 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Language ID to Calculate Intermediate CTC Loss for Enhanced Code-Switching Speech Recognition
Dec 15, 2023In recent years, end-to-end speech recognition has emerged as a technology that integrates the acoustic, pronunciation dictionary, and language model components of the traditional Automatic Speech Recognition model. It is possible to achieve human-like recognition without the need to build a pronunciation dictionary in advance. However, due to the relative scarcity of training data on code-switching, the performance of ASR models tends to degrade drastically when encountering this phenomenon. Most past studies have simplified the learning complexity of the model by splitting the code-switching task into multiple tasks dealing with a single language and then learning the domain-specific knowledge of each language separately. Therefore, in this paper, we attempt to introduce language identification information into the middle layer of the ASR model's encoder. We aim to generate acoustic features that imply language distinctions in a more implicit way, reducing the model's confusion when dealing with language switching.
Preserving Phonemic Distinctions for Ordinal Regression: A Novel Loss Function for Automatic Pronunciation Assessment
Oct 04, 2023



Automatic pronunciation assessment (APA) manages to quantify the pronunciation proficiency of a second language (L2) learner in a language. Prevailing approaches to APA normally leverage neural models trained with a regression loss function, such as the mean-squared error (MSE) loss, for proficiency level prediction. Despite most regression models can effectively capture the ordinality of proficiency levels in the feature space, they are confronted with a primary obstacle that different phoneme categories with the same proficiency level are inevitably forced to be close to each other, retaining less phoneme-discriminative information. On account of this, we devise a phonemic contrast ordinal (PCO) loss for training regression-based APA models, which aims to preserve better phonemic distinctions between phoneme categories meanwhile considering ordinal relationships of the regression target output. Specifically, we introduce a phoneme-distinct regularizer into the MSE loss, which encourages feature representations of different phoneme categories to be far apart while simultaneously pulling closer the representations belonging to the same phoneme category by means of weighted distances. An extensive set of experiments carried out on the speechocean762 benchmark dataset suggest the feasibility and effectiveness of our model in relation to some existing state-of-the-art models.
AVATAR: Robust Voice Search Engine Leveraging Autoregressive Document Retrieval and Contrastive Learning
Sep 04, 2023



Voice, as input, has progressively become popular on mobiles and seems to transcend almost entirely text input. Through voice, the voice search (VS) system can provide a more natural way to meet user's information needs. However, errors from the automatic speech recognition (ASR) system can be catastrophic to the VS system. Building on the recent advanced lightweight autoregressive retrieval model, which has the potential to be deployed on mobiles, leading to a more secure and personal VS assistant. This paper presents a novel study of VS leveraging autoregressive retrieval and tackles the crucial problems facing VS, viz. the performance drop caused by ASR noise, via data augmentations and contrastive learning, showing how explicit and implicit modeling the noise patterns can alleviate the problems. A series of experiments conducted on the Open-Domain Question Answering (ODSQA) confirm our approach's effectiveness and robustness in relation to some strong baseline systems.
Naaloss: Rethinking the objective of speech enhancement
Aug 24, 2023



Reducing noise interference is crucial for automatic speech recognition (ASR) in a real-world scenario. However, most single-channel speech enhancement (SE) generates "processing artifacts" that negatively affect ASR performance. Hence, in this study, we suggest a Noise- and Artifacts-aware loss function, NAaLoss, to ameliorate the influence of artifacts from a novel perspective. NAaLoss considers the loss of estimation, de-artifact, and noise ignorance, enabling the learned SE to individually model speech, artifacts, and noise. We examine two SE models (simple/advanced) learned with NAaLoss under various input scenarios (clean/noisy) using two configurations of the ASR system (with/without noise robustness). Experiments reveal that NAaLoss significantly improves the ASR performance of most setups while preserving the quality of SE toward perception and intelligibility. Furthermore, we visualize artifacts through waveforms and spectrograms, and explain their impact on ASR.
A Hierarchical Context-aware Modeling Approach for Multi-aspect and Multi-granular Pronunciation Assessment
Jun 07, 2023



Automatic Pronunciation Assessment (APA) plays a vital role in Computer-assisted Pronunciation Training (CAPT) when evaluating a second language (L2) learner's speaking proficiency. However, an apparent downside of most de facto methods is that they parallelize the modeling process throughout different speech granularities without accounting for the hierarchical and local contextual relationships among them. In light of this, a novel hierarchical approach is proposed in this paper for multi-aspect and multi-granular APA. Specifically, we first introduce the notion of sup-phonemes to explore more subtle semantic traits of L2 speakers. Second, a depth-wise separable convolution layer is exploited to better encapsulate the local context cues at the sub-word level. Finally, we use a score-restraint attention pooling mechanism to predict the sentence-level scores and optimize the component models with a multitask learning (MTL) framework. Extensive experiments carried out on a publicly-available benchmark dataset, viz. speechocean762, demonstrate the efficacy of our approach in relation to some cutting-edge baselines.
3M: An Effective Multi-view, Multi-granularity, and Multi-aspect Modeling Approach to English Pronunciation Assessment
Aug 19, 2022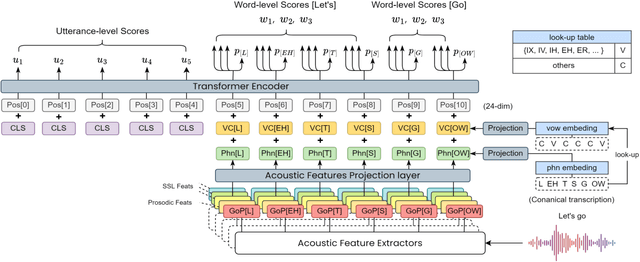
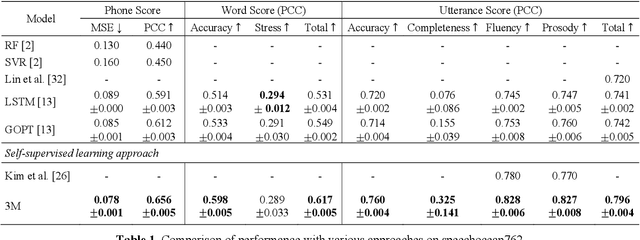
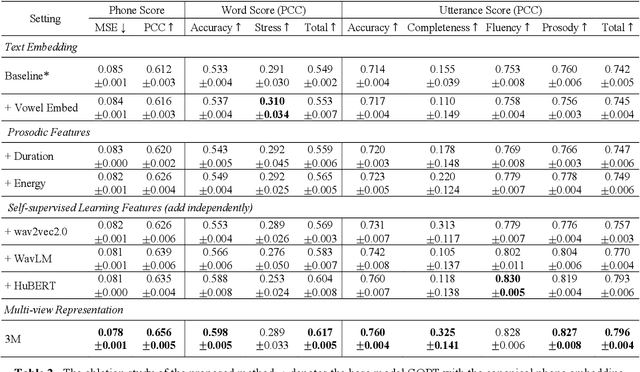
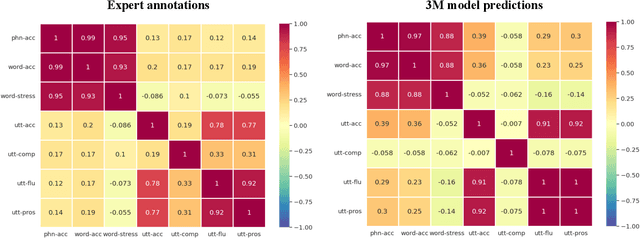
As an indispensable ingredient of computer-assisted pronunciation training (CAPT), automatic pronunciation assessment (APA) plays a pivotal role in aiding self-directed language learners by providing multi-aspect and timely feedback. However, there are at least two potential obstacles that might hinder its performance for practical use. On one hand, most of the studies focus exclusively on leveraging segmental (phonetic)-level features such as goodness of pronunciation (GOP); this, however, may cause a discrepancy of feature granularity when performing suprasegmental (prosodic)-level pronunciation assessment. On the other hand, automatic pronunciation assessments still suffer from the lack of large-scale labeled speech data of non-native speakers, which inevitably limits the performance of pronunciation assessment. In this paper, we tackle these problems by integrating multiple prosodic and phonological features to provide a multi-view, multi-granularity, and multi-aspect (3M) pronunciation modeling. Specifically, we augment GOP with prosodic and self-supervised learning (SSL) features, and meanwhile develop a vowel/consonant positional embedding for a more phonology-aware automatic pronunciation assessment. A series of experiments conducted on the publicly-available speechocean762 dataset show that our approach can obtain significant improvements on several assessment granularities in comparison with previous work, especially on the assessment of speaking fluency and speech prosody.
Geometric Learning of Hidden Markov Models via a Method of Moments Algorithm
Jul 02, 2022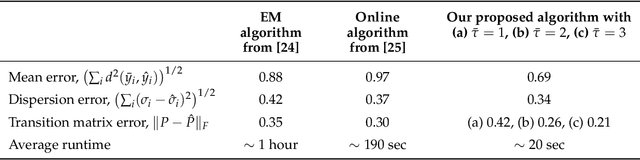

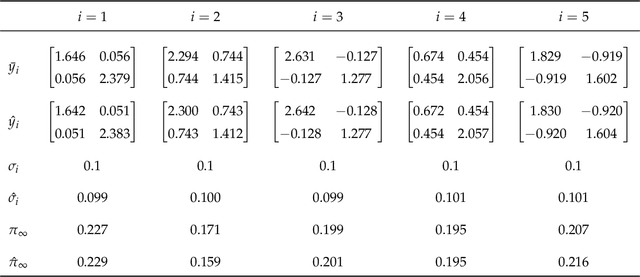
We present a novel algorithm for learning the parameters of hidden Markov models (HMMs) in a geometric setting where the observations take values in Riemannian manifolds. In particular, we elevate a recent second-order method of moments algorithm that incorporates non-consecutive correlations to a more general setting where observations take place in a Riemannian symmetric space of non-positive curvature and the observation likelihoods are Riemannian Gaussians. The resulting algorithm decouples into a Riemannian Gaussian mixture model estimation algorithm followed by a sequence of convex optimization procedures. We demonstrate through examples that the learner can result in significantly improved speed and numerical accuracy compared to existing learners.
Conversational speech recognition leveraging effective fusion methods for cross-utterance language modeling
Nov 05, 2021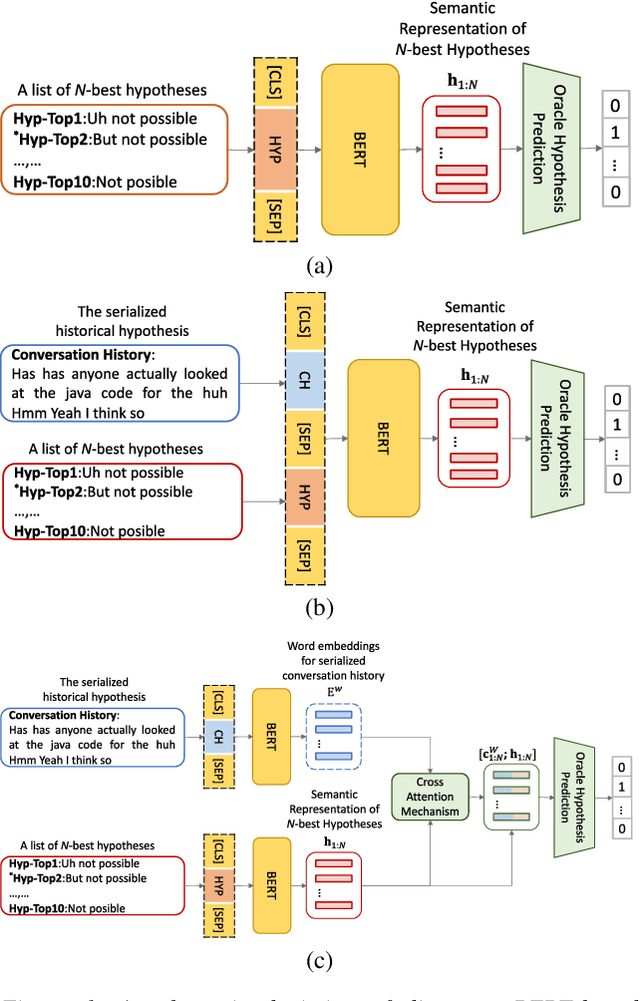
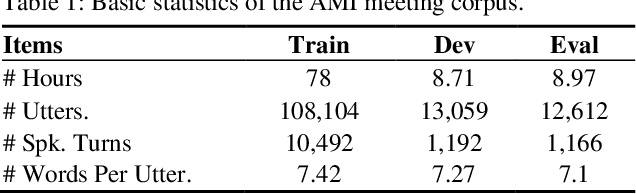
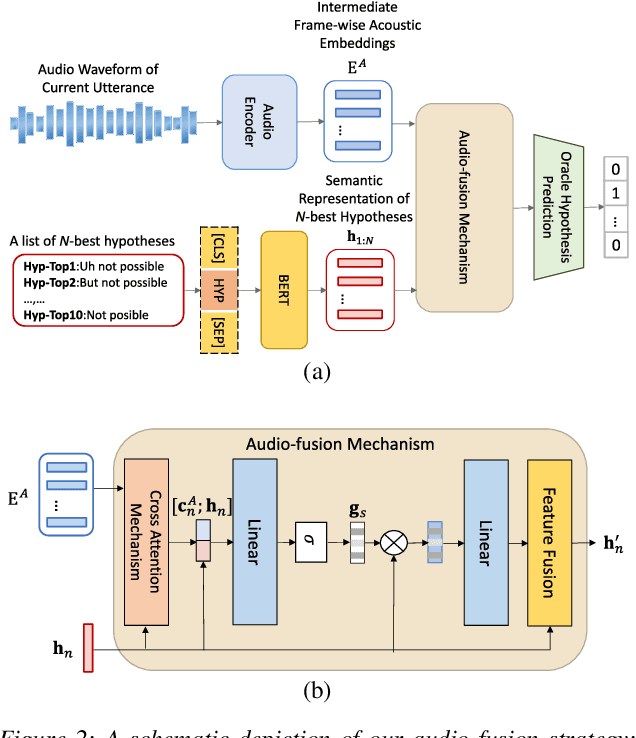

Conversational speech normally is embodied with loose syntactic structures at the utterance level but simultaneously exhibits topical coherence relations across consecutive utterances. Prior work has shown that capturing longer context information with a recurrent neural network or long short-term memory language model (LM) may suffer from the recent bias while excluding the long-range context. In order to capture the long-term semantic interactions among words and across utterances, we put forward disparate conversation history fusion methods for language modeling in automatic speech recognition (ASR) of conversational speech. Furthermore, a novel audio-fusion mechanism is introduced, which manages to fuse and utilize the acoustic embeddings of a current utterance and the semantic content of its corresponding conversation history in a cooperative way. To flesh out our ideas, we frame the ASR N-best hypothesis rescoring task as a prediction problem, leveraging BERT, an iconic pre-trained LM, as the ingredient vehicle to facilitate selection of the oracle hypothesis from a given N-best hypothesis list. Empirical experiments conducted on the AMI benchmark dataset seem to demonstrate the feasibility and efficacy of our methods in relation to some current top-of-line methods.
Exploring Non-Autoregressive End-To-End Neural Modeling For English Mispronunciation Detection And Diagnosis
Nov 01, 2021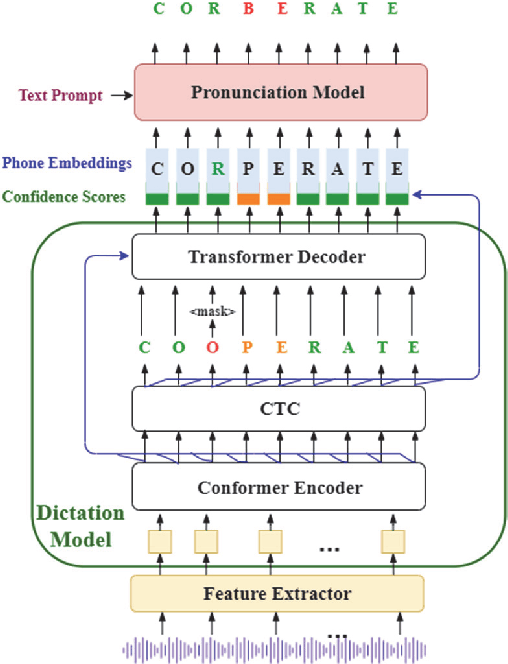
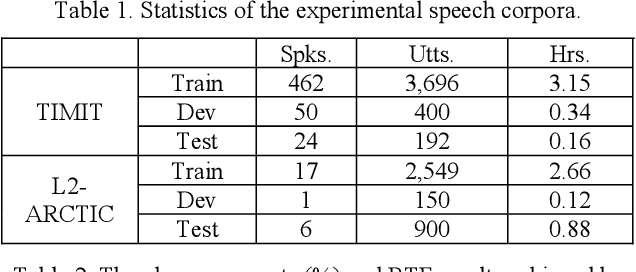
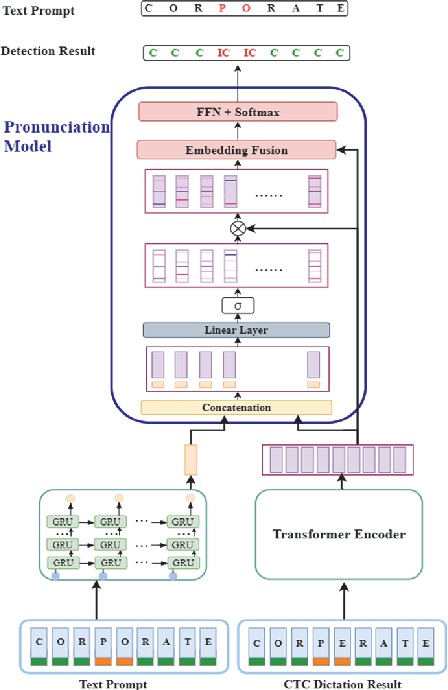
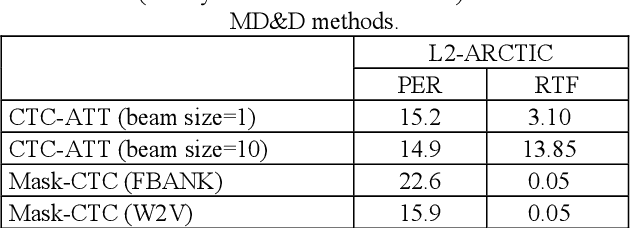
End-to-end (E2E) neural modeling has emerged as one predominant school of thought to develop computer-assisted language training (CAPT) systems, showing competitive performance to conventional pronunciation-scoring based methods. However, current E2E neural methods for CAPT are faced with at least two pivotal challenges. On one hand, most of the E2E methods operate in an autoregressive manner with left-to-right beam search to dictate the pronunciations of an L2 learners. This however leads to very slow inference speed, which inevitably hinders their practical use. On the other hand, E2E neural methods are normally data greedy and meanwhile an insufficient amount of nonnative training data would often reduce their efficacy on mispronunciation detection and diagnosis (MD&D). In response, we put forward a novel MD&D method that leverages non-autoregressive (NAR) E2E neural modeling to dramatically speed up the inference time while maintaining performance in line with the conventional E2E neural methods. In addition, we design and develop a pronunciation modeling network stacked on top of the NAR E2E models of our method to further boost the effectiveness of MD&D. Empirical experiments conducted on the L2-ARCTIC English dataset seems to validate the feasibility of our method, in comparison to some top-of-the-line E2E models and an iconic pronunciation-scoring based method built on a DNN-HMM acoustic model.
Improving End-To-End Modeling for Mispronunciation Detection with Effective Augmentation Mechanisms
Oct 17, 2021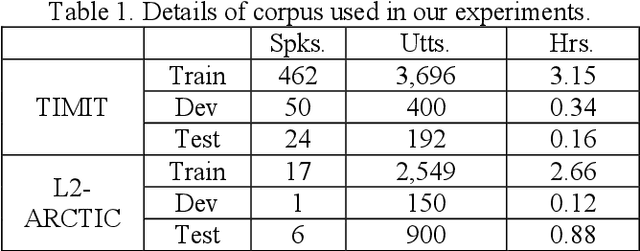
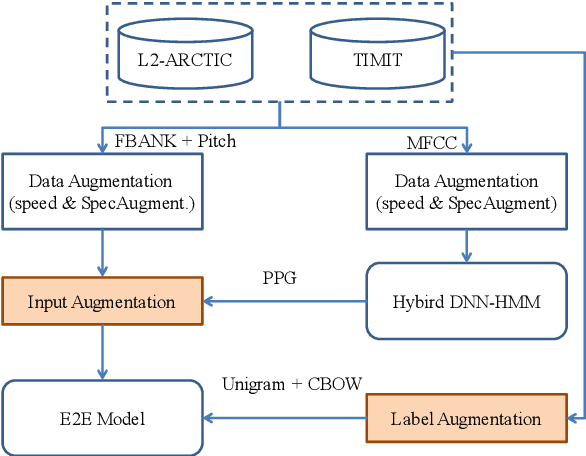
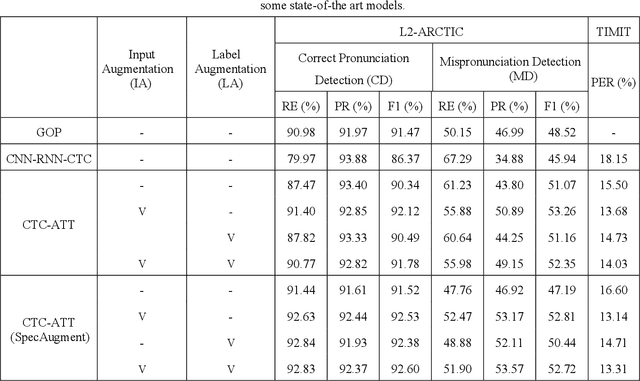
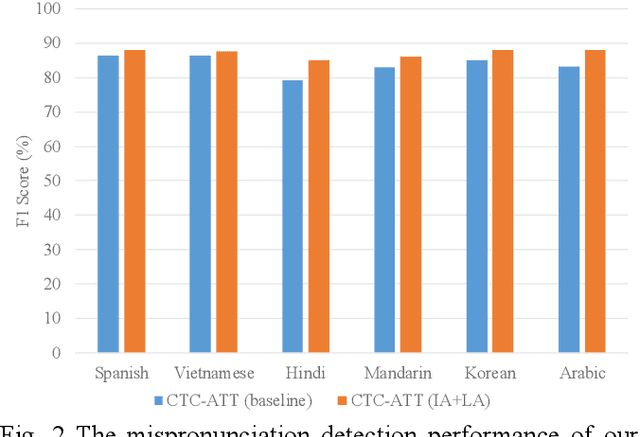
Recently, end-to-end (E2E) models, which allow to take spectral vector sequences of L2 (second-language) learners' utterances as input and produce the corresponding phone-level sequences as output, have attracted much research attention in developing mispronunciation detection (MD) systems. However, due to the lack of sufficient labeled speech data of L2 speakers for model estimation, E2E MD models are prone to overfitting in relation to conventional ones that are built on DNN-HMM acoustic models. To alleviate this critical issue, we in this paper propose two modeling strategies to enhance the discrimination capability of E2E MD models, each of which can implicitly leverage the phonetic and phonological traits encoded in a pretrained acoustic model and contained within reference transcripts of the training data, respectively. The first one is input augmentation, which aims to distill knowledge about phonetic discrimination from a DNN-HMM acoustic model. The second one is label augmentation, which manages to capture more phonological patterns from the transcripts of training data. A series of empirical experiments conducted on the L2-ARCTIC English dataset seem to confirm the efficacy of our E2E MD model when compared to some top-of-the-line E2E MD models and a classic pronunciation-scoring based method built on a DNN-HMM acoustic model.