 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Verbal Deception Detection using Transformers
Oct 06, 2022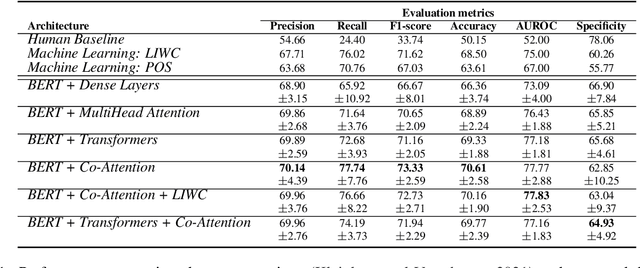
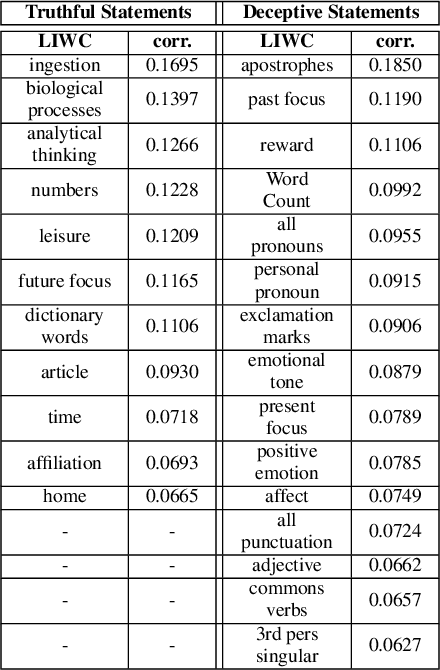
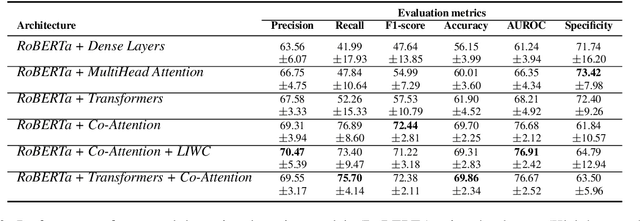
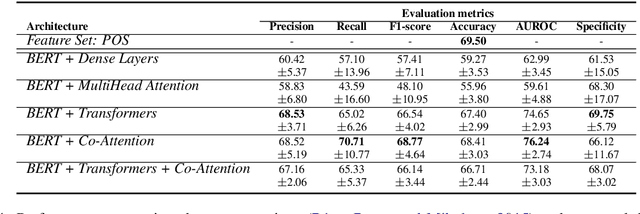
People are regularly confronted with potentially deceptive statements (e.g., fake news, misleading product reviews, or lies about activities). Only few works on automated text-based deception detection have exploited the potential of deep learning approaches. A critique of deep-learning methods is their lack of interpretability, preventing us from understanding the underlying (linguistic) mechanisms involved in deception. However, recent advancements have made it possible to explain some aspects of such models. This paper proposes and evaluates six deep-learning models, including combinations of BERT (and RoBERTa), MultiHead Attention, co-attentions, and transformers. To understand how the models reach their decisions, we then examine the model's predictions with LIME. We then zoom in on vocabulary uniqueness and the correlation of LIWC categories with the outcome class (truthful vs deceptive). The findings suggest that our transformer-based models can enhance automated deception detection performances (+2.11% in accuracy) and show significant differences pertinent to the usage of LIWC features in truthful and deceptive statements.
Who is GPT-3? An Exploration of Personality, Values and Demographics
Sep 28, 2022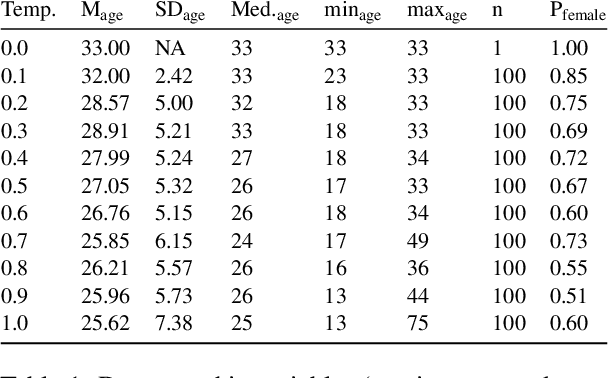
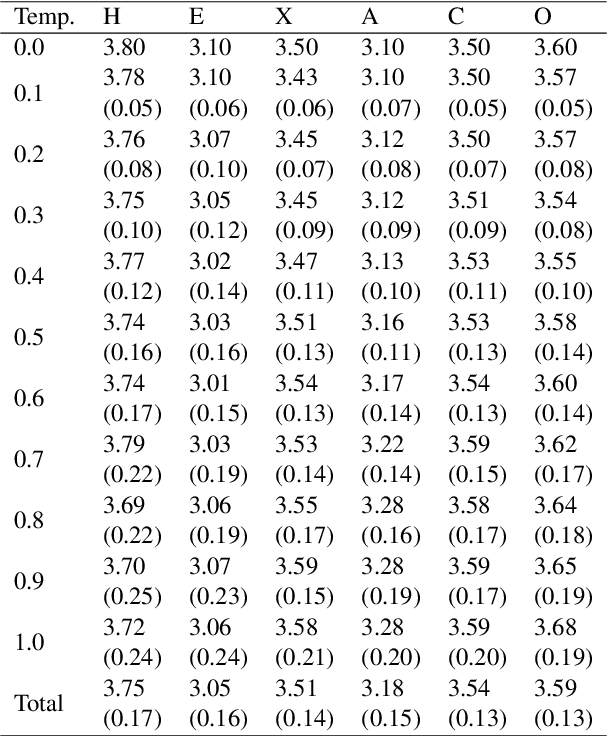
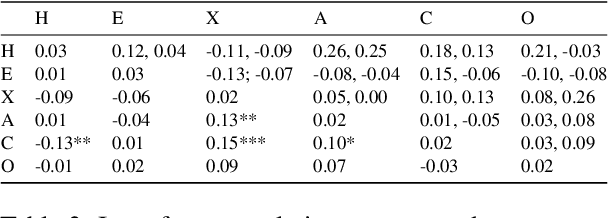
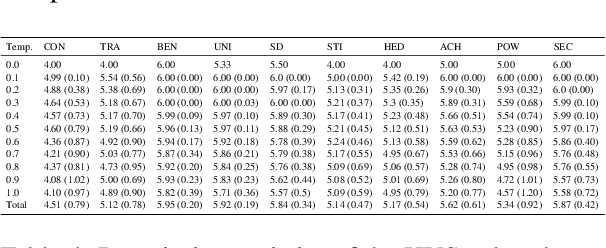
Language models such as GPT-3 have caused a furore in the research community. Some studies found that GPT-3 has some creative abilities and makes mistakes that are on par with human behaviour. This paper answers a related question: who is GPT-3? We administered two validated measurement tools to GPT-3 to assess its personality, the values it holds and its self-reported demographics. Our results show that GPT-3 scores similarly to human samples in terms of personality and - when provided with a model response memory - in terms of the values it holds. We provide the first evidence of psychological assessment of the GPT-3 model and thereby add to our understanding of the GPT-3 model. We close with suggestions for future research that moves social science closer to language models and vice versa.
Textwash -- automated open-source text anonymisation
Aug 27, 2022
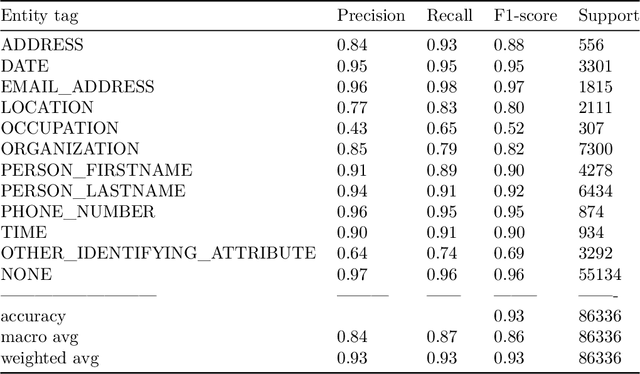
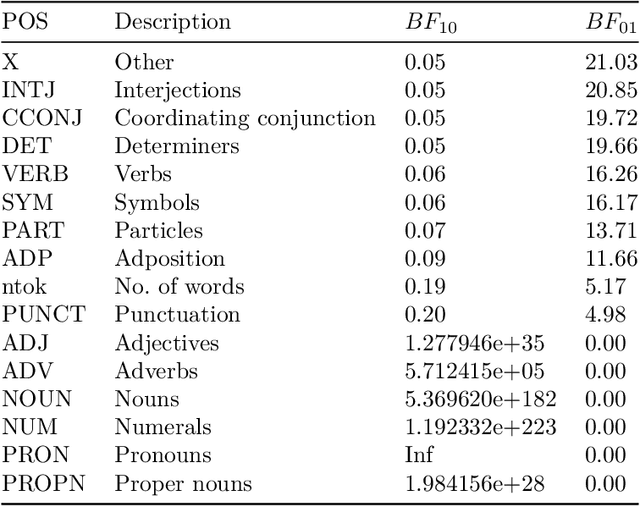
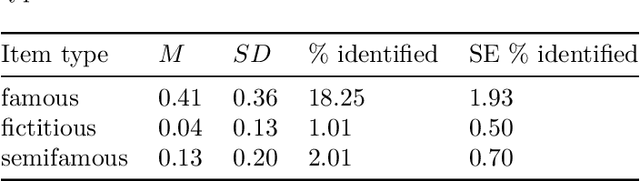
The increased use of text data in social science research has benefited from easy-to-access data (e.g., Twitter). That trend comes at the cost of research requiring sensitive but hard-to-share data (e.g., interview data, police reports, electronic health records). We introduce a solution to that stalemate with the open-source text anonymisation software_Textwash_. This paper presents the empirical evaluation of the tool using the TILD criteria: a technical evaluation (how accurate is the tool?), an information loss evaluation (how much information is lost in the anonymisation process?) and a de-anonymisation test (can humans identify individuals from anonymised text data?). The findings suggest that Textwash performs similar to state-of-the-art entity recognition models and introduces a negligible information loss of 0.84%. For the de-anonymisation test, we tasked humans to identify individuals by name from a dataset of crowdsourced person descriptions of very famous, semi-famous and non-existing individuals. The de-anonymisation rate ranged from 1.01-2.01% for the realistic use cases of the tool. We replicated the findings in a second study and concluded that Textwash succeeds in removing potentially sensitive information that renders detailed person descriptions practically anonymous.
Detecting DeFi Securities Violations from Token Smart Contract Code with Random Forest Classification
Dec 06, 2021


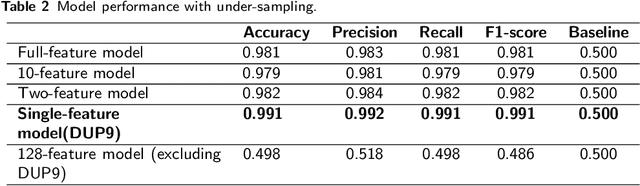
Decentralized Finance (DeFi) is a system of financial products and services built and delivered through smart contracts on various blockchains. In the past year, DeFi has gained popularity and market capitalization. However, it has also become an epicenter of cryptocurrency-related crime, in particular, various types of securities violations. The lack of Know Your Customer requirements in DeFi has left governments unsure of how to handle the magnitude of offending in this space. This study aims to address this problem with a machine learning approach to identify DeFi projects potentially engaging in securities violations based on their tokens' smart contract code. We adapt prior work on detecting specific types of securities violations across Ethereum more broadly, building a random forest classifier based on features extracted from DeFi projects' tokens' smart contract code. The final classifier achieves a 99.1% F1-score. Such high performance is surprising for any classification problem, however, from further feature-level, we find a single feature makes this a highly detectable problem. Another contribution of our study is a new dataset, comprised of (a) a verified ground truth dataset for tokens involved in securities violations and (b) a set of valid tokens from a DeFi aggregator which conducts due diligence on the projects it lists. This paper further discusses the use of our model by prosecutors in enforcement efforts and connects its potential use to the wider legal context.
Confounds and Overestimations in Fake Review Detection: Experimentally Controlling for Product-Ownership and Data-Origin
Oct 28, 2021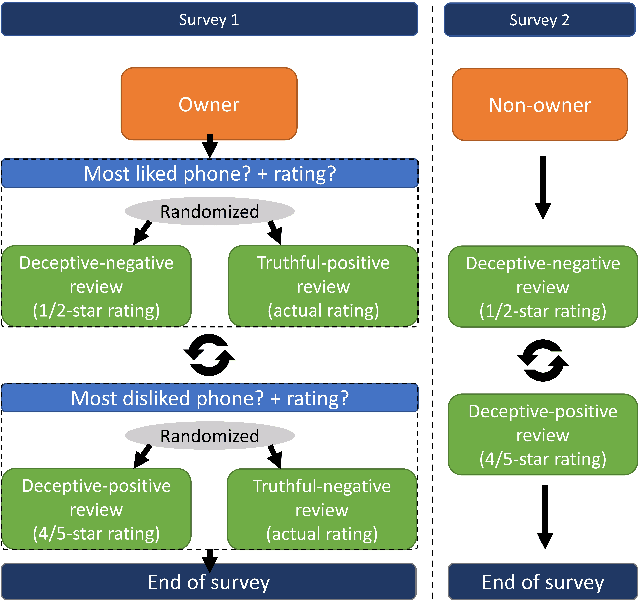
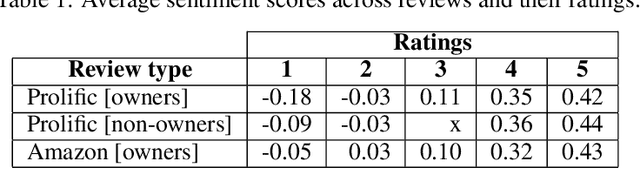
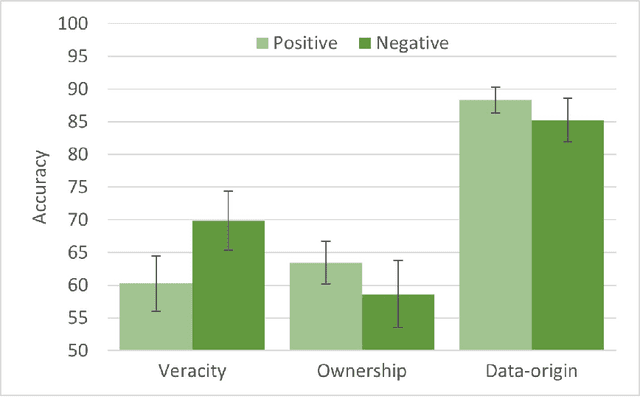
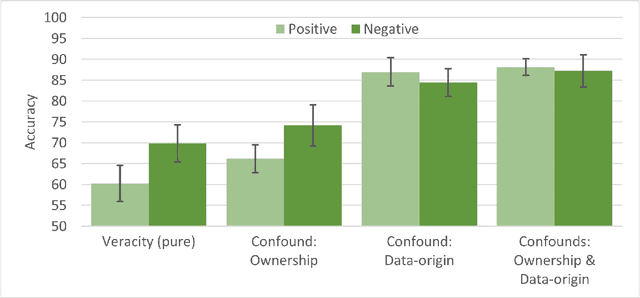
The popularity of online shopping is steadily increasing. At the same time, fake product reviewsare published widely and have the potential to affect consumer purchasing behavior. In response,previous work has developed automated methods for the detection of deceptive product reviews.However, studies vary considerably in terms of classification performance, and many use data thatcontain potential confounds, which makes it difficult to determine their validity. Two possibleconfounds are data-origin (i.e., the dataset is composed of more than one source) and productownership (i.e., reviews written by individuals who own or do not own the reviewed product). Inthe present study, we investigate the effect of both confounds for fake review detection. Using anexperimental design, we manipulate data-origin, product ownership, review polarity, and veracity.Supervised learning analysis suggests that review veracity (60.26 - 69.87%) is somewhat detectablebut reviews additionally confounded with product-ownership (66.19 - 74.17%), or with data-origin(84.44 - 86.94%) are easier to classify. Review veracity is most easily classified if confounded withproduct-ownership and data-origin combined (87.78 - 88.12%), suggesting overestimations of thetrue performance in other work. These findings are moderated by review polarity.
Contrasting Human- and Machine-Generated Word-Level Adversarial Examples for Text Classification
Sep 09, 2021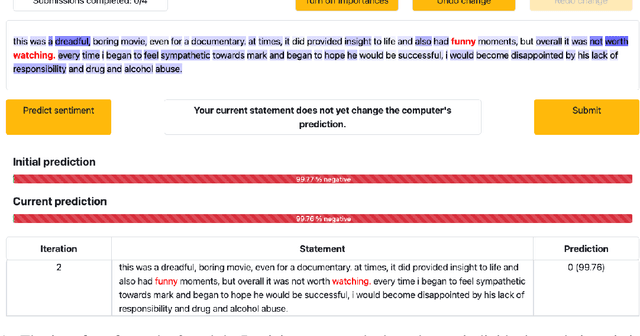
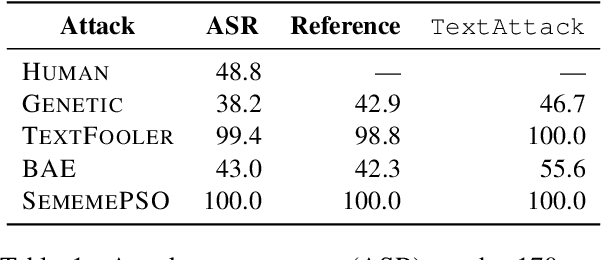
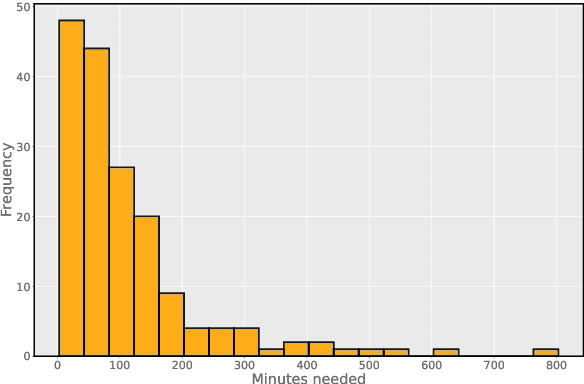
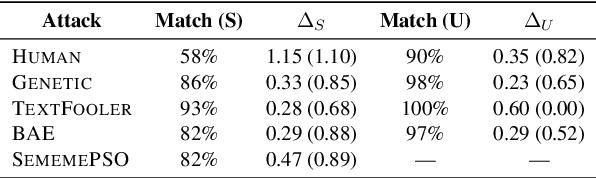
Research shows that natural language processing models are generally considered to be vulnerable to adversarial attacks; but recent work has drawn attention to the issue of validating these adversarial inputs against certain criteria (e.g., the preservation of semantics and grammaticality). Enforcing constraints to uphold such criteria may render attacks unsuccessful, raising the question of whether valid attacks are actually feasible. In this work, we investigate this through the lens of human language ability. We report on crowdsourcing studies in which we task humans with iteratively modifying words in an input text, while receiving immediate model feedback, with the aim of causing a sentiment classification model to misclassify the example. Our findings suggest that humans are capable of generating a substantial amount of adversarial examples using semantics-preserving word substitutions. We analyze how human-generated adversarial examples compare to the recently proposed TextFooler, Genetic, BAE and SememePSO attack algorithms on the dimensions naturalness, preservation of sentiment, grammaticality and substitution rate. Our findings suggest that human-generated adversarial examples are not more able than the best algorithms to generate natural-reading, sentiment-preserving examples, though they do so by being much more computationally efficient.
Worry, coping and resignation -- A repeated-measures study on emotional responses after a year in the pandemic
Jul 07, 2021
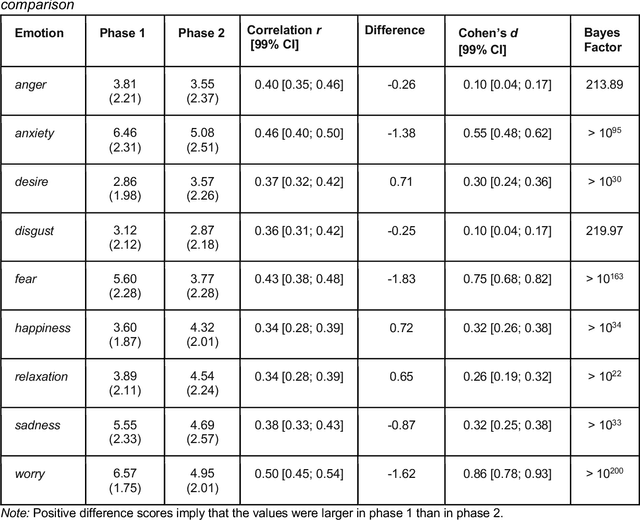
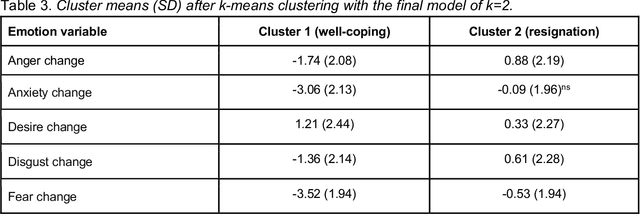
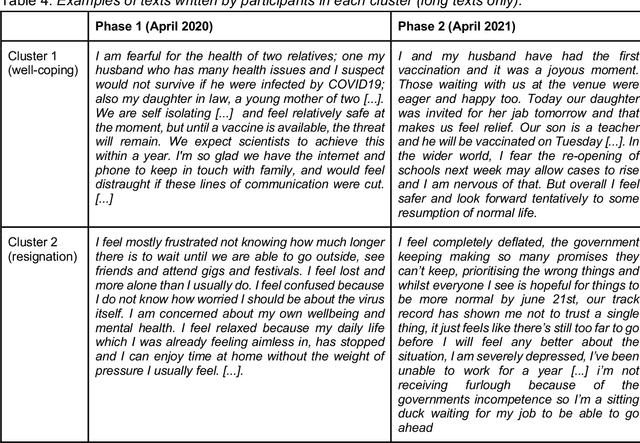
The introduction of COVID-19 lockdown measures and an outlook on return to normality are demanding societal changes. Among the most pressing questions is how individuals adjust to the pandemic. This paper examines the emotional responses to the pandemic in a repeated-measures design. Data (n=1698) were collected in April 2020 (during strict lockdown measures) and in April 2021 (when vaccination programmes gained traction). We asked participants to report their emotions and express these in text data. Statistical tests revealed an average trend towards better adjustment to the pandemic. However, clustering analyses suggested a more complex heterogeneous pattern with a well-coping and a resigning subgroup of participants. Linguistic computational analyses uncovered that topics and n-gram frequencies shifted towards attention to the vaccination programme and away from general worrying. Implications for public mental health efforts in identifying people at heightened risk are discussed. The dataset is made publicly available.
No Intruder, no Validity: Evaluation Criteria for Privacy-Preserving Text Anonymization
Mar 16, 2021
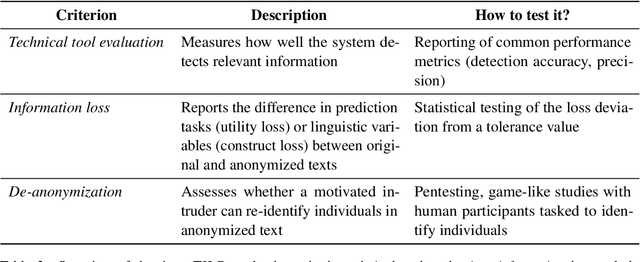
For sensitive text data to be shared among NLP researchers and practitioners, shared documents need to comply with data protection and privacy laws. There is hence a growing interest in automated approaches for text anonymization. However, measuring such methods' performance is challenging: missing a single identifying attribute can reveal an individual's identity. In this paper, we draw attention to this problem and argue that researchers and practitioners developing automated text anonymization systems should carefully assess whether their evaluation methods truly reflect the system's ability to protect individuals from being re-identified. We then propose TILD, a set of evaluation criteria that comprises an anonymization method's technical performance, the information loss resulting from its anonymization, and the human ability to de-anonymize redacted documents. These criteria may facilitate progress towards a standardized way for measuring anonymization performance.
The Grievance Dictionary: Understanding Threatening Language Use
Sep 10, 2020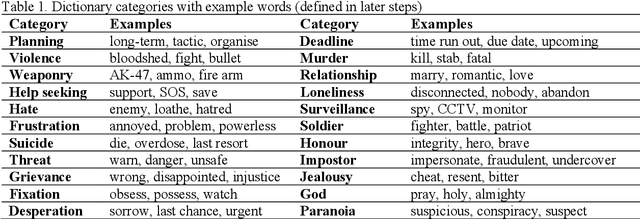
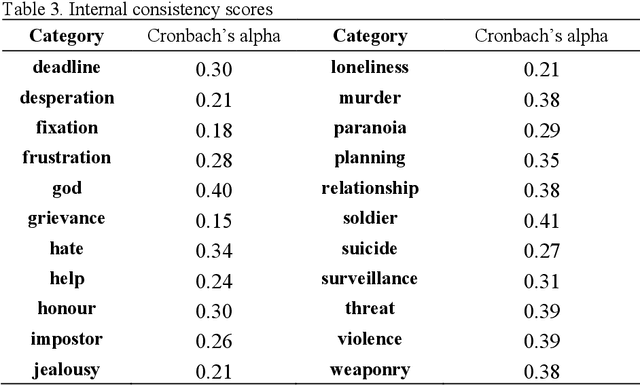
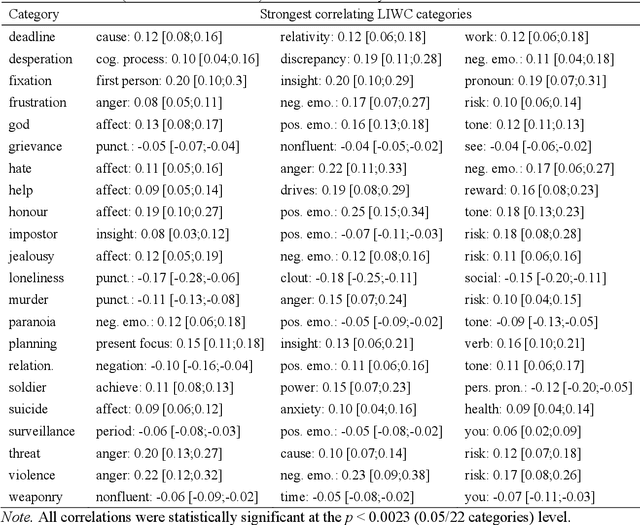
This paper introduces the Grievance Dictionary, a psycholinguistic dictionary which can be used to automatically understand language use in the context of grievance-fuelled violence threat assessment. We describe the development the dictionary, which was informed by suggestions from experienced threat assessment practitioners. These suggestions and subsequent human and computational word list generation resulted in a dictionary of 20,502 words annotated by 2,318 participants. The dictionary was validated by applying it to texts written by violent and non-violent individuals, showing strong evidence for a difference between populations in several dictionary categories. Further classification tasks showed promising performance, but future improvements are still needed. Finally, we provide instructions and suggestions for the use of the Grievance Dictionary by security professionals and (violence) researchers.
Too good to be true? Predicting author profiles from abusive language
Sep 03, 2020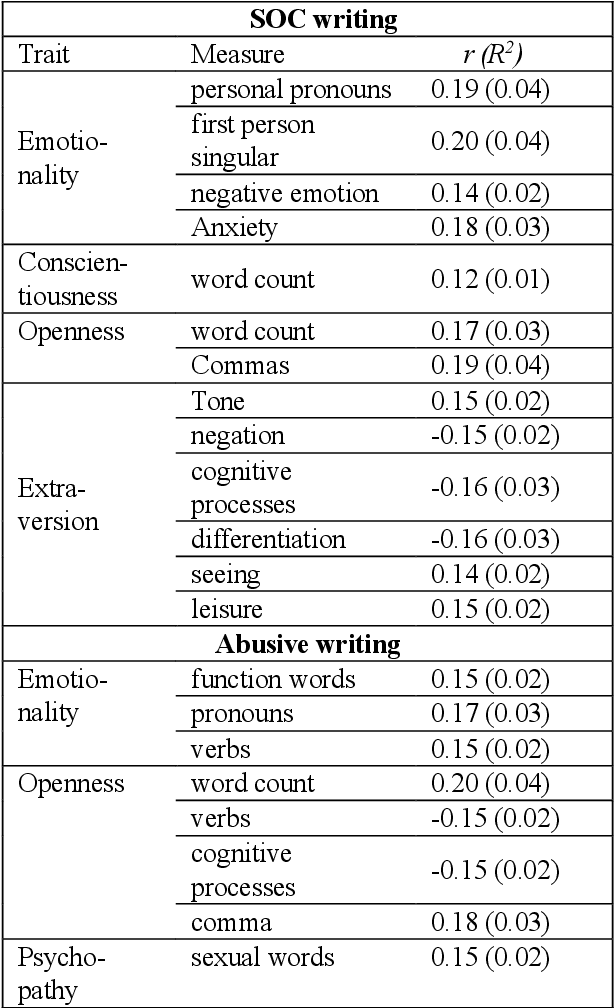
The problem of online threats and abuse could potentially be mitigated with a computational approach, where sources of abuse are better understood or identified through author profiling. However, abusive language constitutes a specific domain of language for which it has not yet been tested whether differences emerge based on a text author's personality, age, or gender. This study examines statistical relationships between author demographics and abusive vs normal language, and performs prediction experiments for personality, age, and gender. Although some statistical relationships were established between author characteristics and language use, these patterns did not translate to high prediction performance. Personality traits were predicted within 15% of their actual value, age was predicted with an error margin of 10 years, and gender was classified correctly in 70% of the cases. These results are poor when compared to previous research on author profiling, therefore we urge caution in applying this within the context of abusive language and threat assessment.