 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian-Dirichlet Posterior Dominance in Sequential Learning
Feb 09, 2018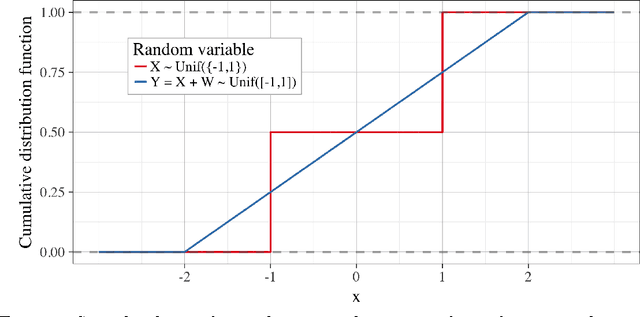
We consider the problem of sequential learning from categorical observations bounded in [0,1]. We establish an ordering between the Dirichlet posterior over categorical outcomes and a Gaussian posterior under observations with N(0,1) noise. We establish that, conditioned upon identical data with at least two observations, the posterior mean of the categorical distribution will always second-order stochastically dominate the posterior mean of the Gaussian distribution. These results provide a useful tool for the analysis of sequential learning under categorical outcomes.
Coordinated Exploration in Concurrent Reinforcement Learning
Feb 05, 2018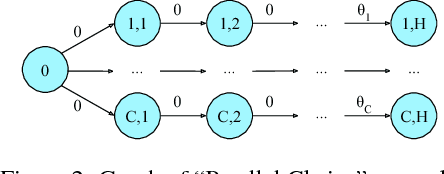
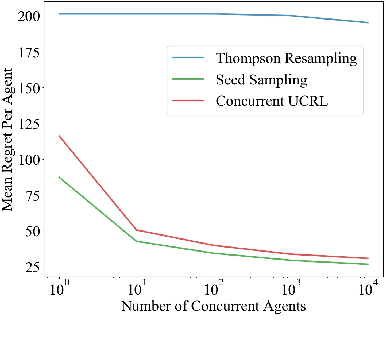
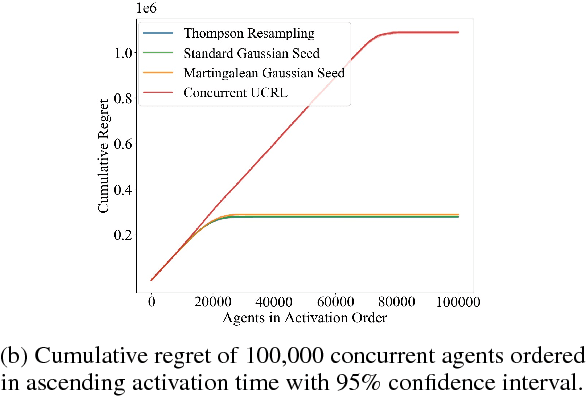
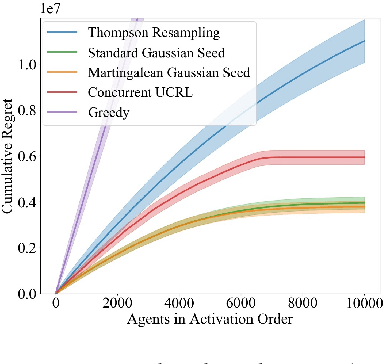
We consider a team of reinforcement learning agents that concurrently learn to operate in a common environment. We identify three properties - adaptivity, commitment, and diversity - which are necessary for efficient coordinated exploration and demonstrate that straightforward extensions to single-agent optimistic and posterior sampling approaches fail to satisfy them. As an alternative, we propose seed sampling, which extends posterior sampling in a manner that meets these requirements. Simulation results investigate how per-agent regret decreases as the number of agents grows, establishing substantial advantages of seed sampling over alternative exploration schemes.
Ensemble Sampling
Nov 22, 2017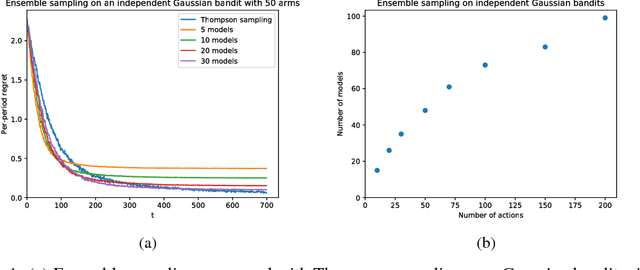
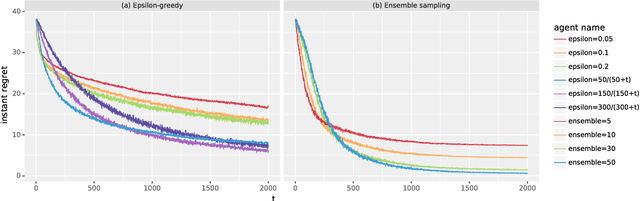
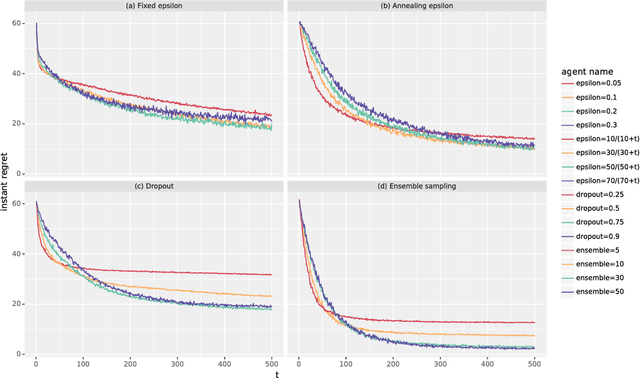
Thompson sampling has emerged as an effective heuristic for a broad range of online decision problems. In its basic form, the algorithm requires computing and sampling from a posterior distribution over models, which is tractable only for simple special cases. This paper develops ensemble sampling, which aims to approximate Thompson sampling while maintaining tractability even in the face of complex models such as neural networks. Ensemble sampling dramatically expands on the range of applications for which Thompson sampling is viable. We establish a theoretical basis that supports the approach and present computational results that offer further insight.
A Tutorial on Thompson Sampling
Nov 19, 2017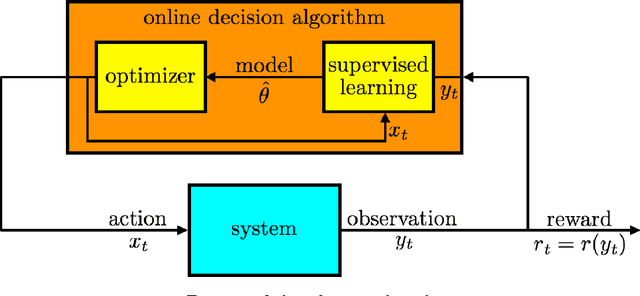
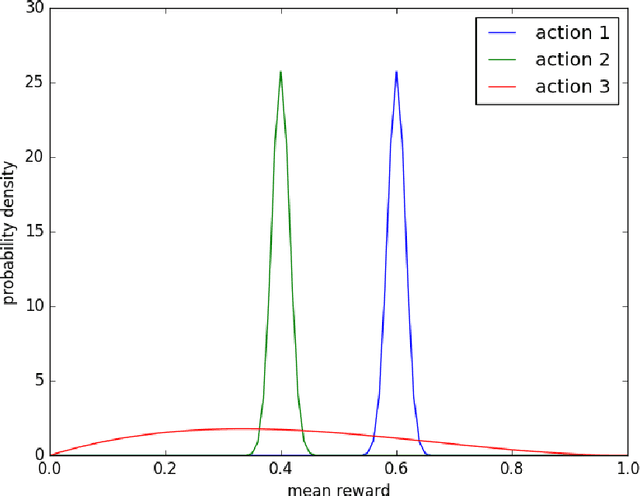
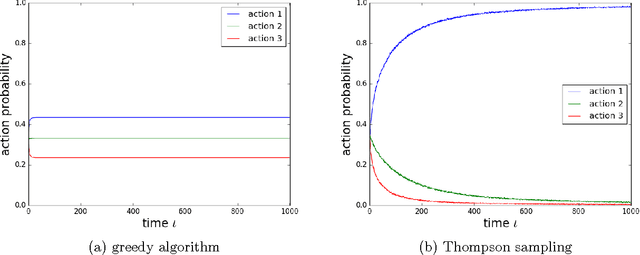
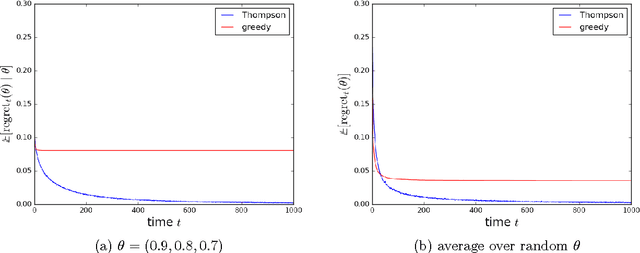
Thompson sampling is an algorithm for online decision problems where actions are taken sequentially in a manner that must balance between exploiting what is known to maximize immediate performance and investing to accumulate new information that may improve future performance. The algorithm addresses a broad range of problems in a computationally efficient manner and is therefore enjoying wide use. This tutorial covers the algorithm and its application, illustrating concepts through a range of examples, including Bernoulli bandit problems, shortest path problems, dynamic pricing, recommendation, active learning with neural networks, and reinforcement learning in Markov decision processes. Most of these problems involve complex information structures, where information revealed by taking an action informs beliefs about other actions. We will also discuss when and why Thompson sampling is or is not effective and relations to alternative algorithms.
Learning to Price with Reference Effects
Aug 29, 2017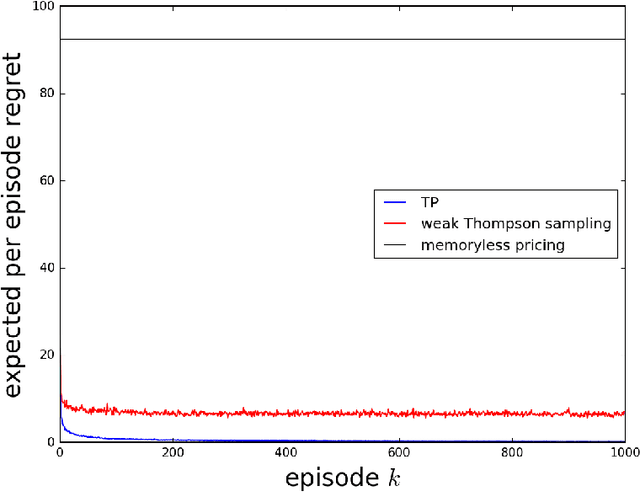
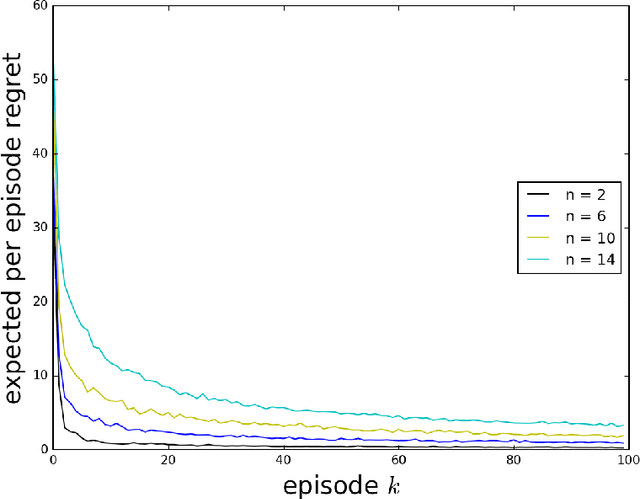
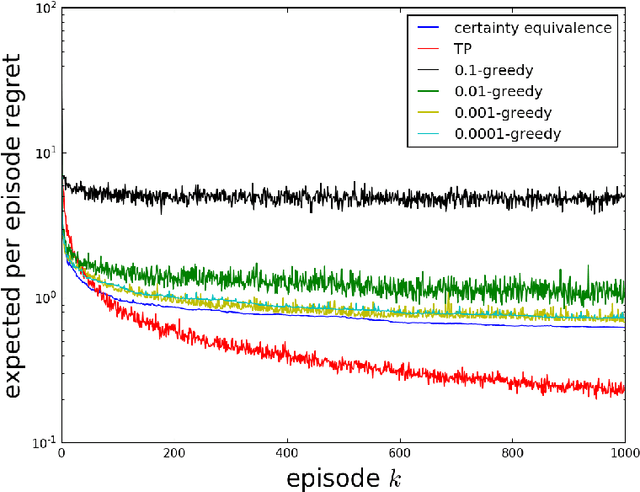
As a firm varies the price of a product, consumers exhibit reference effects, making purchase decisions based not only on the prevailing price but also the product's price history. We consider the problem of learning such behavioral patterns as a monopolist releases, markets, and prices products. This context calls for pricing decisions that intelligently trade off between maximizing revenue generated by a current product and probing to gain information for future benefit. Due to dependence on price history, realized demand can reflect delayed consequences of earlier pricing decisions. As such, inference entails attribution of outcomes to prior decisions and effective exploration requires planning price sequences that yield informative future outcomes. Despite the considerable complexity of this problem, we offer a tractable systematic approach. In particular, we frame the problem as one of reinforcement learning and leverage Thompson sampling. We also establish a regret bound that provides graceful guarantees on how performance improves as data is gathered and how this depends on the complexity of the demand model. We illustrate merits of the approach through simulations.
Learning to Optimize via Information-Directed Sampling
Jul 07, 2017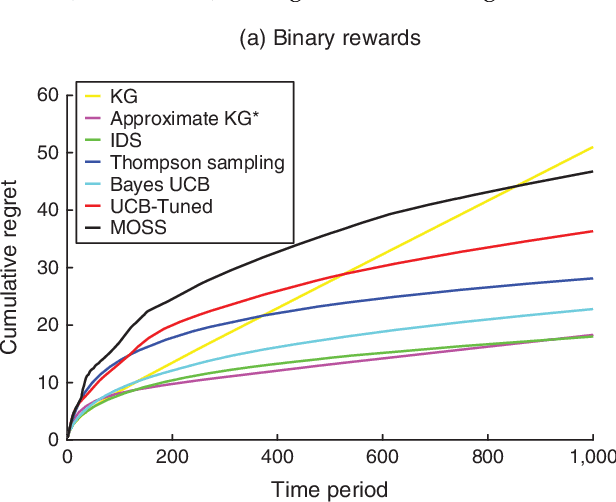
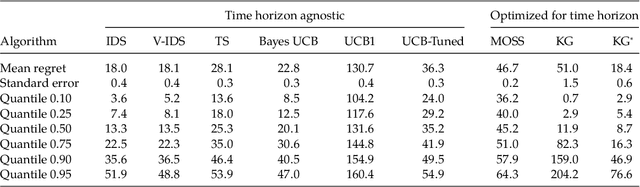
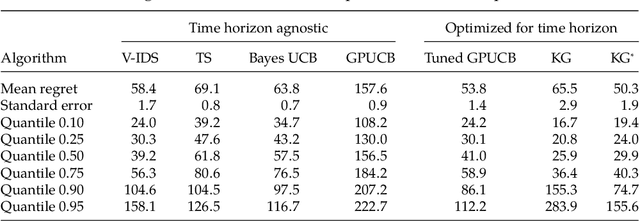

We propose information-directed sampling -- a new approach to online optimization problems in which a decision-maker must balance between exploration and exploitation while learning from partial feedback. Each action is sampled in a manner that minimizes the ratio between squared expected single-period regret and a measure of information gain: the mutual information between the optimal action and the next observation. We establish an expected regret bound for information-directed sampling that applies across a very general class of models and scales with the entropy of the optimal action distribution. We illustrate through simple analytic examples how information-directed sampling accounts for kinds of information that alternative approaches do not adequately address and that this can lead to dramatic performance gains. For the widely studied Bernoulli, Gaussian, and linear bandit problems, we demonstrate state-of-the-art simulation performance.
On Optimistic versus Randomized Exploration in Reinforcement Learning
Jun 13, 2017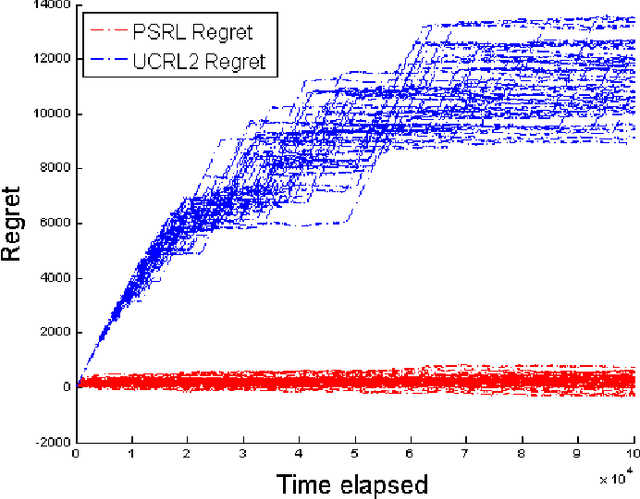


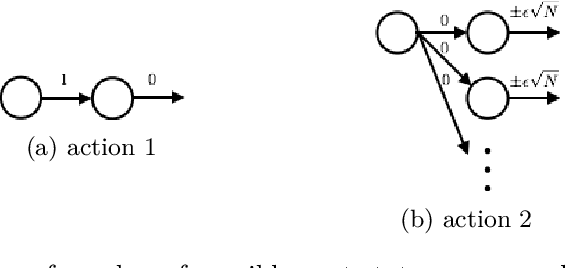
We discuss the relative merits of optimistic and randomized approaches to exploration in reinforcement learning. Optimistic approaches presented in the literature apply an optimistic boost to the value estimate at each state-action pair and select actions that are greedy with respect to the resulting optimistic value function. Randomized approaches sample from among statistically plausible value functions and select actions that are greedy with respect to the random sample. Prior computational experience suggests that randomized approaches can lead to far more statistically efficient learning. We present two simple analytic examples that elucidate why this is the case. In principle, there should be optimistic approaches that fare well relative to randomized approaches, but that would require intractable computation. Optimistic approaches that have been proposed in the literature sacrifice statistical efficiency for the sake of computational efficiency. Randomized approaches, on the other hand, may enable simultaneous statistical and computational efficiency.
Why is Posterior Sampling Better than Optimism for Reinforcement Learning?
Jun 13, 2017
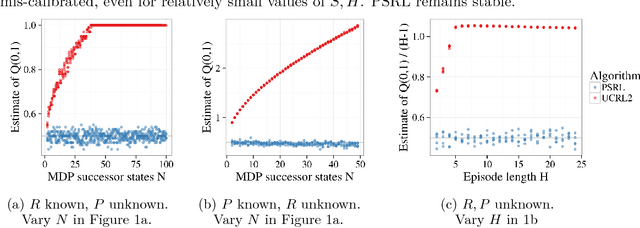
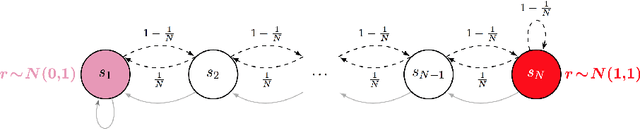
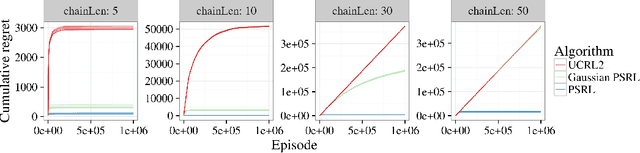
Computational results demonstrate that posterior sampling for reinforcement learning (PSRL) dramatically outperforms algorithms driven by optimism, such as UCRL2. We provide insight into the extent of this performance boost and the phenomenon that drives it. We leverage this insight to establish an $\tilde{O}(H\sqrt{SAT})$ Bayesian expected regret bound for PSRL in finite-horizon episodic Markov decision processes, where $H$ is the horizon, $S$ is the number of states, $A$ is the number of actions and $T$ is the time elapsed. This improves upon the best previous bound of $\tilde{O}(H S \sqrt{AT})$ for any reinforcement learning algorithm.
Time-Sensitive Bandit Learning and Satisficing Thompson Sampling
Apr 28, 2017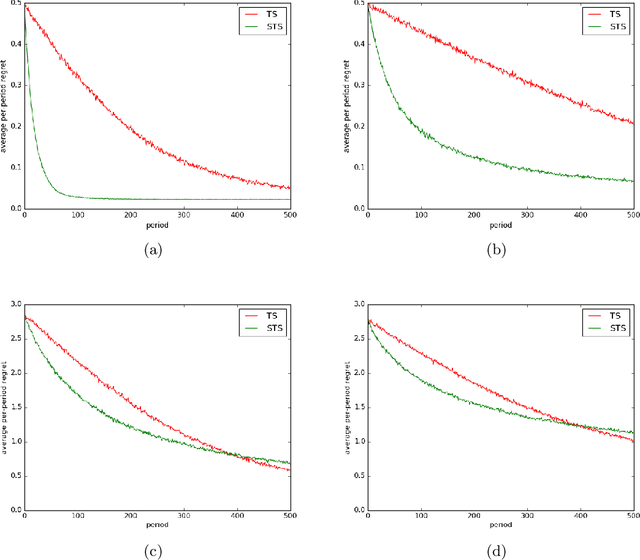
The literature on bandit learning and regret analysis has focused on contexts where the goal is to converge on an optimal action in a manner that limits exploration costs. One shortcoming imposed by this orientation is that it does not treat time preference in a coherent manner. Time preference plays an important role when the optimal action is costly to learn relative to near-optimal actions. This limitation has not only restricted the relevance of theoretical results but has also influenced the design of algorithms. Indeed, popular approaches such as Thompson sampling and UCB can fare poorly in such situations. In this paper, we consider discounted rather than cumulative regret, where a discount factor encodes time preference. We propose satisficing Thompson sampling -- a variation of Thompson sampling -- and establish a strong discounted regret bound for this new algorithm.
Conservative Contextual Linear Bandits
Mar 04, 2017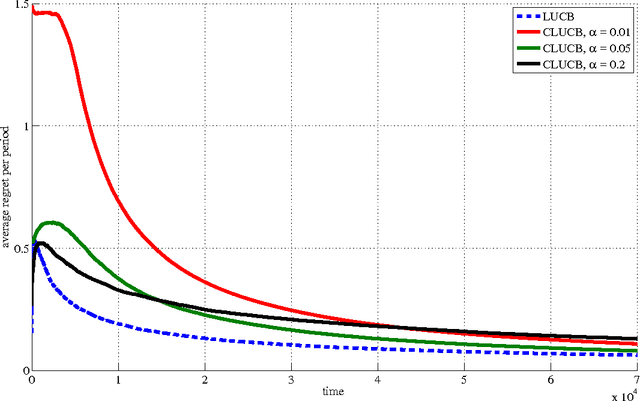
Safety is a desirable property that can immensely increase the applicability of learning algorithms in real-world decision-making problems. It is much easier for a company to deploy an algorithm that is safe, i.e., guaranteed to perform at least as well as a baseline. In this paper, we study the issue of safety in contextual linear bandits that have application in many different fields including personalized ad recommendation in online marketing. We formulate a notion of safety for this class of algorithms. We develop a safe contextual linear bandit algorithm, called conservative linear UCB (CLUCB), that simultaneously minimizes its regret and satisfies the safety constraint, i.e., maintains its performance above a fixed percentage of the performance of a baseline strategy, uniformly over time. We prove an upper-bound on the regret of CLUCB and show that it can be decomposed into two terms: 1) an upper-bound for the regret of the standard linear UCB algorithm that grows with the time horizon and 2) a constant (does not grow with the time horizon) term that accounts for the loss of being conservative in order to satisfy the safety constraint. We empirically show that our algorithm is safe and validate our theoretical analysis.