 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVRFP: On-the-fly Video Retrieval using Web Images and Fast Fisher Vector Products
Apr 10, 2017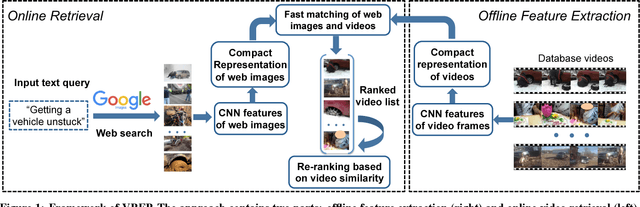
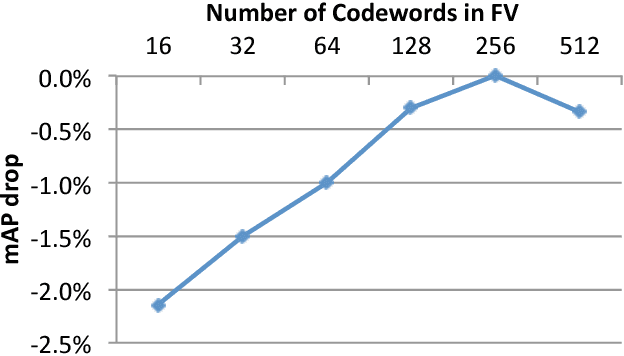
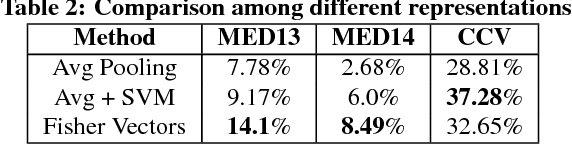
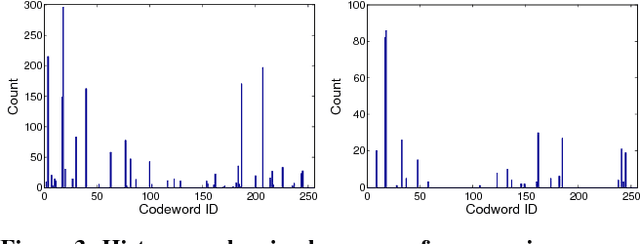
VRFP is a real-time video retrieval framework based on short text input queries, which obtains weakly labeled training images from the web after the query is known. The retrieved web images representing the query and each database video are treated as unordered collections of images, and each collection is represented using a single Fisher Vector built on CNN features. Our experiments show that a Fisher Vector is robust to noise present in web images and compares favorably in terms of accuracy to other standard representations. While a Fisher Vector can be constructed efficiently for a new query, matching against the test set is slow due to its high dimensionality. To perform matching in real-time, we present a lossless algorithm that accelerates the inner product computation between high dimensional Fisher Vectors. We prove that the expected number of multiplications required decreases quadratically with the sparsity of Fisher Vectors. We are not only able to construct and apply query models in real-time, but with the help of a simple re-ranking scheme, we also outperform state-of-the-art automatic retrieval methods by a significant margin on TRECVID MED13 (3.5%), MED14 (1.3%) and CCV datasets (5.2%). We also provide a direct comparison on standard datasets between two different paradigms for automatic video retrieval - zero-shot learning and on-the-fly retrieval.
Son of Zorn's Lemma: Targeted Style Transfer Using Instance-aware Semantic Segmentation
Jan 09, 2017
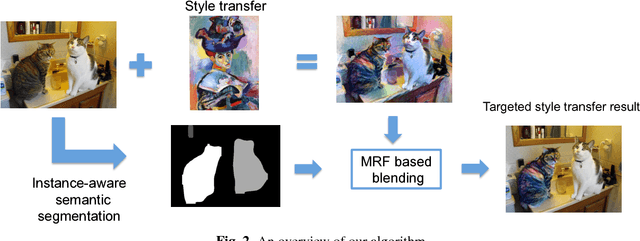

Style transfer is an important task in which the style of a source image is mapped onto that of a target image. The method is useful for synthesizing derivative works of a particular artist or specific painting. This work considers targeted style transfer, in which the style of a template image is used to alter only part of a target image. For example, an artist may wish to alter the style of only one particular object in a target image without altering the object's general morphology or surroundings. This is useful, for example, in augmented reality applications (such as the recently released Pokemon GO), where one wants to alter the appearance of a single real-world object in an image frame to make it appear as a cartoon. Most notably, the rendering of real-world objects into cartoon characters has been used in a number of films and television show, such as the upcoming series Son of Zorn. We present a method for targeted style transfer that simultaneously segments and stylizes single objects selected by the user. The method uses a Markov random field model to smooth and anti-alias outlier pixels near object boundaries, so that stylized objects naturally blend into their surroundings.
Training Neural Networks Without Gradients: A Scalable ADMM Approach
May 06, 2016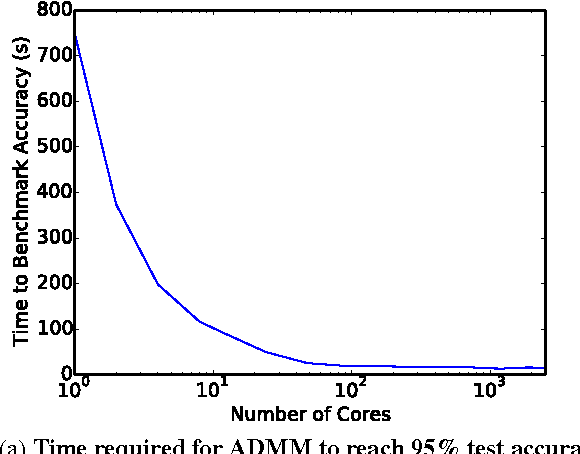
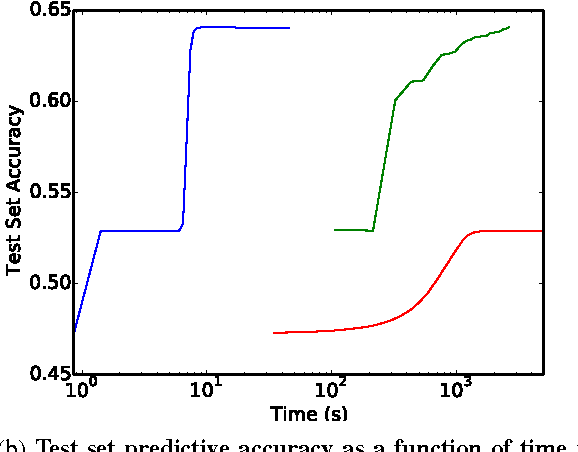
With the growing importance of large network models and enormous training datasets, GPUs have become increasingly necessary to train neural networks. This is largely because conventional optimization algorithms rely on stochastic gradient methods that don't scale well to large numbers of cores in a cluster setting. Furthermore, the convergence of all gradient methods, including batch methods, suffers from common problems like saturation effects, poor conditioning, and saddle points. This paper explores an unconventional training method that uses alternating direction methods and Bregman iteration to train networks without gradient descent steps. The proposed method reduces the network training problem to a sequence of minimization sub-steps that can each be solved globally in closed form. The proposed method is advantageous because it avoids many of the caveats that make gradient methods slow on highly non-convex problems. The method exhibits strong scaling in the distributed setting, yielding linear speedups even when split over thousands of cores.
Layer-Specific Adaptive Learning Rates for Deep Networks
Oct 15, 2015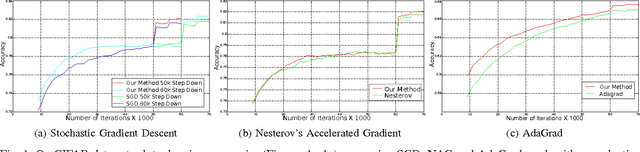
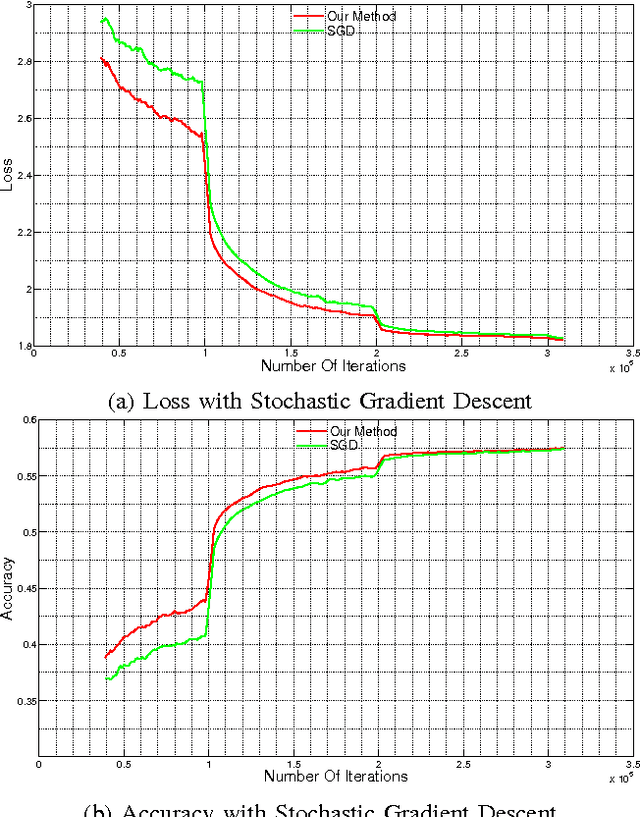


The increasing complexity of deep learning architectures is resulting in training time requiring weeks or even months. This slow training is due in part to vanishing gradients, in which the gradients used by back-propagation are extremely large for weights connecting deep layers (layers near the output layer), and extremely small for shallow layers (near the input layer); this results in slow learning in the shallow layers. Additionally, it has also been shown that in highly non-convex problems, such as deep neural networks, there is a proliferation of high-error low curvature saddle points, which slows down learning dramatically. In this paper, we attempt to overcome the two above problems by proposing an optimization method for training deep neural networks which uses learning rates which are both specific to each layer in the network and adaptive to the curvature of the function, increasing the learning rate at low curvature points. This enables us to speed up learning in the shallow layers of the network and quickly escape high-error low curvature saddle points. We test our method on standard image classification datasets such as MNIST, CIFAR10 and ImageNet, and demonstrate that our method increases accuracy as well as reduces the required training time over standard algorithms.
Selecting Relevant Web Trained Concepts for Automated Event Retrieval
Sep 25, 2015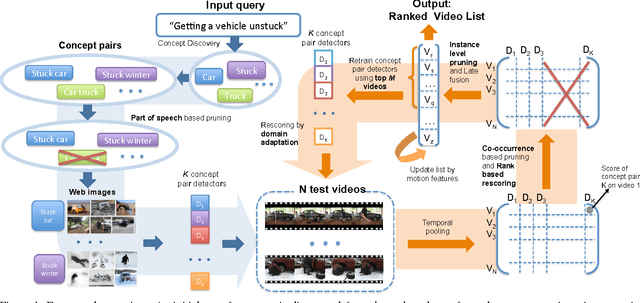
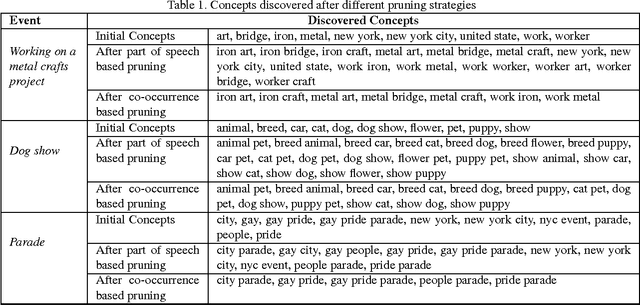


Complex event retrieval is a challenging research problem, especially when no training videos are available. An alternative to collecting training videos is to train a large semantic concept bank a priori. Given a text description of an event, event retrieval is performed by selecting concepts linguistically related to the event description and fusing the concept responses on unseen videos. However, defining an exhaustive concept lexicon and pre-training it requires vast computational resources. Therefore, recent approaches automate concept discovery and training by leveraging large amounts of weakly annotated web data. Compact visually salient concepts are automatically obtained by the use of concept pairs or, more generally, n-grams. However, not all visually salient n-grams are necessarily useful for an event query--some combinations of concepts may be visually compact but irrelevant--and this drastically affects performance. We propose an event retrieval algorithm that constructs pairs of automatically discovered concepts and then prunes those concepts that are unlikely to be helpful for retrieval. Pruning depends both on the query and on the specific video instance being evaluated. Our approach also addresses calibration and domain adaptation issues that arise when applying concept detectors to unseen videos. We demonstrate large improvements over other vision based systems on the TRECVID MED 13 dataset.