 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinyNina: A Resource-Efficient Edge-AI Framework for Sustainable Air Quality Monitoring via Intra-Image Satellite Super-Resolution
Apr 06, 2026Nitrogen dioxide (NO$_2$) is a primary atmospheric pollutant and a significant contributor to respiratory morbidity and urban climate-related challenges. While satellite platforms like Sentinel-2 provide global coverage, their native spatial resolution often limits the precision required, fine-grained NO$_2$ assessment. To address this, we propose TinyNina, a resource-efficient Edge-AI framework specifically engineered for sustainable environmental monitoring. TinyNina implements a novel intra-image learning paradigm that leverages the multi-spectral hierarchy of Sentinel-2 as internal training labels, effectively eliminating the dependency on costly and often unavailable external high-resolution reference datasets. The framework incorporates wavelength-specific attention gates and depthwise separable convolutions to preserve pollutant-sensitive spectral features while maintaining an ultra-lightweight footprint of only 51K parameters. Experimental results, validated against 3,276 matched satellite-ground station pairs, demonstrate that TinyNina achieves a state-of-the-art Mean Absolute Error (MAE) of 7.4 $μ$g/m$^3$. This performance represents a 95% reduction in computational overhead and 47$\times$ faster inference compared to high-capacity models such as EDSR and RCAN. By prioritizing task-specific utility and architectural efficiency, TinyNina provides a scalable, low-latency solution for real-time air quality monitoring in smart city infrastructures.
NeuroDDAF: Neural Dynamic Diffusion-Advection Fields with Evidential Fusion for Air Quality Forecasting
Apr 01, 2026Accurate air quality forecasting is crucial for protecting public health and guiding environmental policy, yet it remains challenging due to nonlinear spatiotemporal dynamics, wind-driven transport, and distribution shifts across regions. Physics-based models are interpretable but computationally expensive and often rely on restrictive assumptions, whereas purely data-driven models can be accurate but may lack robustness and calibrated uncertainty. To address these limitations, we propose Neural Dynamic Diffusion-Advection Fields (NeuroDDAF), a physics-informed forecasting framework that unifies neural representation learning with open-system transport modeling. NeuroDDAF integrates (i) a GRU-Graph Attention encoder to capture temporal dynamics and wind-aware spatial interactions, (ii) a Fourier-domain diffusion-advection module with learnable residuals, (iii) a wind-modulated latent Neural ODE to model continuous-time evolution under time-varying connectivity, and (iv) an evidential fusion mechanism that adaptively combines physics-guided and neural forecasts while quantifying uncertainty. Experiments on four urban datasets (Beijing, Shenzhen, Tianjin, and Ancona) across 1-3 day horizons show that NeuroDDAF consistently outperforms strong baselines, including AirPhyNet, achieving up to 9.7% reduction in RMSE and 9.4% reduction in MAE on long-term forecasts. On the Beijing dataset, NeuroDDAF attains an RMSE of 41.63 $μ$g/m$^3$ for 1-day prediction and 48.88 $μ$g/m$^3$ for 3-day prediction, representing the best performance among all compared methods. In addition, NeuroDDAF improves cross-city generalization and yields well-calibrated uncertainty estimates, as confirmed by ensemble variance analysis and case studies under varying wind conditions.
One-for-All: A Lightweight Stabilized and Parameter-Efficient Pre-trained LLM for Time Series Forecasting
Mar 31, 2026We address the challenge of adapting pre-trained Large Language Models (LLMs) for multivariate time-series analysis, where their deployment is often hindered by prohibitive computational and memory demands. Our solution, One-for-All, introduces Gaussian Rank-Stabilized Low-Rank Adapters (rsLoRA) to enable parameter-efficient fine-tuning of frozen LLMs. While inspired by LoRA, rsLoRA introduces a mathematically grounded rank-stabilization mechanism that enables provable gradient stability at low ranks a novel contribution absent in prior PEFT methods. Our framework injects trainable rank decomposition matrices (rank 16) into positional embeddings and output layers, while keeping self-attention weights fixed. This design reduces trainable parameters by 6.8$\times$ (vs. TimesNet), 21$\times$ (vs. GPT4TS), and 11.8$\times$ (vs. TIME-LLM), while achieving a 168-1,776$\times$ smaller memory footprint (2.2MiB vs. 340MiB-4.18GiB in SOTA models). Rigorous evaluation across six time-series tasks demonstrates that One-for-All achieves state-of-the-art efficiency-accuracy trade-offs: 5.5$\times$ higher parameter efficiency (MSE=5.50) than TimesNet and 21$\times$ better than GPT4TS, while matching their forecasting accuracy (MSE=0.33). The framework's stability is validated through consistent performance across diverse horizons (96-720 steps) and datasets (ETT, Weather, M3, M4), with 98.3% fewer parameters than conventional transformers. These advances enable deployment on edge devices for healthcare, finance, and environmental monitoring without compromising performance.
PollutionNet: A Vision Transformer Framework for Climatological Assessment of NO$_2$ and SO$_2$ Using Satellite-Ground Data Fusion
Mar 31, 2026Accurate assessment of atmospheric nitrogen dioxide (NO$_2$) and sulfur dioxide (SO$_2$) is essential for understanding climate-air quality interactions, supporting environmental policy, and protecting public health. Traditional monitoring approaches face limitations: satellite observations provide broad spatial coverage but suffer from data gaps, while ground-based sensors offer high temporal resolution but limited spatial extent. To address these challenges, we propose PollutionNet, a Vision Transformer-based framework that integrates Sentinel-5P TROPOMI vertical column density (VCD) data with ground-level observations. By leveraging self-attention mechanisms, PollutionNet captures complex spatiotemporal dependencies that are often missed by conventional CNN and RNN models. Applied to Ireland (2020-2021), our case study demonstrates that PollutionNet achieves state-of-the-art performance (RMSE: 6.89 $μ$g/m$^3$ for NO$_2$, 4.49 $μ$g/m$^3$ for SO$_2$), reducing prediction errors by up to 14% compared to baseline models. Beyond accuracy gains, PollutionNet provides a scalable and data-efficient tool for applied climatology, enabling robust pollution assessments in regions with sparse monitoring networks. These results highlight the potential of advanced machine learning approaches to enhance climate-related air quality research, inform environmental management, and support sustainable policy decisions.
Meteorology-Driven GPT4AP: A Multi-Task Forecasting LLM for Atmospheric Air Pollution in Data-Scarce Settings
Mar 31, 2026Accurate forecasting of air pollution is important for environmental monitoring and policy support, yet data-driven models often suffer from limited generalization in regions with sparse observations. This paper presents Meteorology-Driven GPT for Air Pollution (GPT4AP), a parameter-efficient multi-task forecasting framework based on a pre-trained GPT-2 backbone and Gaussian rank-stabilized low-rank adaptation (rsLoRA). The model freezes the self-attention and feed-forward layers and adapts lightweight positional and output modules, substantially reducing the number of trainable parameters. GPT4AP is evaluated on six real-world air quality monitoring datasets under few-shot, zero-shot, and long-term forecasting settings. In the few-shot regime using 10% of the training data, GPT4AP achieves an average MSE/MAE of 0.686/0.442, outperforming DLinear (0.728/0.530) and ETSformer (0.734/0.505). In zero-shot cross-station transfer, the proposed model attains an average MSE/MAE of 0.529/0.403, demonstrating improved generalization compared with existing baselines. In long-term forecasting with full training data, GPT4AP remains competitive, achieving an average MAE of 0.429, while specialized time-series models show slightly lower errors. These results indicate that GPT4AP provides a data-efficient forecasting approach that performs robustly under limited supervision and domain shift, while maintaining competitive accuracy in data-rich settings.
Self-Supervised Learning for Invariant Representations from Multi-Spectral and SAR Images
May 04, 2022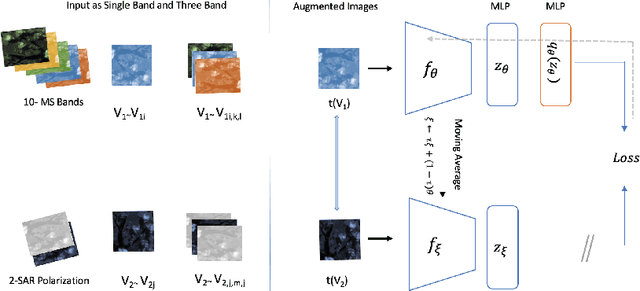
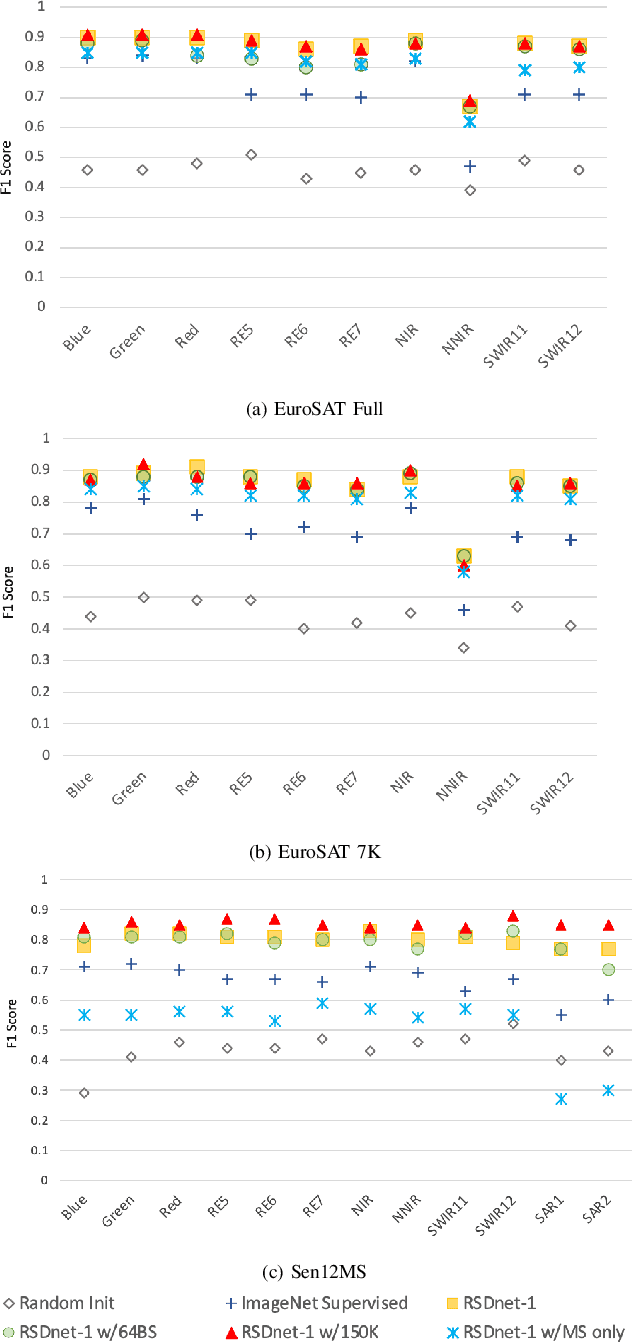
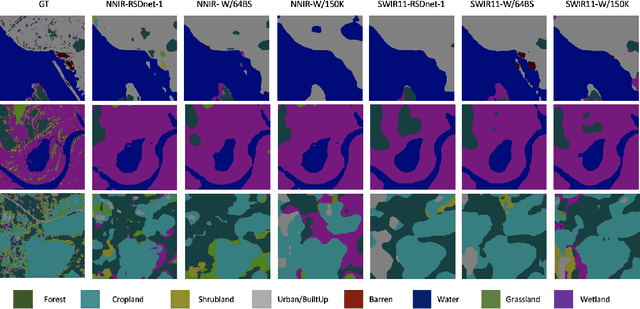
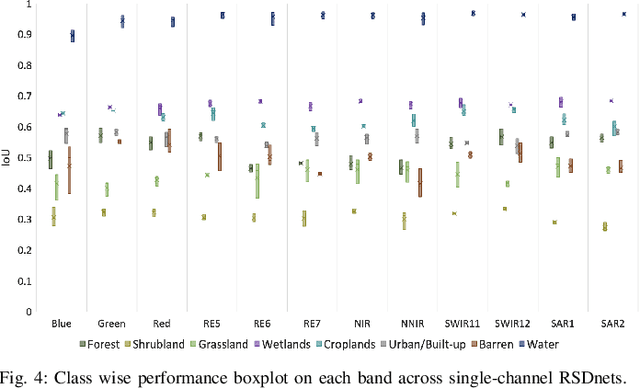
Self-Supervised learning (SSL) has become the new state-of-art in several domain classification and segmentation tasks. Of these, one popular category in SSL is distillation networks such as BYOL. This work proposes RSDnet, which applies the distillation network (BYOL) in the remote sensing (RS) domain where data is non-trivially different from natural RGB images. Since Multi-spectral (MS) and synthetic aperture radar (SAR) sensors provide varied spectral and spatial resolution information, we utilised them as an implicit augmentation to learn invariant feature embeddings. In order to learn RS based invariant features with SSL, we trained RSDnet in two ways, i.e., single channel feature learning and three channel feature learning. This work explores the usefulness of single channel feature learning from random MS and SAR bands compared to the common notion of using three or more bands. In our linear evaluation, these single channel features reached a 0.92 F1 score on the EuroSAT classification task and 59.6 mIoU on the DFC segmentation task for certain single bands. We also compared our results with ImageNet weights and showed that the RS based SSL model outperforms the supervised ImageNet based model. We further explored the usefulness of multi-modal data compared to single modality data, and it is shown that utilising MS and SAR data learn better invariant representations than utilising only MS data.