 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy Transformer
Feb 14, 2023



Transformers have become the de facto models of choice in machine learning, typically leading to impressive performance on many applications. At the same time, the architectural development in the transformer world is mostly driven by empirical findings, and the theoretical understanding of their architectural building blocks is rather limited. In contrast, Dense Associative Memory models or Modern Hopfield Networks have a well-established theoretical foundation, but have not yet demonstrated truly impressive practical results. We propose a transformer architecture that replaces the sequence of feedforward transformer blocks with a single large Associative Memory model. Our novel architecture, called Energy Transformer (or ET for short), has many of the familiar architectural primitives that are often used in the current generation of transformers. However, it is not identical to the existing architectures. The sequence of transformer layers in ET is purposely designed to minimize a specifically engineered energy function, which is responsible for representing the relationships between the tokens. As a consequence of this computational principle, the attention in ET is different from the conventional attention mechanism. In this work, we introduce the theoretical foundations of ET, explore it's empirical capabilities using the image completion task, and obtain strong quantitative results on the graph anomaly detection task.
DiffusionDB: A Large-scale Prompt Gallery Dataset for Text-to-Image Generative Models
Nov 15, 2022With recent advancements in diffusion models, users can generate high-quality images by writing text prompts in natural language. However, generating images with desired details requires proper prompts, and it is often unclear how a model reacts to different prompts and what the best prompts are. To help researchers tackle these critical challenges, we introduce DiffusionDB, the first large-scale text-to-image prompt dataset. DiffusionDB contains 14 million images generated by Stable Diffusion using prompts and hyperparameters specified by real users. We analyze prompts in the dataset and discuss key properties of these prompts. The unprecedented scale and diversity of this human-actuated dataset provide exciting research opportunities in understanding the interplay between prompts and generative models, detecting deepfakes, and designing human-AI interaction tools to help users more easily use these models. DiffusionDB is publicly available at: https://poloclub.github.io/diffusiondb.
Interactive and Visual Prompt Engineering for Ad-hoc Task Adaptation with Large Language Models
Aug 16, 2022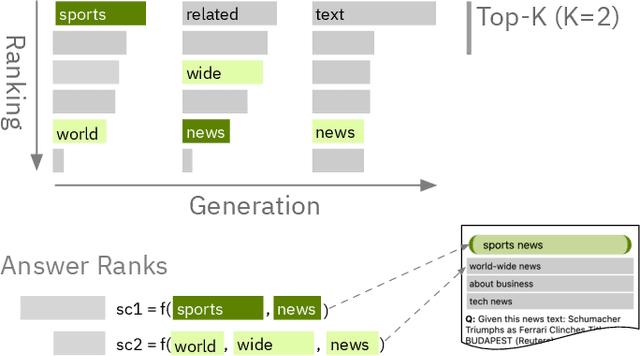
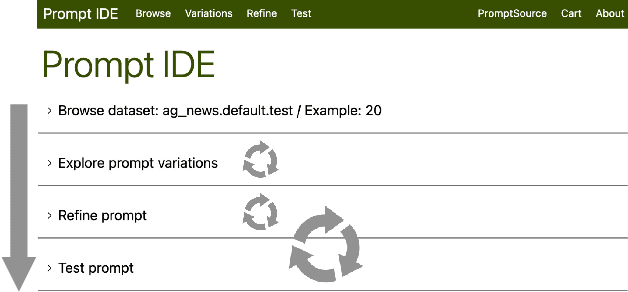

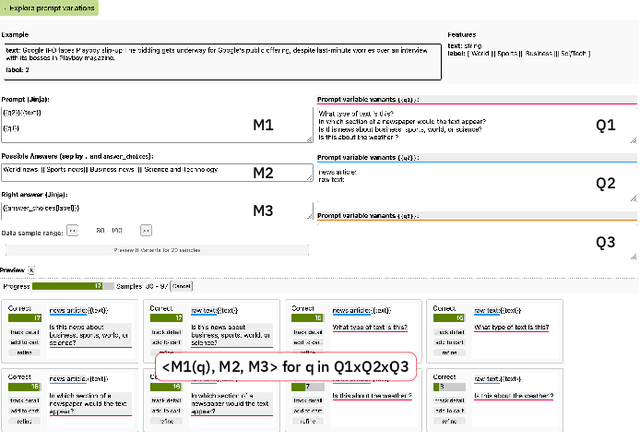
State-of-the-art neural language models can now be used to solve ad-hoc language tasks through zero-shot prompting without the need for supervised training. This approach has gained popularity in recent years, and researchers have demonstrated prompts that achieve strong accuracy on specific NLP tasks. However, finding a prompt for new tasks requires experimentation. Different prompt templates with different wording choices lead to significant accuracy differences. PromptIDE allows users to experiment with prompt variations, visualize prompt performance, and iteratively optimize prompts. We developed a workflow that allows users to first focus on model feedback using small data before moving on to a large data regime that allows empirical grounding of promising prompts using quantitative measures of the task. The tool then allows easy deployment of the newly created ad-hoc models. We demonstrate the utility of PromptIDE (demo at http://prompt.vizhub.ai) and our workflow using several real-world use cases.
ConceptEvo: Interpreting Concept Evolution in Deep Learning Training
Mar 30, 2022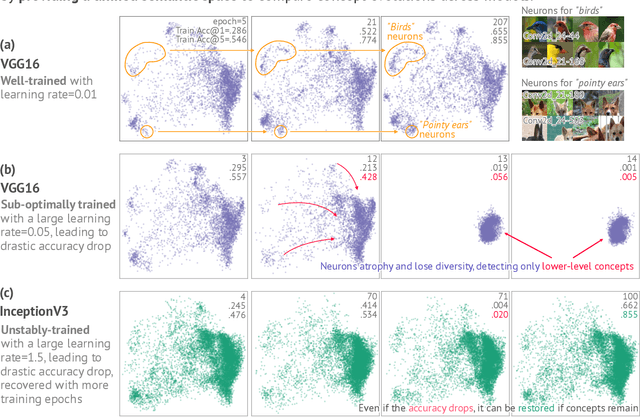


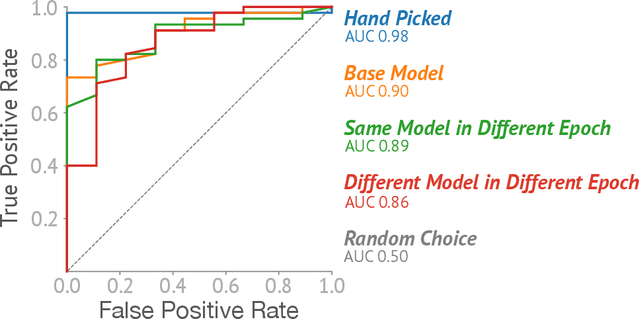
Deep neural networks (DNNs) have been widely used for decision making, prompting a surge of interest in interpreting how these complex models work. Recent literature on DNN interpretation has revolved around already-trained models; however, much less research focuses on interpreting how the models evolve as they are trained. Interpreting model evolution is crucial to monitor network training and can aid proactive decisions about necessary interventions. In this work, we present ConceptEvo, a general interpretation framework for DNNs that reveals the inception and evolution of detected concepts during training. Through a large-scale human evaluation with 260 participants and quantitative experiments, we show that ConceptEvo discovers evolution across different models that are meaningful to humans, helpful for early-training intervention decisions, and crucial to the prediction for a given class.
LMdiff: A Visual Diff Tool to Compare Language Models
Nov 02, 2021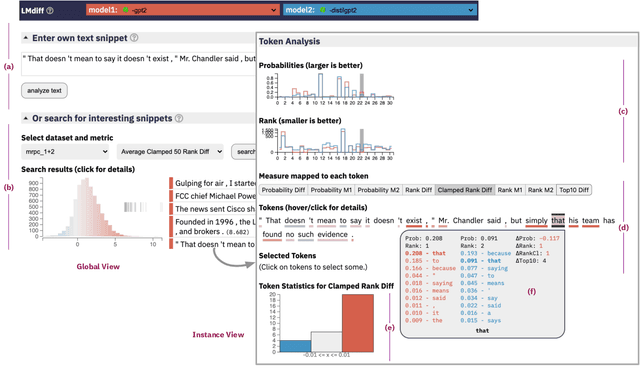
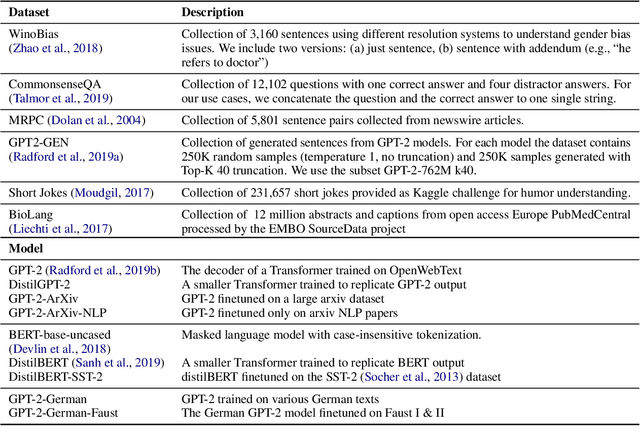
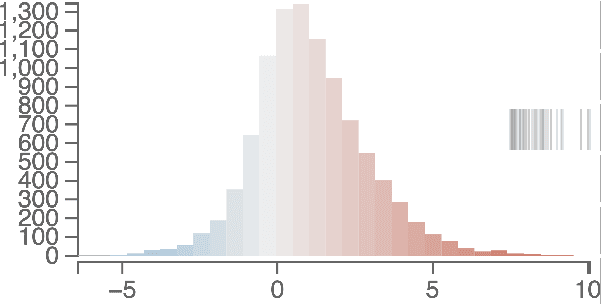

While different language models are ubiquitous in NLP, it is hard to contrast their outputs and identify which contexts one can handle better than the other. To address this question, we introduce LMdiff, a tool that visually compares probability distributions of two models that differ, e.g., through finetuning, distillation, or simply training with different parameter sizes. LMdiff allows the generation of hypotheses about model behavior by investigating text instances token by token and further assists in choosing these interesting text instances by identifying the most interesting phrases from large corpora. We showcase the applicability of LMdiff for hypothesis generation across multiple case studies. A demo is available at http://lmdiff.net .
Shared Interest: Large-Scale Visual Analysis of Model Behavior by Measuring Human-AI Alignment
Jul 20, 2021
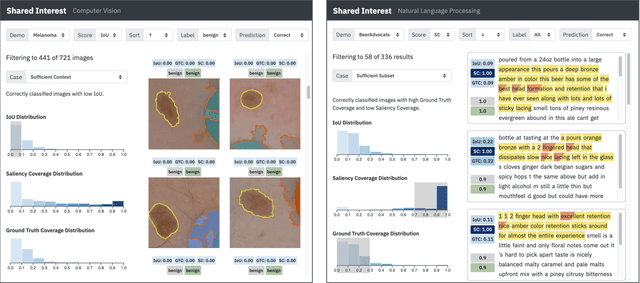

Saliency methods -- techniques to identify the importance of input features on a model's output -- are a common first step in understanding neural network behavior. However, interpreting saliency requires tedious manual inspection to identify and aggregate patterns in model behavior, resulting in ad hoc or cherry-picked analysis. To address these concerns, we present Shared Interest: a set of metrics for comparing saliency with human annotated ground truths. By providing quantitative descriptors, Shared Interest allows ranking, sorting, and aggregation of inputs thereby facilitating large-scale systematic analysis of model behavior. We use Shared Interest to identify eight recurring patterns in model behavior including focusing on a sufficient subset of ground truth features or being distracted by contextual features. Working with representative real-world users, we show how Shared Interest can be used to rapidly develop or lose trust in a model's reliability, uncover issues that are missed in manual analyses, and enable interactive probing of model behavior.
FairyTailor: A Multimodal Generative Framework for Storytelling
Jul 13, 2021
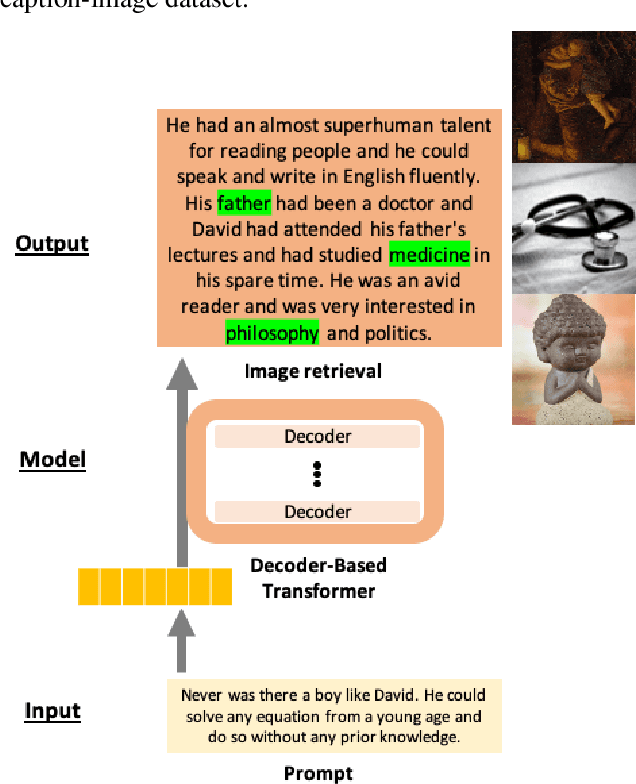
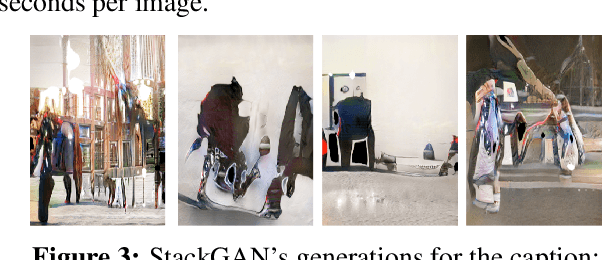

Storytelling is an open-ended task that entails creative thinking and requires a constant flow of ideas. Natural language generation (NLG) for storytelling is especially challenging because it requires the generated text to follow an overall theme while remaining creative and diverse to engage the reader. In this work, we introduce a system and a web-based demo, FairyTailor, for human-in-the-loop visual story co-creation. Users can create a cohesive children's fairytale by weaving generated texts and retrieved images with their input. FairyTailor adds another modality and modifies the text generation process to produce a coherent and creative sequence of text and images. To our knowledge, this is the first dynamic tool for multimodal story generation that allows interactive co-formation of both texts and images. It allows users to give feedback on co-created stories and share their results.
Can a Fruit Fly Learn Word Embeddings?
Jan 18, 2021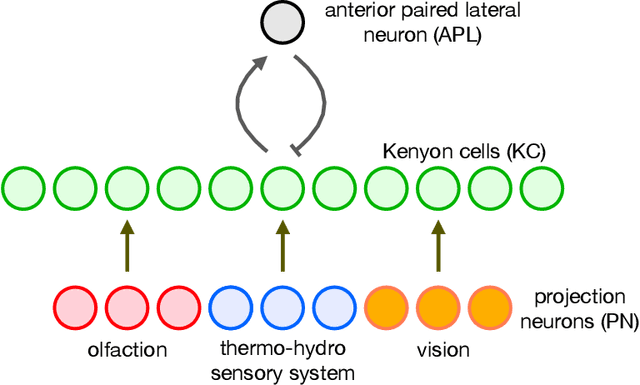
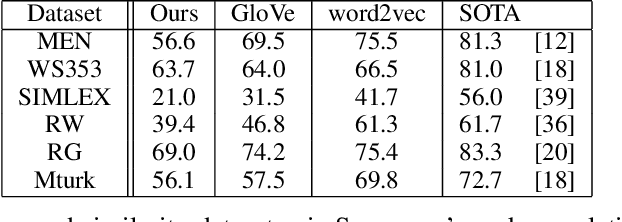
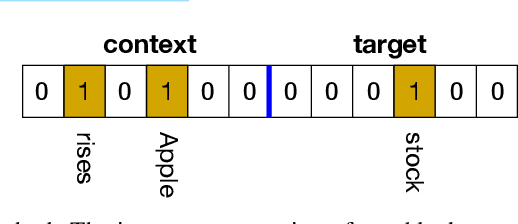

The mushroom body of the fruit fly brain is one of the best studied systems in neuroscience. At its core it consists of a population of Kenyon cells, which receive inputs from multiple sensory modalities. These cells are inhibited by the anterior paired lateral neuron, thus creating a sparse high dimensional representation of the inputs. In this work we study a mathematical formalization of this network motif and apply it to learning the correlational structure between words and their context in a corpus of unstructured text, a common natural language processing (NLP) task. We show that this network can learn semantic representations of words and can generate both static and context-dependent word embeddings. Unlike conventional methods (e.g., BERT, GloVe) that use dense representations for word embedding, our algorithm encodes semantic meaning of words and their context in the form of sparse binary hash codes. The quality of the learned representations is evaluated on word similarity analysis, word-sense disambiguation, and document classification. It is shown that not only can the fruit fly network motif achieve performance comparable to existing methods in NLP, but, additionally, it uses only a fraction of the computational resources (shorter training time and smaller memory footprint).
exBERT: A Visual Analysis Tool to Explore Learned Representations in Transformers Models
Oct 11, 2019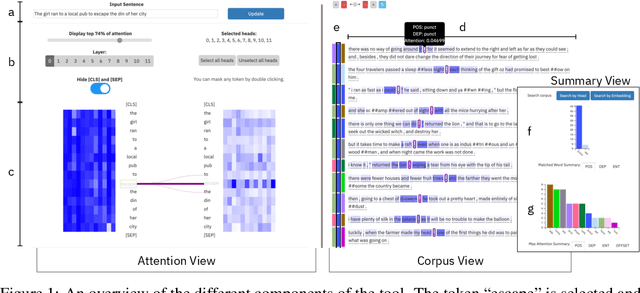
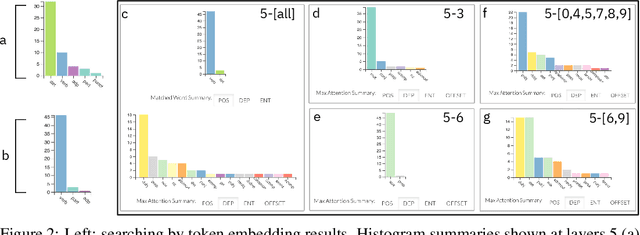
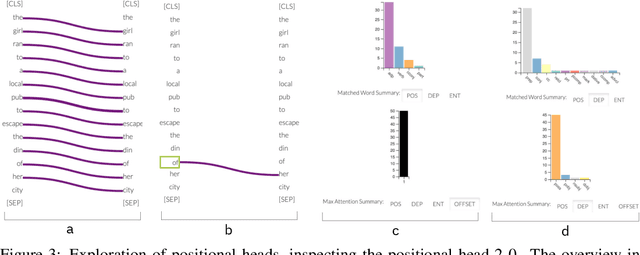
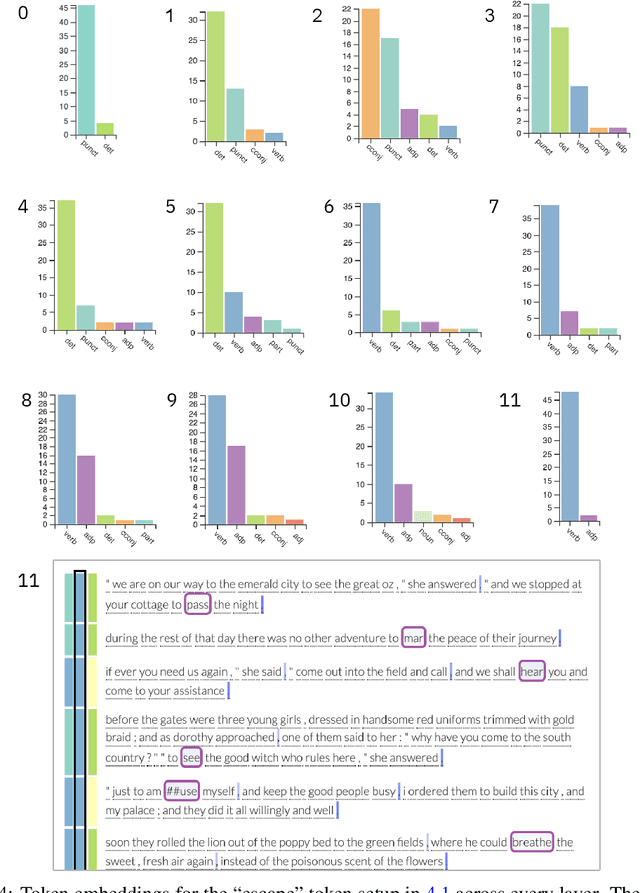
Large language models can produce powerful contextual representations that lead to improvements across many NLP tasks. Since these models are typically guided by a sequence of learned self attention mechanisms and may comprise undesired inductive biases, it is paramount to be able to explore what the attention has learned. While static analyses of these models lead to targeted insights, interactive tools are more dynamic and can help humans better gain an intuition for the model-internal reasoning process. We present exBERT, an interactive tool named after the popular BERT language model, that provides insights into the meaning of the contextual representations by matching a human-specified input to similar contexts in a large annotated dataset. By aggregating the annotations of the matching similar contexts, exBERT helps intuitively explain what each attention-head has learned.