 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Model Parallelism for Deep Neural Networks with Compiler and Hardware Support
Jun 11, 2019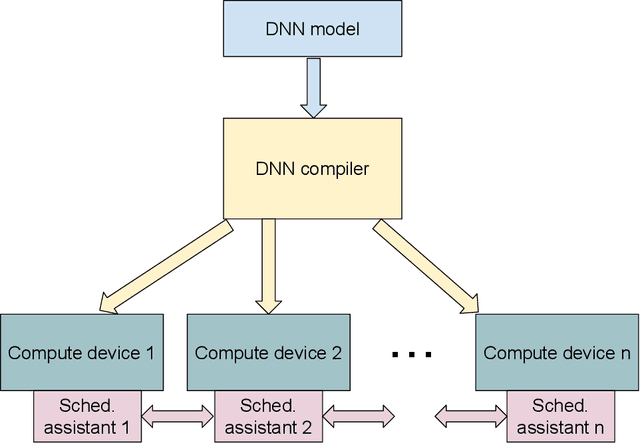
The deep neural networks (DNNs) have been enormously successful in tasks that were hitherto in the human-only realm such as image recognition, and language translation. Owing to their success the DNNs are being explored for use in ever more sophisticated tasks. One of the ways that the DNNs are made to scale for the complex undertakings is by increasing their size -- deeper and wider networks can model well the additional complexity. Such large models are trained using model parallelism on multiple compute devices such as multi-GPUs and multi-node systems. In this paper, we develop a compiler-driven approach to achieve model parallelism. We model the computation and communication costs of a dataflow graph that embodies the neural network training process and then, partition the graph using heuristics in such a manner that the communication between compute devices is minimal and we have a good load balance. The hardware scheduling assistants are proposed to assist the compiler in fine tuning the distribution of work at runtime.
Mixed Precision Training With 8-bit Floating Point
May 29, 2019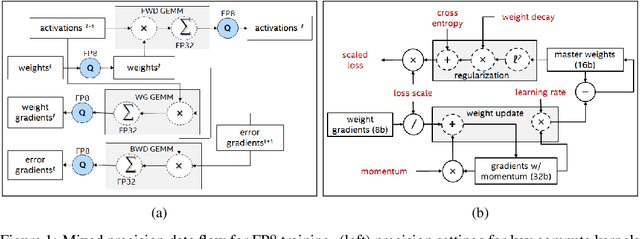

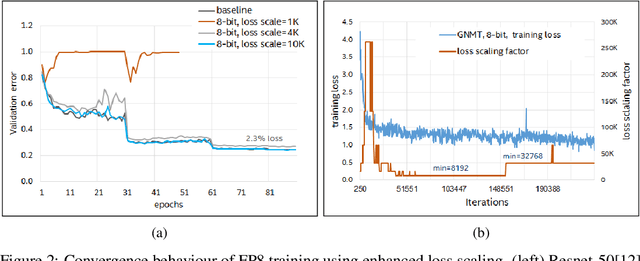

Reduced precision computation for deep neural networks is one of the key areas addressing the widening compute gap driven by an exponential growth in model size. In recent years, deep learning training has largely migrated to 16-bit precision, with significant gains in performance and energy efficiency. However, attempts to train DNNs at 8-bit precision have met with significant challenges because of the higher precision and dynamic range requirements of back-propagation. In this paper, we propose a method to train deep neural networks using 8-bit floating point representation for weights, activations, errors, and gradients. In addition to reducing compute precision, we also reduced the precision requirements for the master copy of weights from 32-bit to 16-bit. We demonstrate state-of-the-art accuracy across multiple data sets (imagenet-1K, WMT16) and a broader set of workloads (Resnet-18/34/50, GNMT, Transformer) than previously reported. We propose an enhanced loss scaling method to augment the reduced subnormal range of 8-bit floating point for improved error propagation. We also examine the impact of quantization noise on generalization and propose a stochastic rounding technique to address gradient noise. As a result of applying all these techniques, we report slightly higher validation accuracy compared to full precision baseline.
Out-of-Distribution Detection Using an Ensemble of Self Supervised Leave-out Classifiers
Sep 04, 2018
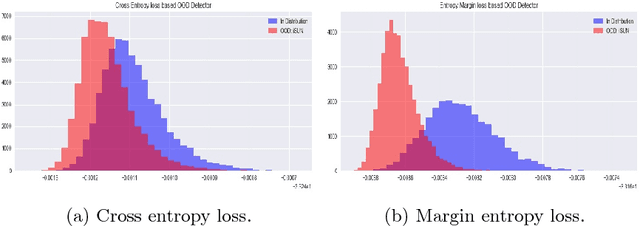
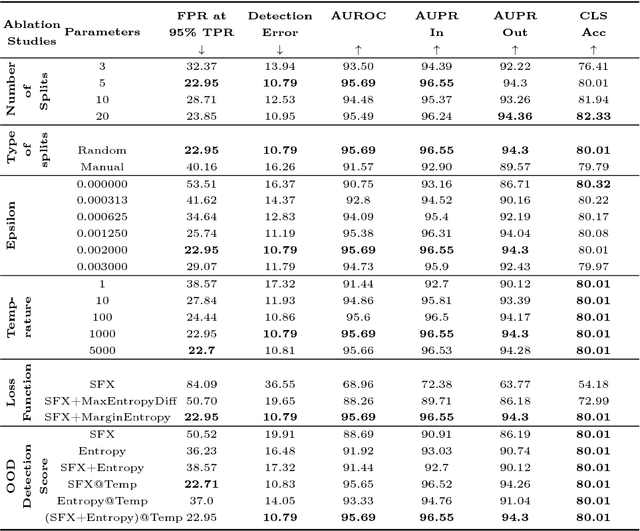
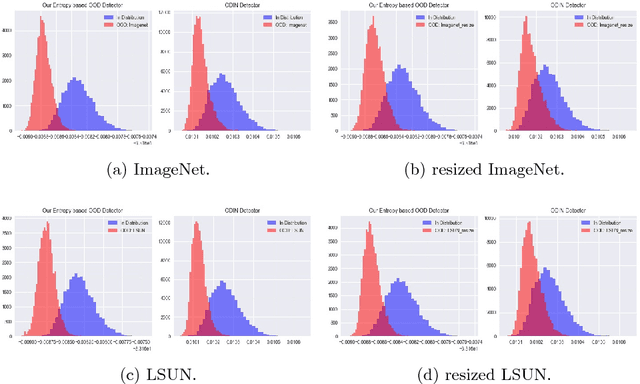
As deep learning methods form a critical part in commercially important applications such as autonomous driving and medical diagnostics, it is important to reliably detect out-of-distribution (OOD) inputs while employing these algorithms. In this work, we propose an OOD detection algorithm which comprises of an ensemble of classifiers. We train each classifier in a self-supervised manner by leaving out a random subset of training data as OOD data and the rest as in-distribution (ID) data. We propose a novel margin-based loss over the softmax output which seeks to maintain at least a margin $m$ between the average entropy of the OOD and in-distribution samples. In conjunction with the standard cross-entropy loss, we minimize the novel loss to train an ensemble of classifiers. We also propose a novel method to combine the outputs of the ensemble of classifiers to obtain OOD detection score and class prediction. Overall, our method convincingly outperforms Hendrycks et al.[7] and the current state-of-the-art ODIN[13] on several OOD detection benchmarks.
Mixed Precision Training of Convolutional Neural Networks using Integer Operations
Feb 23, 2018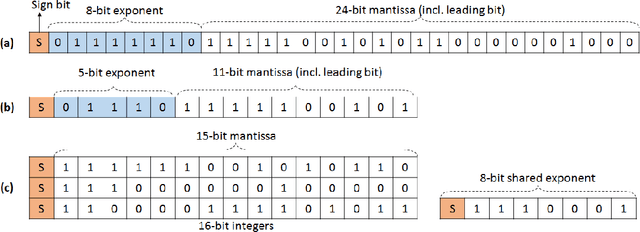
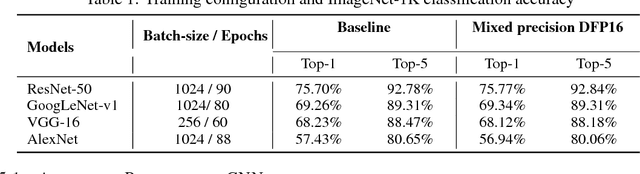
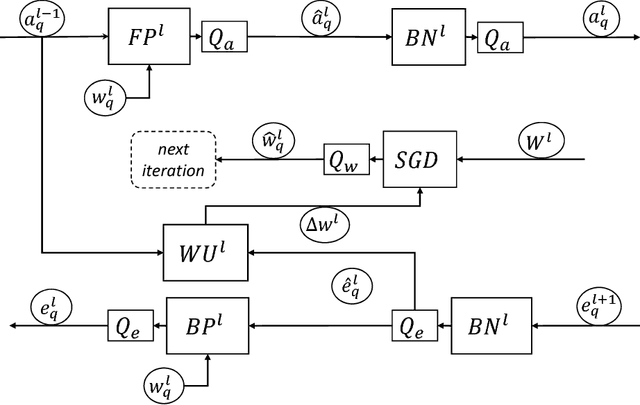
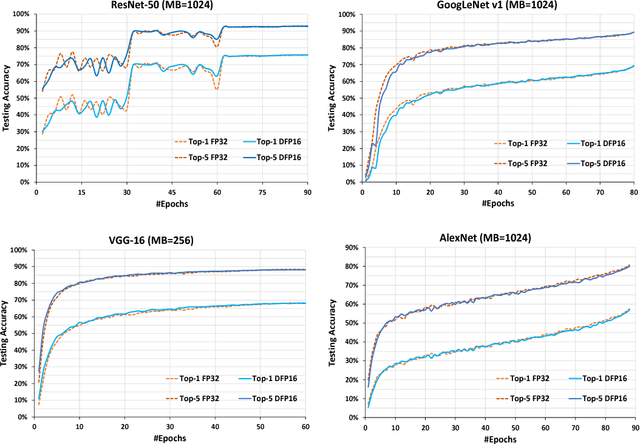
The state-of-the-art (SOTA) for mixed precision training is dominated by variants of low precision floating point operations, and in particular, FP16 accumulating into FP32 Micikevicius et al. (2017). On the other hand, while a lot of research has also happened in the domain of low and mixed-precision Integer training, these works either present results for non-SOTA networks (for instance only AlexNet for ImageNet-1K), or relatively small datasets (like CIFAR-10). In this work, we train state-of-the-art visual understanding neural networks on the ImageNet-1K dataset, with Integer operations on General Purpose (GP) hardware. In particular, we focus on Integer Fused-Multiply-and-Accumulate (FMA) operations which take two pairs of INT16 operands and accumulate results into an INT32 output.We propose a shared exponent representation of tensors and develop a Dynamic Fixed Point (DFP) scheme suitable for common neural network operations. The nuances of developing an efficient integer convolution kernel is examined, including methods to handle overflow of the INT32 accumulator. We implement CNN training for ResNet-50, GoogLeNet-v1, VGG-16 and AlexNet; and these networks achieve or exceed SOTA accuracy within the same number of iterations as their FP32 counterparts without any change in hyper-parameters and with a 1.8X improvement in end-to-end training throughput. To the best of our knowledge these results represent the first INT16 training results on GP hardware for ImageNet-1K dataset using SOTA CNNs and achieve highest reported accuracy using half-precision
On Scale-out Deep Learning Training for Cloud and HPC
Jan 24, 2018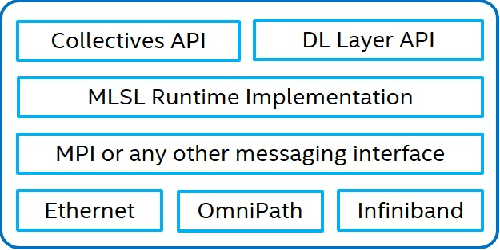
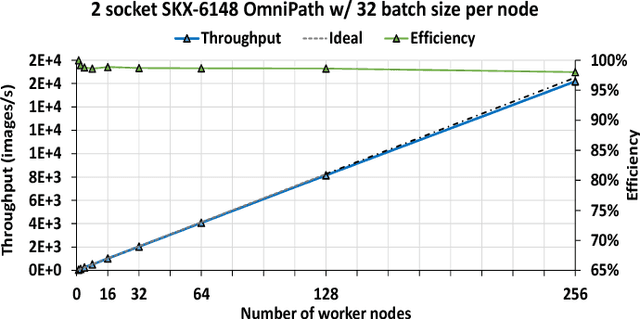
The exponential growth in use of large deep neural networks has accelerated the need for training these deep neural networks in hours or even minutes. This can only be achieved through scalable and efficient distributed training, since a single node/card cannot satisfy the compute, memory, and I/O requirements of today's state-of-the-art deep neural networks. However, scaling synchronous Stochastic Gradient Descent (SGD) is still a challenging problem and requires continued research/development. This entails innovations spanning algorithms, frameworks, communication libraries, and system design. In this paper, we describe the philosophy, design, and implementation of Intel Machine Learning Scalability Library (MLSL) and present proof-points demonstrating scaling DL training on 100s to 1000s of nodes across Cloud and HPC systems.
RAIL: Risk-Averse Imitation Learning
Nov 29, 2017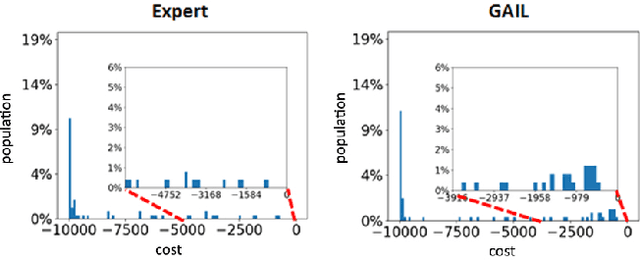
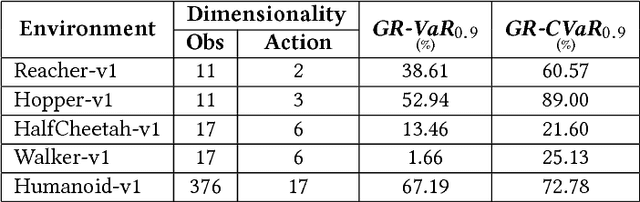
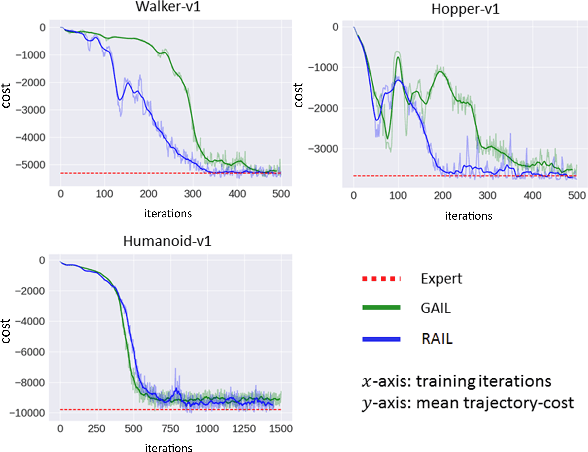
Imitation learning algorithms learn viable policies by imitating an expert's behavior when reward signals are not available. Generative Adversarial Imitation Learning (GAIL) is a state-of-the-art algorithm for learning policies when the expert's behavior is available as a fixed set of trajectories. We evaluate in terms of the expert's cost function and observe that the distribution of trajectory-costs is often more heavy-tailed for GAIL-agents than the expert at a number of benchmark continuous-control tasks. Thus, high-cost trajectories, corresponding to tail-end events of catastrophic failure, are more likely to be encountered by the GAIL-agents than the expert. This makes the reliability of GAIL-agents questionable when it comes to deployment in risk-sensitive applications like robotic surgery and autonomous driving. In this work, we aim to minimize the occurrence of tail-end events by minimizing tail risk within the GAIL framework. We quantify tail risk by the Conditional-Value-at-Risk (CVaR) of trajectories and develop the Risk-Averse Imitation Learning (RAIL) algorithm. We observe that the policies learned with RAIL show lower tail-end risk than those of vanilla GAIL. Thus the proposed RAIL algorithm appears as a potent alternative to GAIL for improved reliability in risk-sensitive applications.
Ternary Residual Networks
Oct 31, 2017

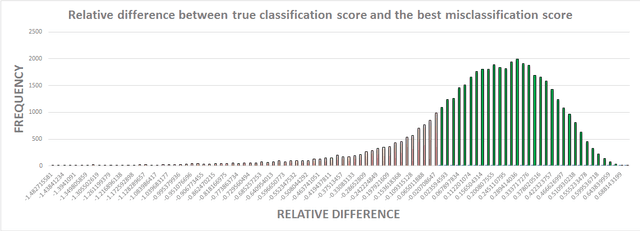

Sub-8-bit representation of DNNs incur some discernible loss of accuracy despite rigorous (re)training at low-precision. Such loss of accuracy essentially makes them equivalent to a much shallower counterpart, diminishing the power of being deep networks. To address this problem of accuracy drop we introduce the notion of \textit{residual networks} where we add more low-precision edges to sensitive branches of the sub-8-bit network to compensate for the lost accuracy. Further, we present a perturbation theory to identify such sensitive edges. Aided by such an elegant trade-off between accuracy and compute, the 8-2 model (8-bit activations, ternary weights), enhanced by ternary residual edges, turns out to be sophisticated enough to achieve very high accuracy ($\sim 1\%$ drop from our FP-32 baseline), despite $\sim 1.6\times$ reduction in model size, $\sim 26\times$ reduction in number of multiplications, and potentially $\sim 2\times$ power-performance gain comparing to 8-8 representation, on the state-of-the-art deep network ResNet-101 pre-trained on ImageNet dataset. Moreover, depending on the varying accuracy requirements in a dynamic environment, the deployed low-precision model can be upgraded/downgraded on-the-fly by partially enabling/disabling residual connections. For example, disabling the least important residual connections in the above enhanced network, the accuracy drop is $\sim 2\%$ (from FP32), despite $\sim 1.9\times$ reduction in model size, $\sim 32\times$ reduction in number of multiplications, and potentially $\sim 2.3\times$ power-performance gain comparing to 8-8 representation. Finally, all the ternary connections are sparse in nature, and the ternary residual conversion can be done in a resource-constraint setting with no low-precision (re)training.
Ternary Neural Networks with Fine-Grained Quantization
May 30, 2017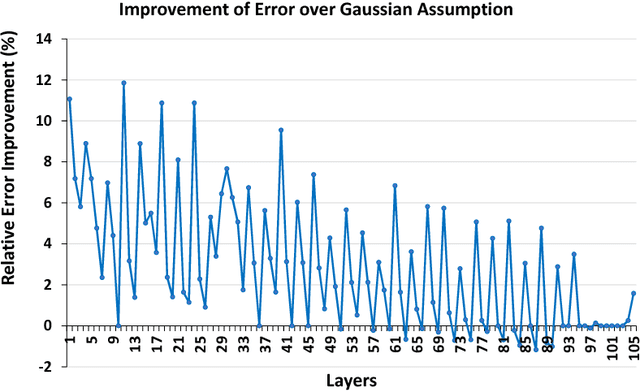
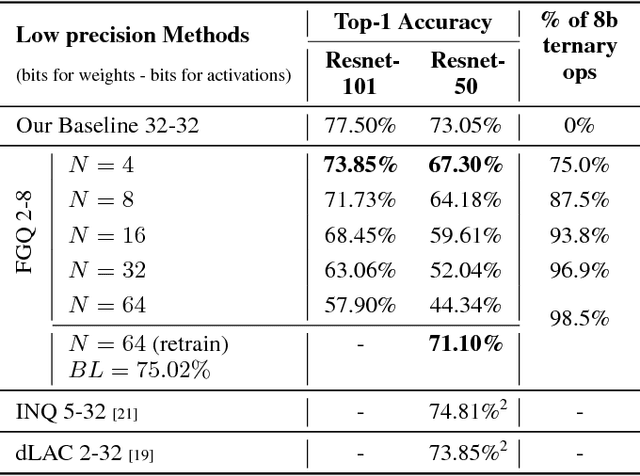
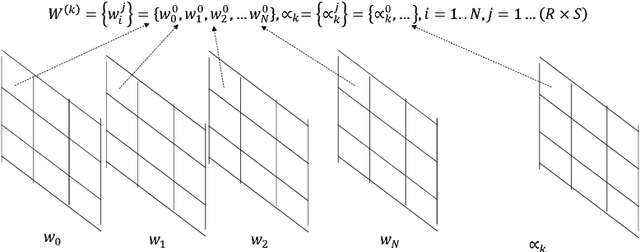
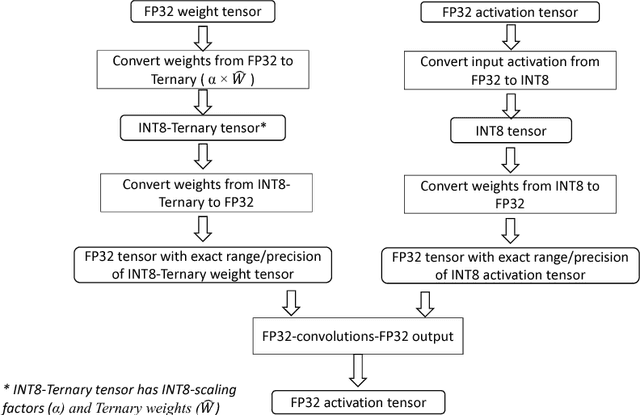
We propose a novel fine-grained quantization (FGQ) method to ternarize pre-trained full precision models, while also constraining activations to 8 and 4-bits. Using this method, we demonstrate a minimal loss in classification accuracy on state-of-the-art topologies without additional training. We provide an improved theoretical formulation that forms the basis for a higher quality solution using FGQ. Our method involves ternarizing the original weight tensor in groups of $N$ weights. Using $N=4$, we achieve Top-1 accuracy within $3.7\%$ and $4.2\%$ of the baseline full precision result for Resnet-101 and Resnet-50 respectively, while eliminating $75\%$ of all multiplications. These results enable a full 8/4-bit inference pipeline, with best-reported accuracy using ternary weights on ImageNet dataset, with a potential of $9\times$ improvement in performance. Also, for smaller networks like AlexNet, FGQ achieves state-of-the-art results. We further study the impact of group size on both performance and accuracy. With a group size of $N=64$, we eliminate $\approx99\%$ of the multiplications; however, this introduces a noticeable drop in accuracy, which necessitates fine tuning the parameters at lower precision. We address this by fine-tuning Resnet-50 with 8-bit activations and ternary weights at $N=64$, improving the Top-1 accuracy to within $4\%$ of the full precision result with $<30\%$ additional training overhead. Our final quantized model can run on a full 8-bit compute pipeline using 2-bit weights and has the potential of up to $15\times$ improvement in performance compared to baseline full-precision models.
Mixed Low-precision Deep Learning Inference using Dynamic Fixed Point
Feb 01, 2017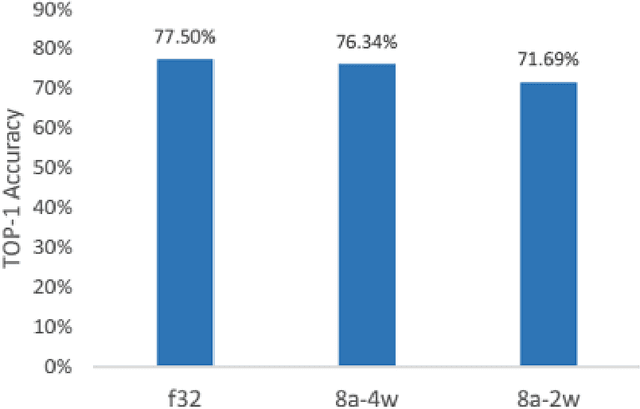
We propose a cluster-based quantization method to convert pre-trained full precision weights into ternary weights with minimal impact on the accuracy. In addition, we also constrain the activations to 8-bits thus enabling sub 8-bit full integer inference pipeline. Our method uses smaller clusters of N filters with a common scaling factor to minimize the quantization loss, while also maximizing the number of ternary operations. We show that with a cluster size of N=4 on Resnet-101, can achieve 71.8% TOP-1 accuracy, within 6% of the best full precision results while replacing ~85% of all multiplications with 8-bit accumulations. Using the same method with 4-bit weights achieves 76.3% TOP-1 accuracy which within 2% of the full precision result. We also study the impact of the size of the cluster on both performance and accuracy, larger cluster sizes N=64 can replace ~98% of the multiplications with ternary operations but introduces significant drop in accuracy which necessitates fine tuning the parameters with retraining the network at lower precision. To address this we have also trained low-precision Resnet-50 with 8-bit activations and ternary weights by pre-initializing the network with full precision weights and achieve 68.9% TOP-1 accuracy within 4 additional epochs. Our final quantized model can run on a full 8-bit compute pipeline, with a potential 16x improvement in performance compared to baseline full-precision models.
Distributed Deep Learning Using Synchronous Stochastic Gradient Descent
Feb 22, 2016
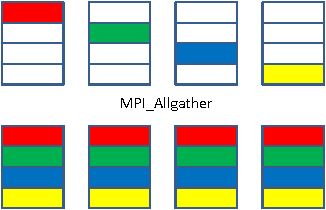
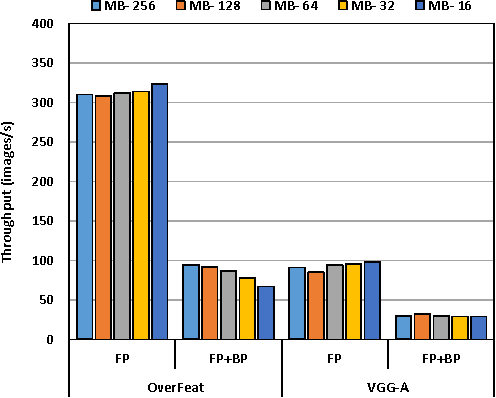
We design and implement a distributed multinode synchronous SGD algorithm, without altering hyper parameters, or compressing data, or altering algorithmic behavior. We perform a detailed analysis of scaling, and identify optimal design points for different networks. We demonstrate scaling of CNNs on 100s of nodes, and present what we believe to be record training throughputs. A 512 minibatch VGG-A CNN training run is scaled 90X on 128 nodes. Also 256 minibatch VGG-A and OverFeat-FAST networks are scaled 53X and 42X respectively on a 64 node cluster. We also demonstrate the generality of our approach via best-in-class 6.5X scaling for a 7-layer DNN on 16 nodes. Thereafter we attempt to democratize deep-learning by training on an Ethernet based AWS cluster and show ~14X scaling on 16 nodes.