 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Multimodal Multi-Instance Learning for Aortic Stenosis Diagnosis
Mar 09, 2024



Automated interpretation of ultrasound imaging of the heart (echocardiograms) could improve the detection and treatment of aortic stenosis (AS), a deadly heart disease. However, existing deep learning pipelines for assessing AS from echocardiograms have two key limitations. First, most methods rely on limited 2D cineloops, thereby ignoring widely available Doppler imaging that contains important complementary information about pressure gradients and blood flow abnormalities associated with AS. Second, obtaining labeled data is difficult. There are often far more unlabeled echocardiogram recordings available, but these remain underutilized by existing methods. To overcome these limitations, we introduce Semi-supervised Multimodal Multiple-Instance Learning (SMMIL), a new deep learning framework for automatic interpretation for structural heart diseases like AS. When deployed, SMMIL can combine information from two input modalities, spectral Dopplers and 2D cineloops, to produce a study-level AS diagnosis. During training, SMMIL can combine a smaller labeled set and an abundant unlabeled set of both modalities to improve its classifier. Experiments demonstrate that SMMIL outperforms recent alternatives at 3-level AS severity classification as well as several clinically relevant AS detection tasks.
Detecting Heart Disease from Multi-View Ultrasound Images via Supervised Attention Multiple Instance Learning
May 25, 2023Aortic stenosis (AS) is a degenerative valve condition that causes substantial morbidity and mortality. This condition is under-diagnosed and under-treated. In clinical practice, AS is diagnosed with expert review of transthoracic echocardiography, which produces dozens of ultrasound images of the heart. Only some of these views show the aortic valve. To automate screening for AS, deep networks must learn to mimic a human expert's ability to identify views of the aortic valve then aggregate across these relevant images to produce a study-level diagnosis. We find previous approaches to AS detection yield insufficient accuracy due to relying on inflexible averages across images. We further find that off-the-shelf attention-based multiple instance learning (MIL) performs poorly. We contribute a new end-to-end MIL approach with two key methodological innovations. First, a supervised attention technique guides the learned attention mechanism to favor relevant views. Second, a novel self-supervised pretraining strategy applies contrastive learning on the representation of the whole study instead of individual images as commonly done in prior literature. Experiments on an open-access dataset and an external validation set show that our approach yields higher accuracy while reducing model size.
Fix-A-Step: Effective Semi-supervised Learning from Uncurated Unlabeled Sets
Aug 25, 2022
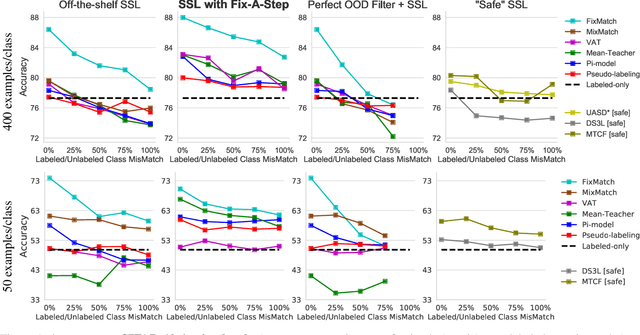
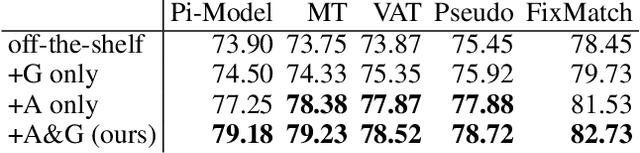
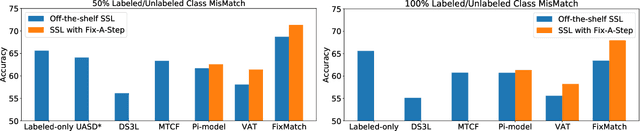
Semi-supervised learning (SSL) promises gains in accuracy compared to training classifiers on small labeled datasets by also training on many unlabeled images. In realistic applications like medical imaging, unlabeled sets will be collected for expediency and thus uncurated: possibly different from the labeled set in represented classes or class frequencies. Unfortunately, modern deep SSL often makes accuracy worse when given uncurated unlabeled sets. Recent remedies suggest filtering approaches that detect out-of-distribution unlabeled examples and then discard or downweight them. Instead, we view all unlabeled examples as potentially helpful. We introduce a procedure called Fix-A-Step that can improve heldout accuracy of common deep SSL methods despite lack of curation. The key innovations are augmentations of the labeled set inspired by all unlabeled data and a modification of gradient descent updates to prevent following the multi-task SSL loss from hurting labeled-set accuracy. Though our method is simpler than alternatives, we show consistent accuracy gains on CIFAR-10 and CIFAR-100 benchmarks across all tested levels of artificial contamination for the unlabeled sets. We further suggest a real medical benchmark for SSL: recognizing the view type of ultrasound images of the heart. Our method can learn from 353,500 truly uncurated unlabeled images to deliver gains that generalize across hospitals.