5K conversational turns and 133K words: it is freely available for research use. We describe the corpus design, data collection procedure and annotations added to the text. We perform some preliminary descriptive analyses of the data and consider possible uses of the TSCC.
Inference-only sub-character decomposition improves translation of unseen logographic characters
Nov 12, 2020
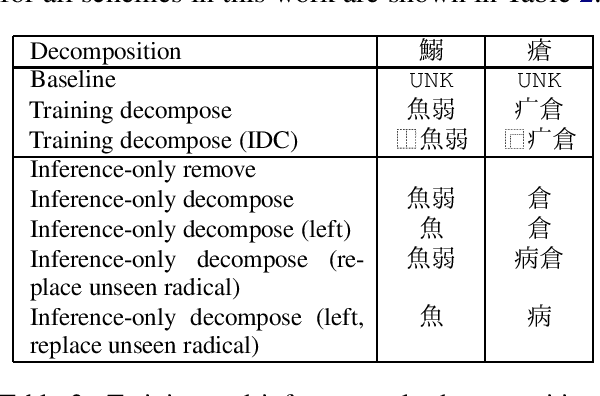
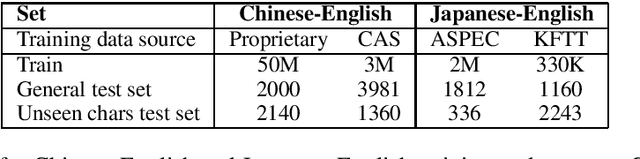

Neural Machine Translation (NMT) on logographic source languages struggles when translating `unseen' characters, which never appear in the training data. One possible approach to this problem uses sub-character decomposition for training and test sentences. However, this approach involves complete retraining, and its effectiveness for unseen character translation to non-logographic languages has not been fully explored. We investigate existing ideograph-based sub-character decomposition approaches for Chinese-to-English and Japanese-to-English NMT, for both high-resource and low-resource domains. For each language pair and domain we construct a test set where all source sentences contain at least one unseen logographic character. We find that complete sub-character decomposition often harms unseen character translation, and gives inconsistent results generally. We offer a simple alternative based on decomposition before inference for unseen characters only. Our approach allows flexible application, achieving translation adequacy improvements and requiring no additional models or training.
Addressing Exposure Bias With Document Minimum Risk Training: Cambridge at the WMT20 Biomedical Translation Task
Oct 11, 2020
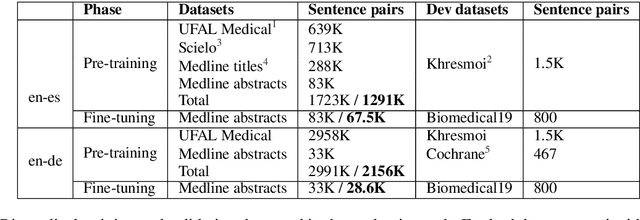
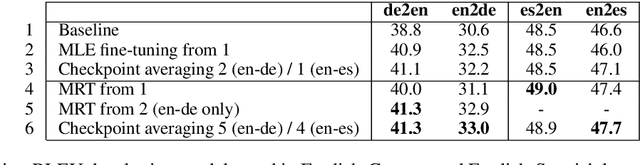
The 2020 WMT Biomedical translation task evaluated Medline abstract translations. This is a small-domain translation task, meaning limited relevant training data with very distinct style and vocabulary. Models trained on such data are susceptible to exposure bias effects, particularly when training sentence pairs are imperfect translations of each other. This can result in poor behaviour during inference if the model learns to neglect the source sentence. The UNICAM entry addresses this problem during fine-tuning using a robust variant on Minimum Risk Training. We contrast this approach with data-filtering to remove `problem' training examples. Under MRT fine-tuning we obtain good results for both directions of English-German and English-Spanish biomedical translation. In particular we achieve the best English-to-Spanish translation result and second-best Spanish-to-English result, despite using only single models with no ensembling.
Neural Machine Translation Doesn't Translate Gender Coreference Right Unless You Make It
Oct 11, 2020
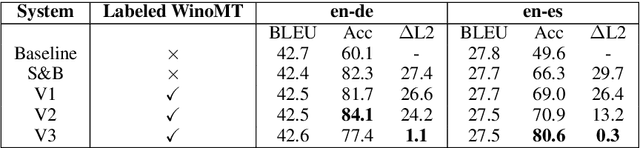
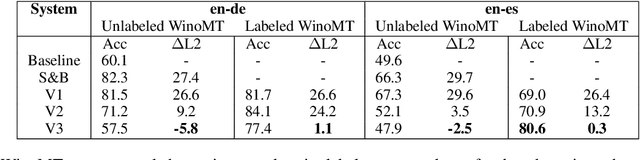
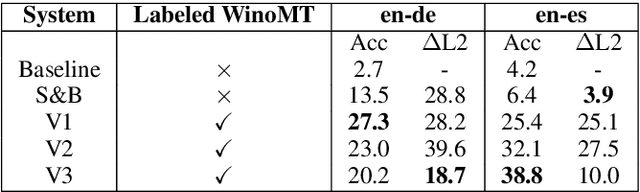
Neural Machine Translation (NMT) has been shown to struggle with grammatical gender that is dependent on the gender of human referents, which can cause gender bias effects. Many existing approaches to this problem seek to control gender inflection in the target language by explicitly or implicitly adding a gender feature to the source sentence, usually at the sentence level. In this paper we propose schemes for incorporating explicit word-level gender inflection tags into NMT. We explore the potential of this gender-inflection controlled translation when the gender feature can be determined from a human reference, assessing on English-to-Spanish and English-to-German translation. We find that simple existing approaches can over-generalize a gender-feature to multiple entities in a sentence, and suggest an effective alternative in the form of tagged coreference adaptation data. We also propose an extension to assess translations of gender-neutral entities from English given a corresponding linguistic convention in the inflected target language.
Using Context in Neural Machine Translation Training Objectives
May 04, 2020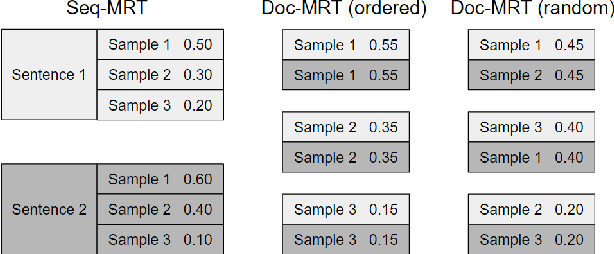

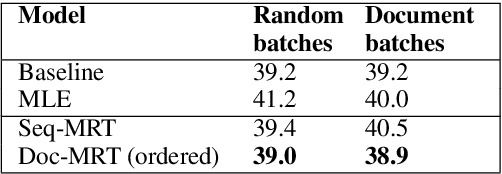
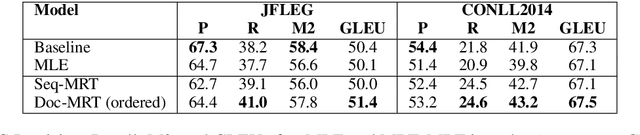
We present Neural Machine Translation (NMT) training using document-level metrics with batch-level documents. Previous sequence-objective approaches to NMT training focus exclusively on sentence-level metrics like sentence BLEU which do not correspond to the desired evaluation metric, typically document BLEU. Meanwhile research into document-level NMT training focuses on data or model architecture rather than training procedure. We find that each of these lines of research has a clear space in it for the other, and propose merging them with a scheme that allows a document-level evaluation metric to be used in the NMT training objective. We first sample pseudo-documents from sentence samples. We then approximate the expected document BLEU gradient with Monte Carlo sampling for use as a cost function in Minimum Risk Training (MRT). This two-level sampling procedure gives NMT performance gains over sequence MRT and maximum-likelihood training. We demonstrate that training is more robust for document-level metrics than with sequence metrics. We further demonstrate improvements on NMT with TER and Grammatical Error Correction (GEC) using GLEU, both metrics used at the document level for evaluations.
Reducing Gender Bias in Neural Machine Translation as a Domain Adaptation Problem
Apr 21, 2020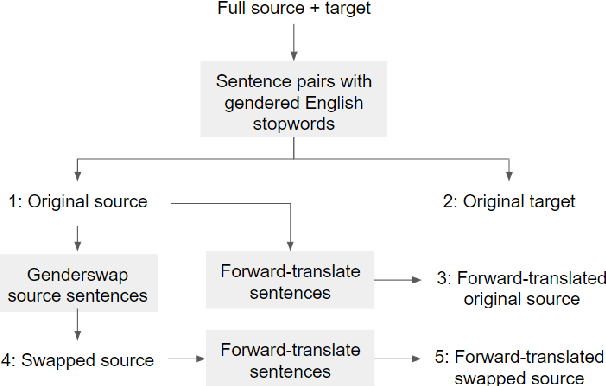

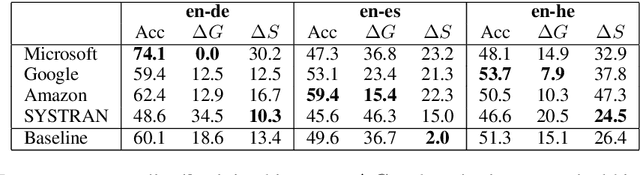

Training data for NLP tasks often exhibits gender bias in that fewer sentences refer to women than to men. In Neural Machine Translation (NMT) gender bias has been shown to reduce translation quality, particularly when the target language has grammatical gender. The recent WinoMT challenge set allows us to measure this effect directly (Stanovsky et al, 2019). Ideally we would reduce system bias by simply debiasing all data prior to training, but achieving this effectively is itself a challenge. Rather than attempt to create a `balanced' dataset, we use transfer learning on a small set of trusted, gender-balanced examples. This approach gives strong and consistent improvements in gender debiasing with much less computational cost than training from scratch. A known pitfall of transfer learning on new domains is `catastrophic forgetting', which we address both in adaptation and in inference. During adaptation we show that Elastic Weight Consolidation allows a performance trade-off between general translation quality and bias reduction. During inference we propose a lattice-rescoring scheme which outperforms all systems evaluated in Stanovsky et al (2019) on WinoMT with no degradation of general test set BLEU, and we show this scheme can be applied to remove gender bias in the output of `black box` online commercial MT systems. We demonstrate our approach translating from English into three languages with varied linguistic properties and data availability.
Semi-supervised Bootstrapping of Dialogue State Trackers for Task Oriented Modelling
Nov 26, 2019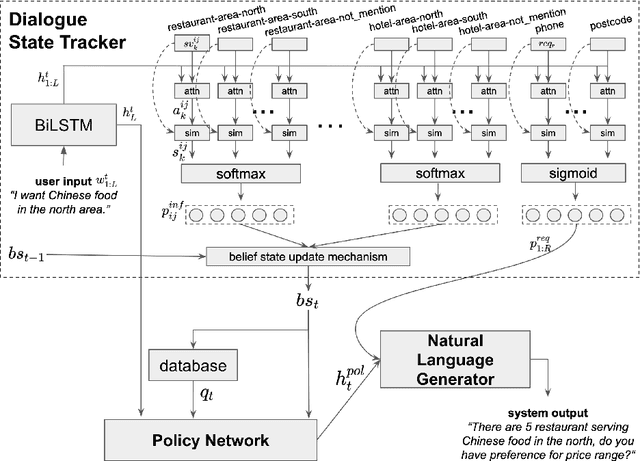

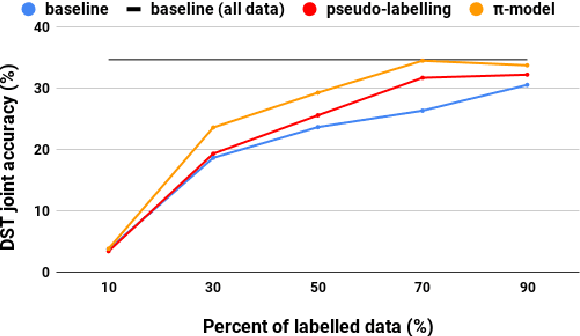
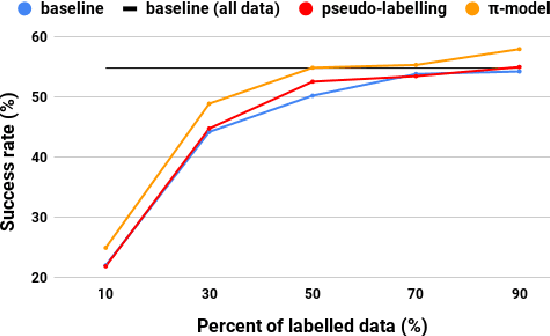
Dialogue systems benefit greatly from optimizing on detailed annotations, such as transcribed utterances, internal dialogue state representations and dialogue act labels. However, collecting these annotations is expensive and time-consuming, holding back development in the area of dialogue modelling. In this paper, we investigate semi-supervised learning methods that are able to reduce the amount of required intermediate labelling. We find that by leveraging un-annotated data instead, the amount of turn-level annotations of dialogue state can be significantly reduced when building a neural dialogue system. Our analysis on the MultiWOZ corpus, covering a range of domains and topics, finds that annotations can be reduced by up to 30\% while maintaining equivalent system performance. We also describe and evaluate the first end-to-end dialogue model created for the MultiWOZ corpus.
Taskmaster-1: Toward a Realistic and Diverse Dialog Dataset
Sep 01, 2019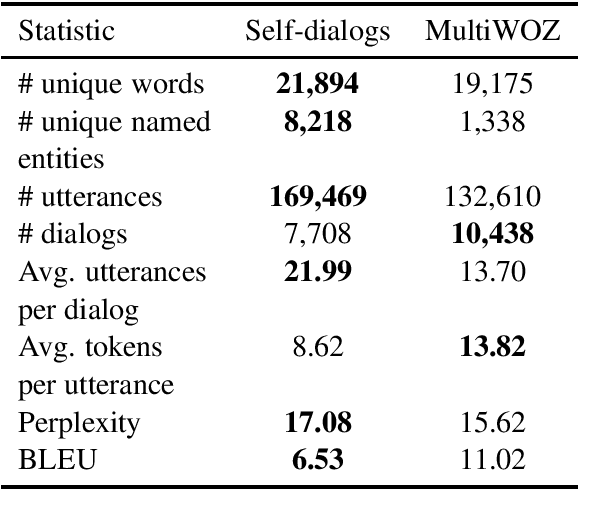

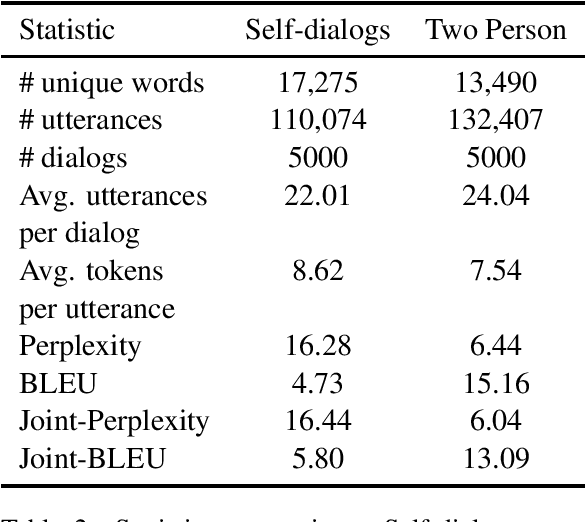
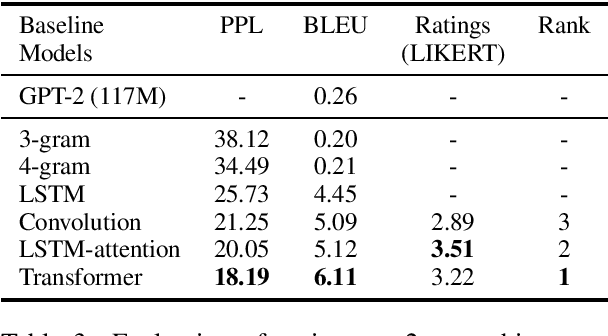
A significant barrier to progress in data-driven approaches to building dialog systems is the lack of high quality, goal-oriented conversational data. To help satisfy this elementary requirement, we introduce the initial release of the Taskmaster-1 dataset which includes 13,215 task-based dialogs comprising six domains. Two procedures were used to create this collection, each with unique advantages. The first involves a two-person, spoken "Wizard of Oz" (WOz) approach in which trained agents and crowdsourced workers interact to complete the task while the second is "self-dialog" in which crowdsourced workers write the entire dialog themselves. We do not restrict the workers to detailed scripts or to a small knowledge base and hence we observe that our dataset contains more realistic and diverse conversations in comparison to existing datasets. We offer several baseline models including state of the art neural seq2seq architectures with benchmark performance as well as qualitative human evaluations. Dialogs are labeled with API calls and arguments, a simple and cost effective approach which avoids the requirement of complex annotation schema. The layer of abstraction between the dialog model and the service provider API allows for a given model to interact with multiple services that provide similar functionally. Finally, the dataset will evoke interest in written vs. spoken language, discourse patterns, error handling and other linguistic phenomena related to dialog system research, development and design.
On NMT Search Errors and Model Errors: Cat Got Your Tongue?
Aug 27, 2019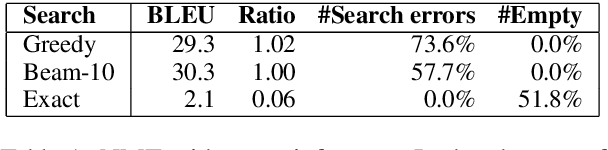
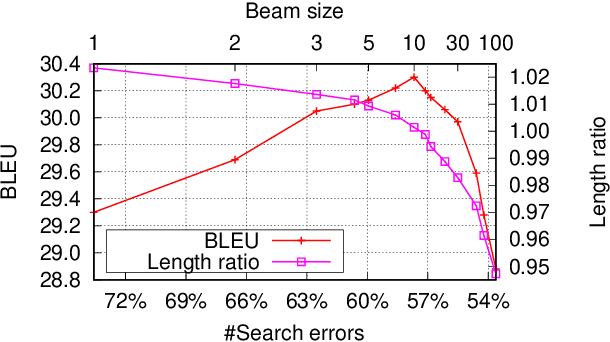
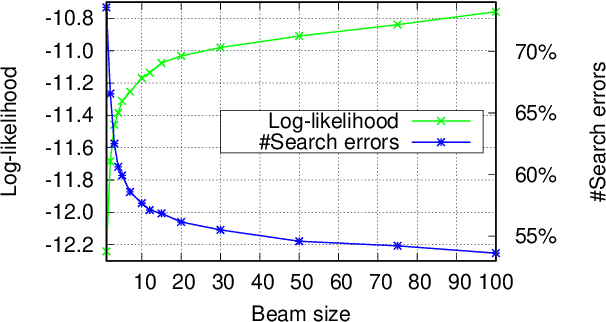
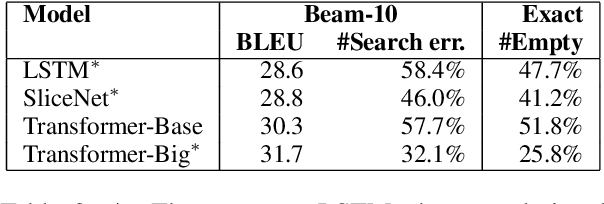
We report on search errors and model errors in neural machine translation (NMT). We present an exact inference procedure for neural sequence models based on a combination of beam search and depth-first search. We use our exact search to find the global best model scores under a Transformer base model for the entire WMT15 English-German test set. Surprisingly, beam search fails to find these global best model scores in most cases, even with a very large beam size of 100. For more than 50% of the sentences, the model in fact assigns its global best score to the empty translation, revealing a massive failure of neural models in properly accounting for adequacy. We show by constraining search with a minimum translation length that at the root of the problem of empty translations lies an inherent bias towards shorter translations. We conclude that vanilla NMT in its current form requires just the right amount of beam search errors, which, from a modelling perspective, is a highly unsatisfactory conclusion indeed, as the model often prefers an empty translation.