 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMONET: A Massive, Open, Non-redundant and Enriched Text-to-image dataset
May 20, 2026Training large text-to-image models requires high-quality, curated datasets with diverse content and detailed captions. Yet the cost and complexity of collecting, filtering, deduplicating, and re-captioning such corpora at scale hinders open and reproducible research in the field. We introduce MONET, an open Apache 2.0 dataset of approx. 104.9M image--text pairs collected from 2.9B raw pairs across heterogeneous open sources through successive stages of safety filtering, domain-based filtering, exact and near-duplicate removal, and re-captioning with multiple vision-language models covering short to long-form descriptions, and further augmented with synthetically generated samples. Each image is shipped with pre-computed embeddings and annotations to accelerate downstream use. To validate the effectiveness of MONET, we train a 4B-parameter latent diffusion model exclusively on it and reach competitive GenEval and DPG scores, demonstrating that our dataset lowers the barrier to large-scale, reproducible text-to-image research.
Fast, faithful and photorealistic diffusion-based image super-resolution with enhanced Flow Map models
Jan 23, 2026Diffusion-based image super-resolution (SR) has recently attracted significant attention by leveraging the expressive power of large pre-trained text-to-image diffusion models (DMs). A central practical challenge is resolving the trade-off between reconstruction faithfulness and photorealism. To address inference efficiency, many recent works have explored knowledge distillation strategies specifically tailored to SR, enabling one-step diffusion-based approaches. However, these teacher-student formulations are inherently constrained by information compression, which can degrade perceptual cues such as lifelike textures and depth of field, even with high overall perceptual quality. In parallel, self-distillation DMs, known as Flow Map models, have emerged as a promising alternative for image generation tasks, enabling fast inference while preserving the expressivity and training stability of standard DMs. Building on these developments, we propose FlowMapSR, a novel diffusion-based framework for image super-resolution explicitly designed for efficient inference. Beyond adapting Flow Map models to SR, we introduce two complementary enhancements: (i) positive-negative prompting guidance, based on a generalization of classifier free-guidance paradigm to Flow Map models, and (ii) adversarial fine-tuning using Low-Rank Adaptation (LoRA). Among the considered Flow Map formulations (Eulerian, Lagrangian, and Shortcut), we find that the Shortcut variant consistently achieves the best performance when combined with these enhancements. Extensive experiments show that FlowMapSR achieves a better balance between reconstruction faithfulness and photorealism than recent state-of-the-art methods for both x4 and x8 upscaling, while maintaining competitive inference time. Notably, a single model is used for both upscaling factors, without any scale-specific conditioning or degradation-guided mechanisms.
LBM: Latent Bridge Matching for Fast Image-to-Image Translation
Mar 10, 2025In this paper, we introduce Latent Bridge Matching (LBM), a new, versatile and scalable method that relies on Bridge Matching in a latent space to achieve fast image-to-image translation. We show that the method can reach state-of-the-art results for various image-to-image tasks using only a single inference step. In addition to its efficiency, we also demonstrate the versatility of the method across different image translation tasks such as object removal, normal and depth estimation, and object relighting. We also derive a conditional framework of LBM and demonstrate its effectiveness by tackling the tasks of controllable image relighting and shadow generation. We provide an open-source implementation of the method at https://github.com/gojasper/LBM.
Controllable Shadow Generation with Single-Step Diffusion Models from Synthetic Data
Dec 16, 2024



Realistic shadow generation is a critical component for high-quality image compositing and visual effects, yet existing methods suffer from certain limitations: Physics-based approaches require a 3D scene geometry, which is often unavailable, while learning-based techniques struggle with control and visual artifacts. We introduce a novel method for fast, controllable, and background-free shadow generation for 2D object images. We create a large synthetic dataset using a 3D rendering engine to train a diffusion model for controllable shadow generation, generating shadow maps for diverse light source parameters. Through extensive ablation studies, we find that rectified flow objective achieves high-quality results with just a single sampling step enabling real-time applications. Furthermore, our experiments demonstrate that the model generalizes well to real-world images. To facilitate further research in evaluating quality and controllability in shadow generation, we release a new public benchmark containing a diverse set of object images and shadow maps in various settings. The project page is available at https://gojasper.github.io/controllable-shadow-generation-project/
Flash Diffusion: Accelerating Any Conditional Diffusion Model for Few Steps Image Generation
Jun 04, 2024In this paper, we propose an efficient, fast, and versatile distillation method to accelerate the generation of pre-trained diffusion models: Flash Diffusion. The method reaches state-of-the-art performances in terms of FID and CLIP-Score for few steps image generation on the COCO2014 and COCO2017 datasets, while requiring only several GPU hours of training and fewer trainable parameters than existing methods. In addition to its efficiency, the versatility of the method is also exposed across several tasks such as text-to-image, inpainting, face-swapping, super-resolution and using different backbones such as UNet-based denoisers (SD1.5, SDXL) or DiT (Pixart-$\alpha$), as well as adapters. In all cases, the method allowed to reduce drastically the number of sampling steps while maintaining very high-quality image generation. The official implementation is available at https://github.com/gojasper/flash-diffusion.
Mean-field methods and algorithmic perspectives for high-dimensional machine learning
Mar 10, 2021The main difficulty that arises in the analysis of most machine learning algorithms is to handle, analytically and numerically, a large number of interacting random variables. In this Ph.D manuscript, we revisit an approach based on the tools of statistical physics of disordered systems. Developed through a rich literature, they have been precisely designed to infer the macroscopic behavior of a large number of particles from their microscopic interactions. At the heart of this work, we strongly capitalize on the deep connection between the replica method and message passing algorithms in order to shed light on the phase diagrams of various theoretical models, with an emphasis on the potential differences between statistical and algorithmic thresholds. We essentially focus on synthetic tasks and data generated in the teacher-student paradigm. In particular, we apply these mean-field methods to the Bayes-optimal analysis of committee machines, to the worst-case analysis of Rademacher generalization bounds for perceptrons, and to empirical risk minimization in the context of generalized linear models. Finally, we develop a framework to analyze estimation models with structured prior informations, produced for instance by deep neural networks based generative models with random weights.
Linear unit-tests for invariance discovery
Feb 22, 2021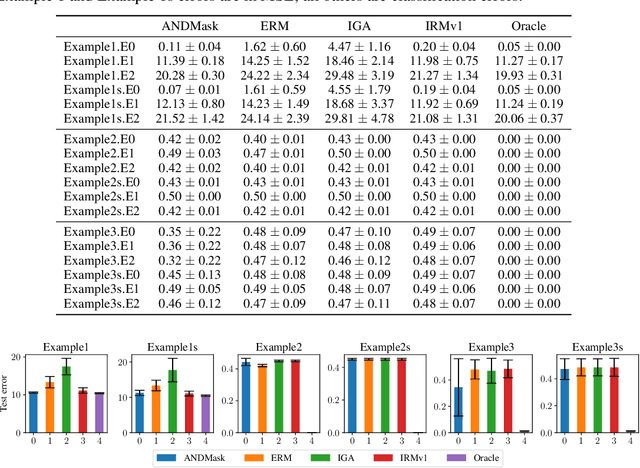
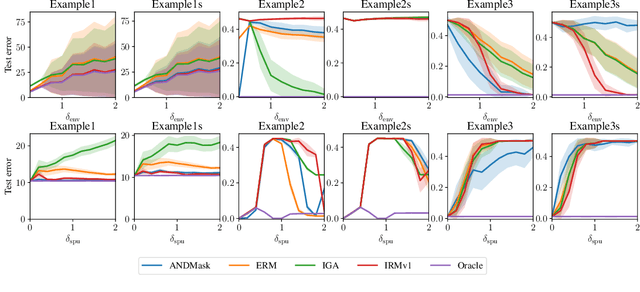
There is an increasing interest in algorithms to learn invariant correlations across training environments. A big share of the current proposals find theoretical support in the causality literature but, how useful are they in practice? The purpose of this note is to propose six linear low-dimensional problems -- unit tests -- to evaluate different types of out-of-distribution generalization in a precise manner. Following initial experiments, none of the three recently proposed alternatives passes all tests. By providing the code to automatically replicate all the results in this manuscript (https://www.github.com/facebookresearch/InvarianceUnitTests), we hope that our unit tests become a standard steppingstone for researchers in out-of-distribution generalization.
Generalization error in high-dimensional perceptrons: Approaching Bayes error with convex optimization
Jun 11, 2020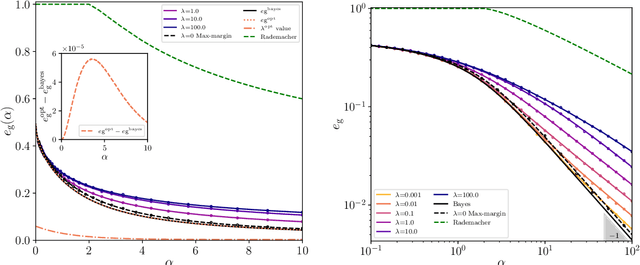
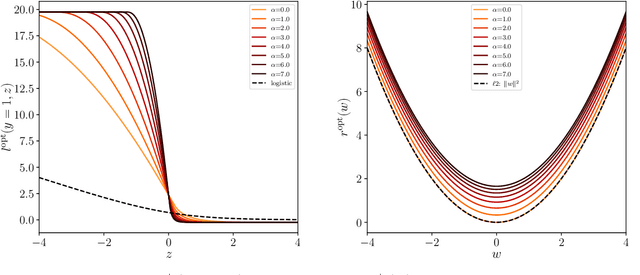
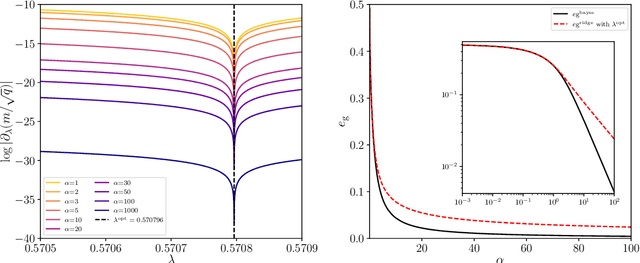
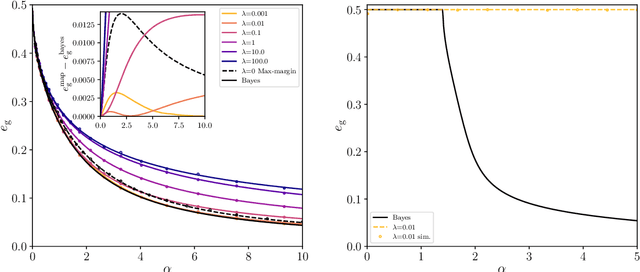
We consider a commonly studied supervised classification of a synthetic dataset whose labels are generated by feeding a one-layer neural network with random iid inputs. We study the generalization performances of standard classifiers in the high-dimensional regime where $\alpha=n/d$ is kept finite in the limit of a high dimension $d$ and number of samples $n$. Our contribution is three-fold: First, we prove a formula for the generalization error achieved by $\ell_2$ regularized classifiers that minimize a convex loss. This formula was first obtained by the heuristic replica method of statistical physics. Secondly, focussing on commonly used loss functions and optimizing the $\ell_2$ regularization strength, we observe that while ridge regression performance is poor, logistic and hinge regression are surprisingly able to approach the Bayes-optimal generalization error extremely closely. As $\alpha \to \infty$ they lead to Bayes-optimal rates, a fact that does not follow from predictions of margin-based generalization error bounds. Third, we design an optimal loss and regularizer that provably leads to Bayes-optimal generalization error.
TRAMP: Compositional Inference with TRee Approximate Message Passing
Apr 03, 2020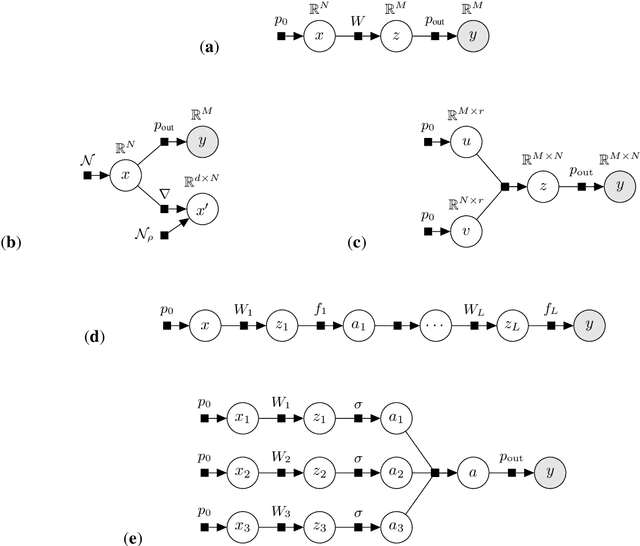
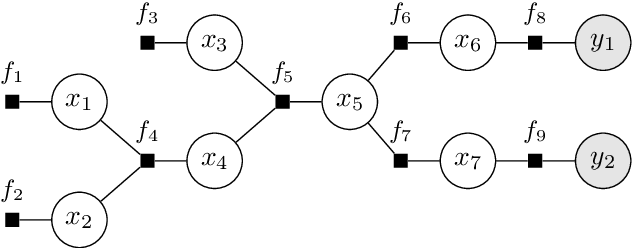
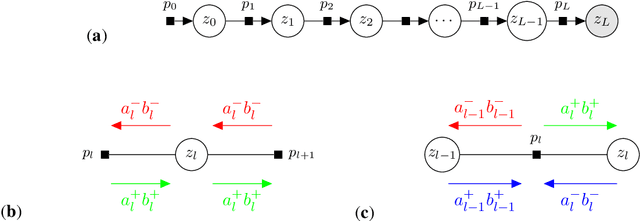
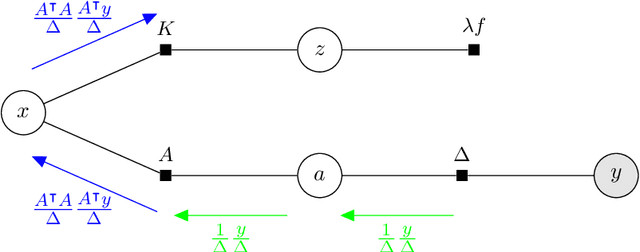
We introduce tramp, standing for TRee Approximate Message Passing, a python package for compositional inference in high-dimensional tree-structured models. The package provides an unifying framework to study several approximate message passing algorithms previously derived for a variety of machine learning tasks such as generalized linear models, inference in multi-layer networks, matrix factorization, and reconstruction using non-separable penalties. For some models, the asymptotic performance of the algorithm can be theoretically predicted by the state evolution, and the measurements entropy estimated by the free entropy formalism. The implementation is modular by design: each module, which implements a factor, can be composed at will with other modules to solve complex inference tasks. The user only needs to declare the factor graph of the model: the inference algorithm, state evolution and entropy estimation are fully automated.
Rademacher complexity and spin glasses: A link between the replica and statistical theories of learning
Dec 05, 2019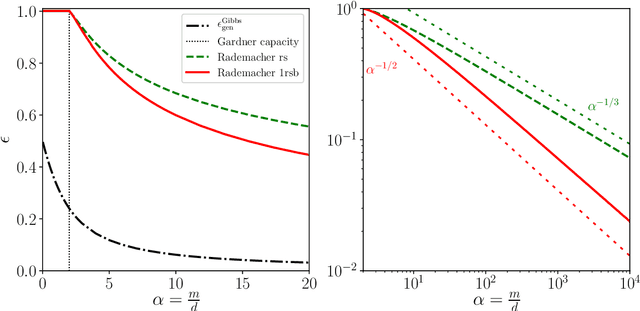
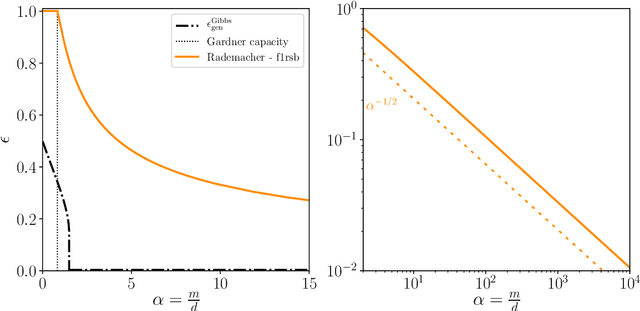
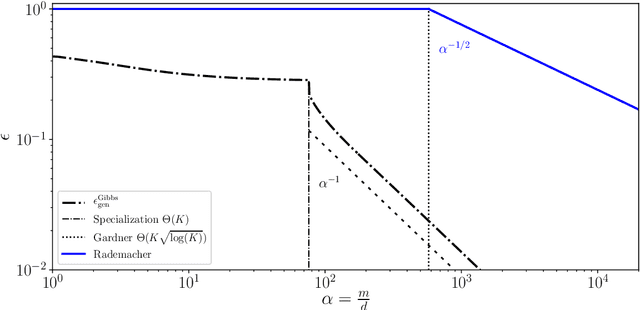
Statistical learning theory provides bounds of the generalization gap, using in particular the Vapnik-Chervonenkis dimension and the Rademacher complexity. An alternative approach, mainly studied in the statistical physics literature, is the study of generalization in simple synthetic-data models. Here we discuss the connections between these approaches and focus on the link between the Rademacher complexity in statistical learning and the theories of generalization for typical-case synthetic models from statistical physics, involving quantities known as Gardner capacity and ground state energy. We show that in these models the Rademacher complexity is closely related to the ground state energy computed by replica theories. Using this connection, one may reinterpret many results of the literature as rigorous Rademacher bounds in a variety of models in the high-dimensional statistics limit. Somewhat surprisingly, we also show that statistical learning theory provides predictions for the behavior of the ground-state energies in some full replica symmetry breaking models.