 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing values about gendered language reform in LLMs' revisions
May 27, 2025



Within the common LLM use case of text revision, we study LLMs' revision of gendered role nouns (e.g., outdoorsperson/woman/man) and their justifications of such revisions. We evaluate their alignment with feminist and trans-inclusive language reforms for English. Drawing on insight from sociolinguistics, we further assess if LLMs are sensitive to the same contextual effects in the application of such reforms as people are, finding broad evidence of such effects. We discuss implications for value alignment.
Do language models practice what they preach? Examining language ideologies about gendered language reform encoded in LLMs
Sep 20, 2024



We study language ideologies in text produced by LLMs through a case study on English gendered language reform (related to role nouns like congressperson/-woman/-man, and singular they). First, we find political bias: when asked to use language that is "correct" or "natural", LLMs use language most similarly to when asked to align with conservative (vs. progressive) values. This shows how LLMs' metalinguistic preferences can implicitly communicate the language ideologies of a particular political group, even in seemingly non-political contexts. Second, we find LLMs exhibit internal inconsistency: LLMs use gender-neutral variants more often when more explicit metalinguistic context is provided. This shows how the language ideologies expressed in text produced by LLMs can vary, which may be unexpected to users. We discuss the broader implications of these findings for value alignment.
Say Anything: Automatic Semantic Infelicity Detection in L2 English Indefinite Pronouns
Sep 17, 2019
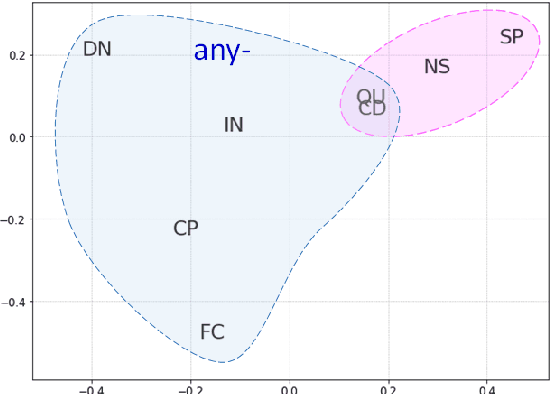

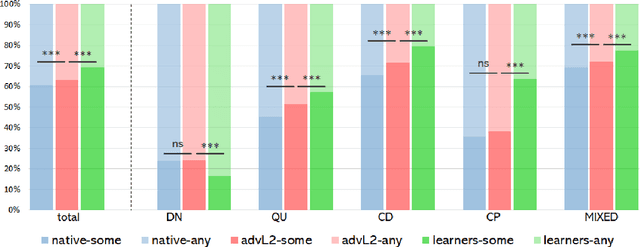
Computational research on error detection in second language speakers has mainly addressed clear grammatical anomalies typical to learners at the beginner-to-intermediate level. We focus instead on acquisition of subtle semantic nuances of English indefinite pronouns by non-native speakers at varying levels of proficiency. We first lay out theoretical, linguistically motivated hypotheses, and supporting empirical evidence on the nature of the challenges posed by indefinite pronouns to English learners. We then suggest and evaluate an automatic approach for detection of atypical usage patterns, demonstrating that deep learning architectures are promising for this task involving nuanced semantic anomalies.
Calculating Probabilities Simplifies Word Learning
Feb 22, 2017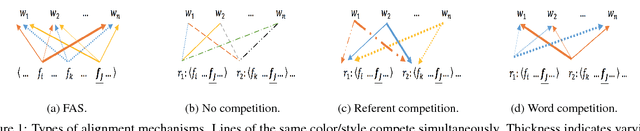
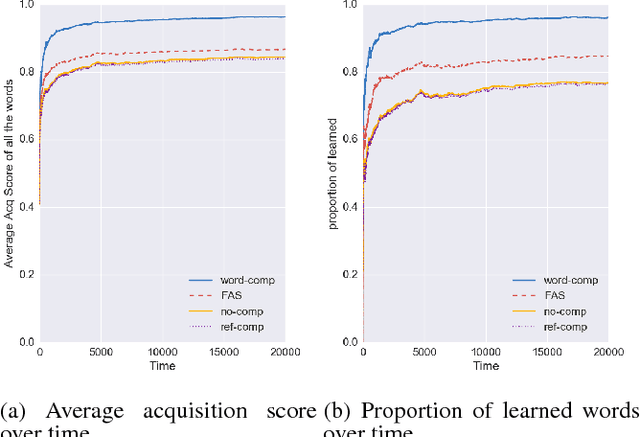

Children can use the statistical regularities of their environment to learn word meanings, a mechanism known as cross-situational learning. We take a computational approach to investigate how the information present during each observation in a cross-situational framework can affect the overall acquisition of word meanings. We do so by formulating various in-the-moment learning mechanisms that are sensitive to different statistics of the environment, such as counts and conditional probabilities. Each mechanism introduces a unique source of competition or mutual exclusivity bias to the model; the mechanism that maximally uses the model's knowledge of word meanings performs the best. Moreover, the gap between this mechanism and others is amplified in more challenging learning scenarios, such as learning from few examples.