 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdding New Tasks to a Single Network with Weight Transformations using Binary Masks
Jun 14, 2018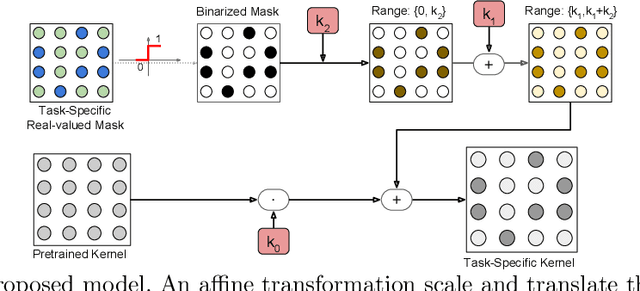
Visual recognition algorithms are required today to exhibit adaptive abilities. Given a deep model trained on a specific, given task, it would be highly desirable to be able to adapt incrementally to new tasks, preserving scalability as the number of new tasks increases, while at the same time avoiding catastrophic forgetting issues. Recent work has shown that masking the internal weights of a given original conv-net through learned binary variables is a promising strategy. We build upon this intuition and take into account more elaborated affine transformations of the convolutional weights that include learned binary masks. We show that with our generalization it is possible to achieve significantly higher levels of adaptation to new tasks, enabling the approach to compete with fine tuning strategies by requiring slightly more than 1 bit per network parameter per additional task. Experiments on two popular benchmarks showcase the power of our approach, that achieves the new state of the art on the Visual Decathlon Challenge.
Robust Place Categorization with Deep Domain Generalization
May 30, 2018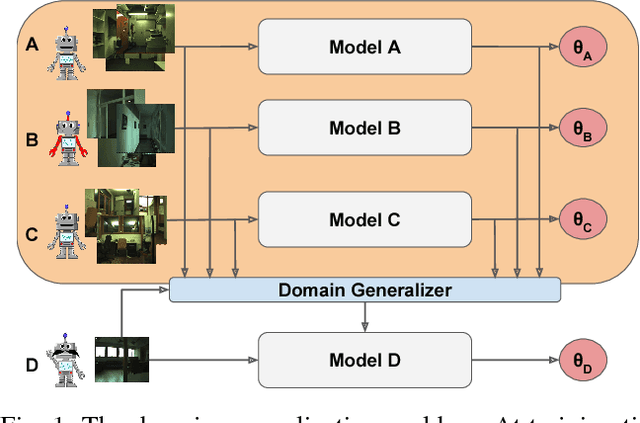
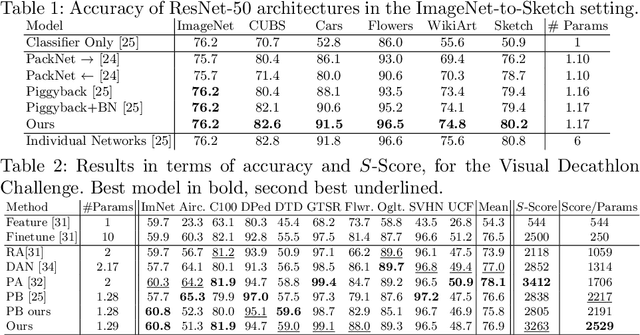
Traditional place categorization approaches in robot vision assume that training and test images have similar visual appearance. Therefore, any seasonal, illumination and environmental changes typically lead to severe degradation in performance. To cope with this problem, recent works have proposed to adopt domain adaptation techniques. While effective, these methods assume that some prior information about the scenario where the robot will operate is available at training time. Unfortunately, in many cases this assumption does not hold, as we often do not know where a robot will be deployed. To overcome this issue, in this paper we present an approach which aims at learning classification models able to generalize to unseen scenarios. Specifically, we propose a novel deep learning framework for domain generalization. Our method develops from the intuition that, given a set of different classification models associated to known domains (e.g. corresponding to multiple environments, robots), the best model for a new sample in the novel domain can be computed directly at test time by optimally combining the known models. To implement our idea, we exploit recent advances in deep domain adaptation and design a Convolutional Neural Network architecture with novel layers performing a weighted version of Batch Normalization. Our experiments, conducted on three common datasets for robot place categorization, confirm the validity of our contribution.
Recognizing Objects In-the-wild: Where Do We Stand?
May 22, 2018


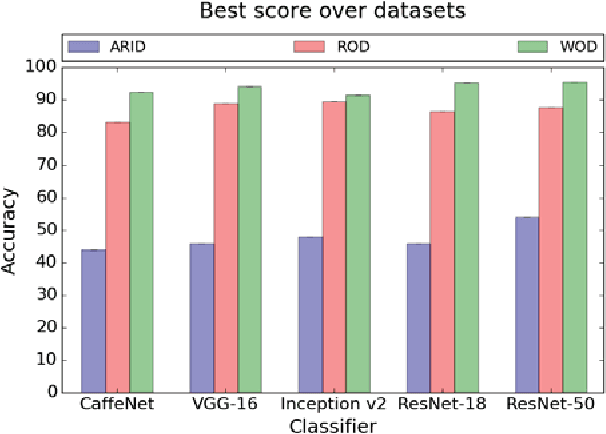
The ability to recognize objects is an essential skill for a robotic system acting in human-populated environments. Despite decades of effort from the robotic and vision research communities, robots are still missing good visual perceptual systems, preventing the use of autonomous agents for real-world applications. The progress is slowed down by the lack of a testbed able to accurately represent the world perceived by the robot in-the-wild. In order to fill this gap, we introduce a large-scale, multi-view object dataset collected with an RGB-D camera mounted on a mobile robot. The dataset embeds the challenges faced by a robot in a real-life application and provides a useful tool for validating object recognition algorithms. Besides describing the characteristics of the dataset, the paper evaluates the performance of a collection of well-established deep convolutional networks on the new dataset and analyzes the transferability of deep representations from Web images to robotic data. Despite the promising results obtained with such representations, the experiments demonstrate that object classification with real-life robotic data is far from being solved. Finally, we provide a comparative study to analyze and highlight the open challenges in robot vision, explaining the discrepancies in the performance.
Boosting Domain Adaptation by Discovering Latent Domains
May 03, 2018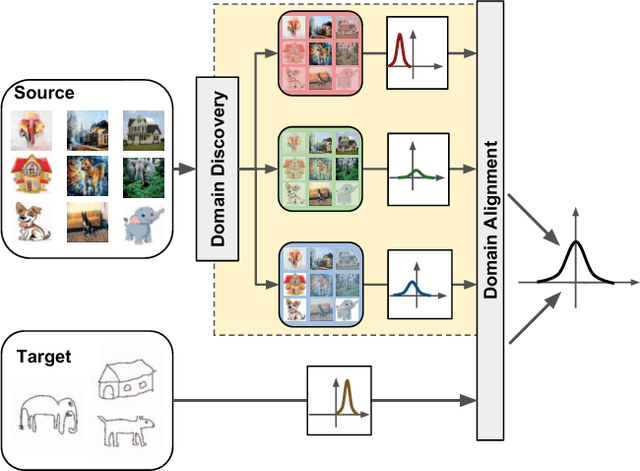

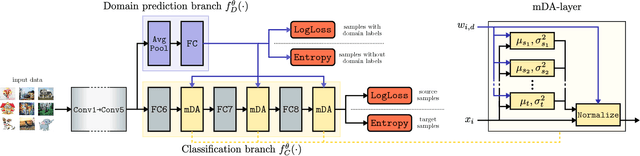
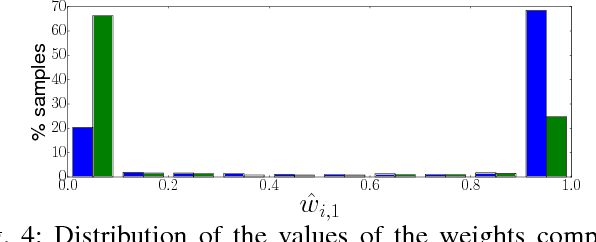
Current Domain Adaptation (DA) methods based on deep architectures assume that the source samples arise from a single distribution. However, in practice, most datasets can be regarded as mixtures of multiple domains. In these cases exploiting single-source DA methods for learning target classifiers may lead to sub-optimal, if not poor, results. In addition, in many applications it is difficult to manually provide the domain labels for all source data points, i.e. latent domains should be automatically discovered. This paper introduces a novel Convolutional Neural Network (CNN) architecture which (i) automatically discovers latent domains in visual datasets and (ii) exploits this information to learn robust target classifiers. Our approach is based on the introduction of two main components, which can be embedded into any existing CNN architecture: (i) a side branch that automatically computes the assignment of a source sample to a latent domain and (ii) novel layers that exploit domain membership information to appropriately align the distribution of the CNN internal feature representations to a reference distribution. We test our approach on publicly-available datasets, showing that it outperforms state-of-the-art multi-source DA methods by a large margin.
Adaptive Deep Learning through Visual Domain Localization
Feb 24, 2018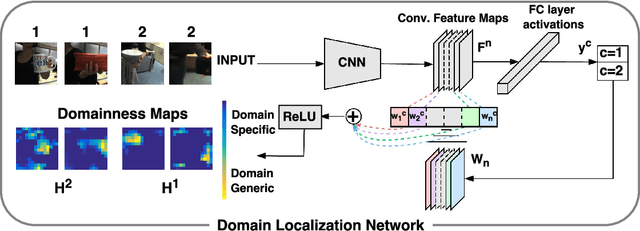
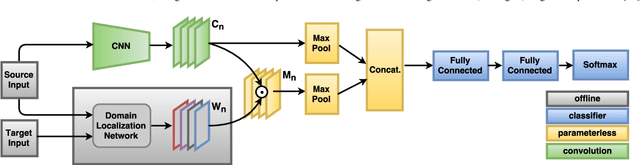
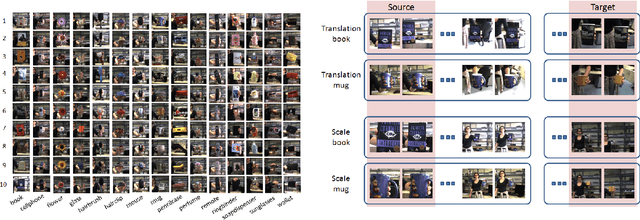
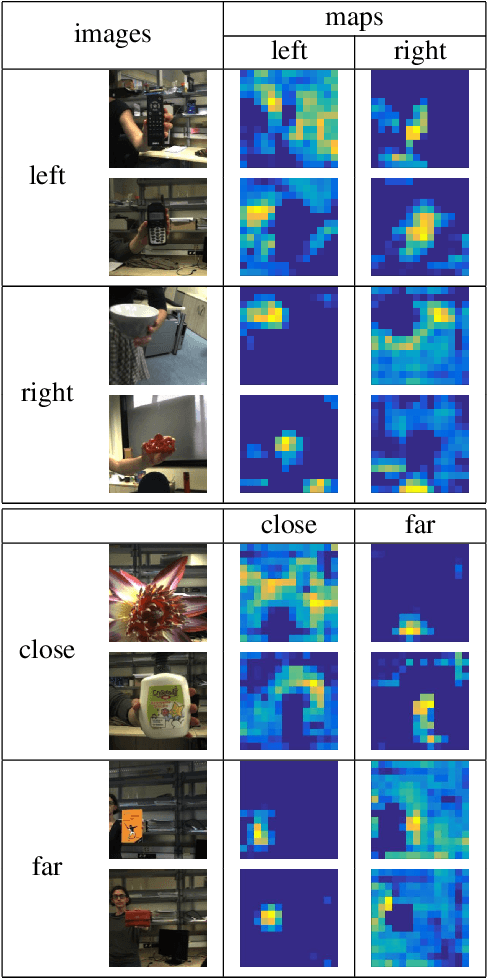
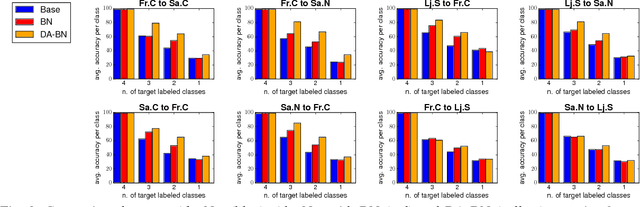
A commercial robot, trained by its manufacturer to recognize a predefined number and type of objects, might be used in many settings, that will in general differ in their illumination conditions, background, type and degree of clutter, and so on. Recent computer vision works tackle this generalization issue through domain adaptation methods, assuming as source the visual domain where the system is trained and as target the domain of deployment. All approaches assume to have access to images from all classes of the target during training, an unrealistic condition in robotics applications. We address this issue proposing an algorithm that takes into account the specific needs of robot vision. Our intuition is that the nature of the domain shift experienced mostly in robotics is local. We exploit this through the learning of maps that spatially ground the domain and quantify the degree of shift, embedded into an end-to-end deep domain adaptation architecture. By explicitly localizing the roots of the domain shift we significantly reduce the number of parameters of the architecture to tune, we gain the flexibility necessary to deal with subset of categories in the target domain at training time, and we provide a clear feedback on the rationale behind any classification decision, which can be exploited in human-robot interactions. Experiments on two different settings of the iCub World database confirm the suitability of our method for robot vision.
From source to target and back: symmetric bi-directional adaptive GAN
Nov 29, 2017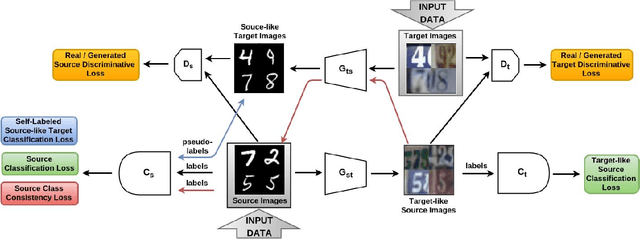
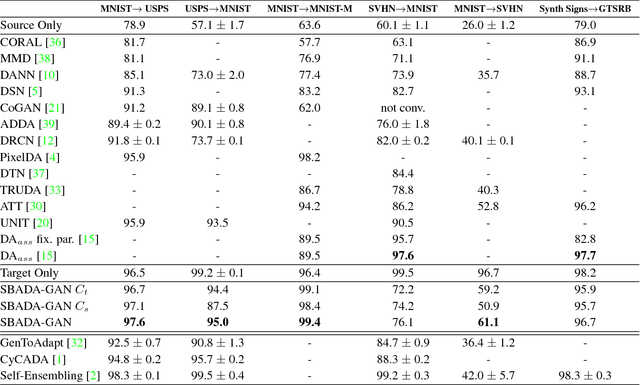
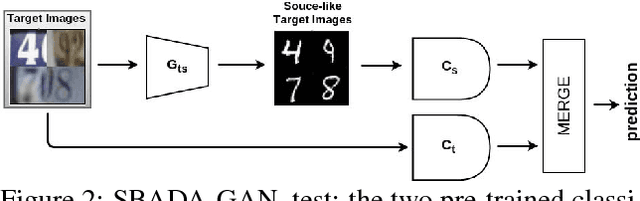
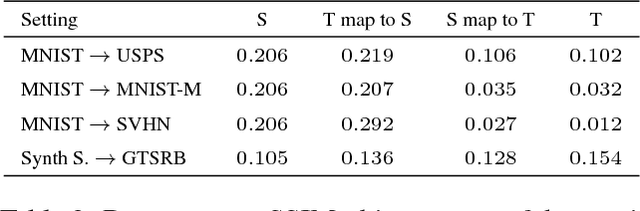
The effectiveness of generative adversarial approaches in producing images according to a specific style or visual domain has recently opened new directions to solve the unsupervised domain adaptation problem. It has been shown that source labeled images can be modified to mimic target samples making it possible to train directly a classifier in the target domain, despite the original lack of annotated data. Inverse mappings from the target to the source domain have also been evaluated but only passing through adapted feature spaces, thus without new image generation. In this paper we propose to better exploit the potential of generative adversarial networks for adaptation by introducing a novel symmetric mapping among domains. We jointly optimize bi-directional image transformations combining them with target self-labeling. Moreover we define a new class consistency loss that aligns the generators in the two directions imposing to conserve the class identity of an image passing through both domain mappings. A detailed qualitative and quantitative analysis of the reconstructed images confirm the power of our approach. By integrating the two domain specific classifiers obtained with our bi-directional network we exceed previous state-of-the-art unsupervised adaptation results on four different benchmark datasets.
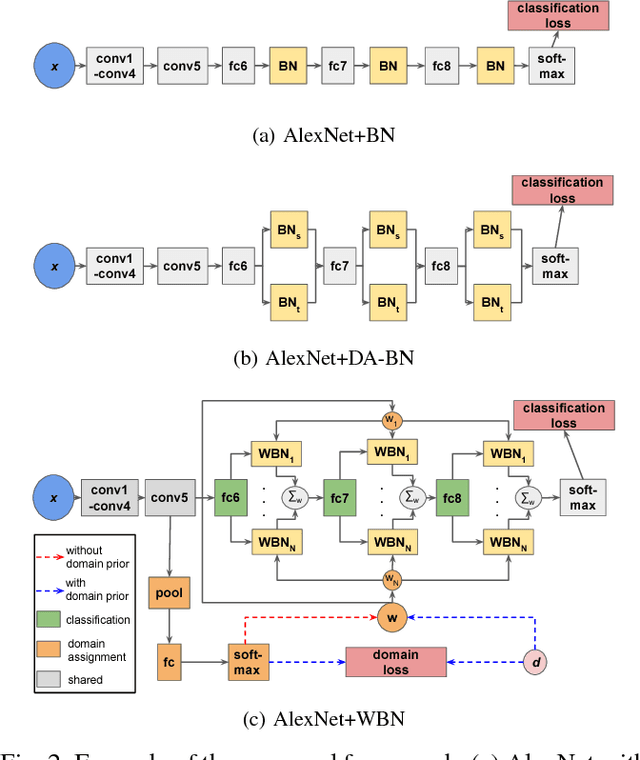
AutoDIAL: Automatic DomaIn Alignment Layers
Nov 27, 2017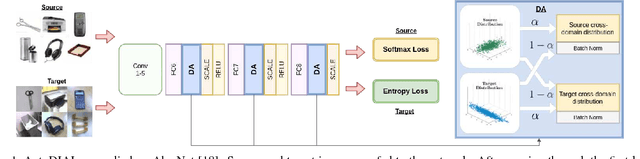
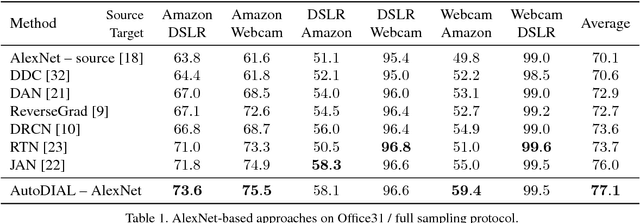
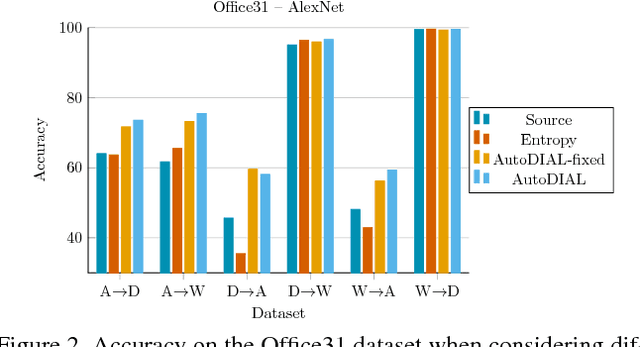
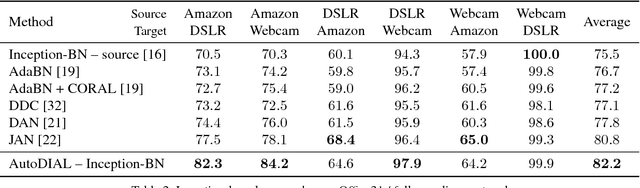
Classifiers trained on given databases perform poorly when tested on data acquired in different settings. This is explained in domain adaptation through a shift among distributions of the source and target domains. Attempts to align them have traditionally resulted in works reducing the domain shift by introducing appropriate loss terms, measuring the discrepancies between source and target distributions, in the objective function. Here we take a different route, proposing to align the learned representations by embedding in any given network specific Domain Alignment Layers, designed to match the source and target feature distributions to a reference one. Opposite to previous works which define a priori in which layers adaptation should be performed, our method is able to automatically learn the degree of feature alignment required at different levels of the deep network. Thorough experiments on different public benchmarks, in the unsupervised setting, confirm the power of our approach.
Visual Cues to Improve Myoelectric Control of Upper Limb Prostheses
Aug 29, 2017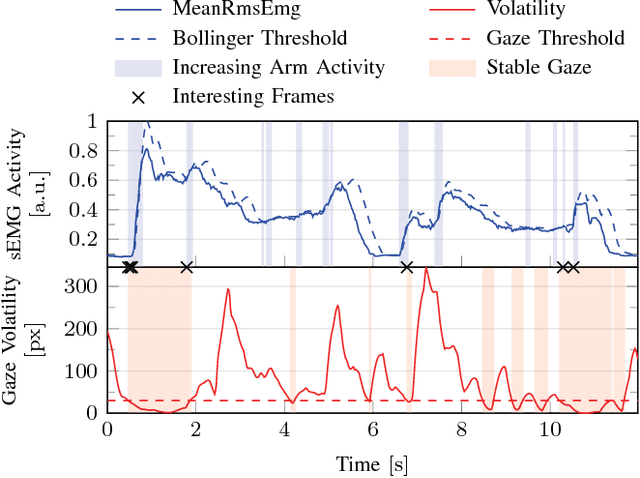
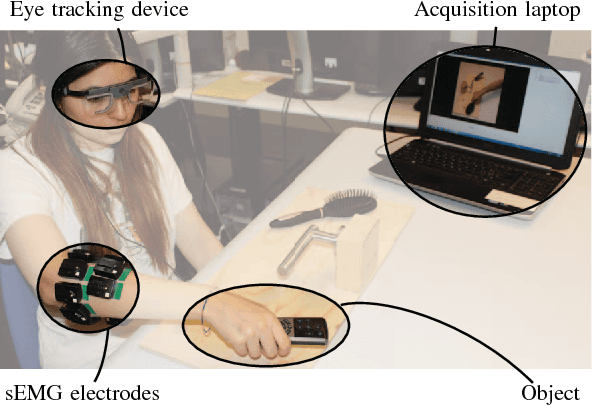
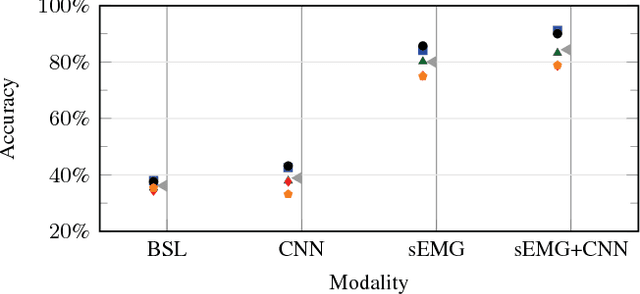
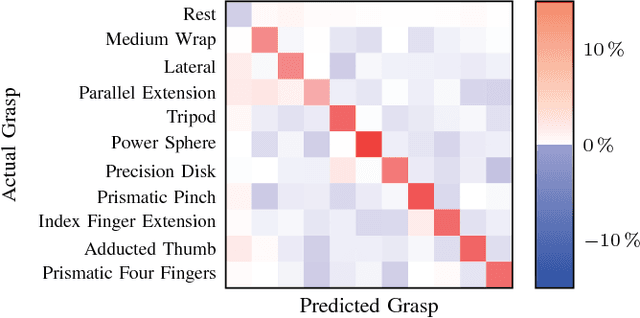
The instability of myoelectric signals over time complicates their use to control highly articulated prostheses. To address this problem, studies have tried to combine surface electromyography with modalities that are less affected by the amputation and environment, such as accelerometry or gaze information. In the latter case, the hypothesis is that a subject looks at the object he or she intends to manipulate and that knowing this object's affordances allows to constrain the set of possible grasps. In this paper, we develop an automated way to detect stable fixations and show that gaze information is indeed helpful in predicting hand movements. In our multimodal approach, we automatically detect stable gazes and segment an object of interest around the subject's fixation in the visual frame. The patch extracted around this object is subsequently fed through an off-the-shelf deep convolutional neural network to obtain a high level feature representation, which is then combined with traditional surface electromyography in the classification stage. Tests have been performed on a dataset acquired from five intact subjects who performed ten types of grasps on various objects as well as in a functional setting. They show that the addition of gaze information increases the classification accuracy considerably. Further analysis demonstrates that this improvement is consistent for all grasps and concentrated during the movement onset and offset.
Bridging between Computer and Robot Vision through Data Augmentation: a Case Study on Object Recognition
May 05, 2017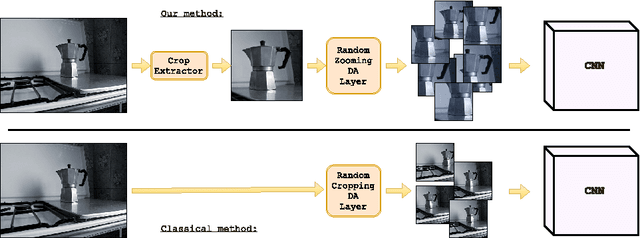
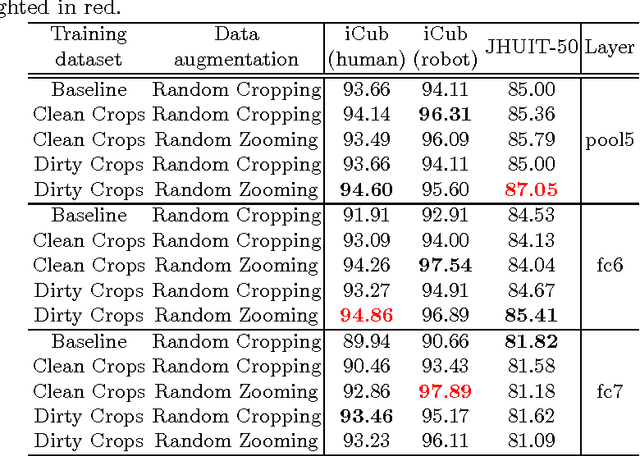

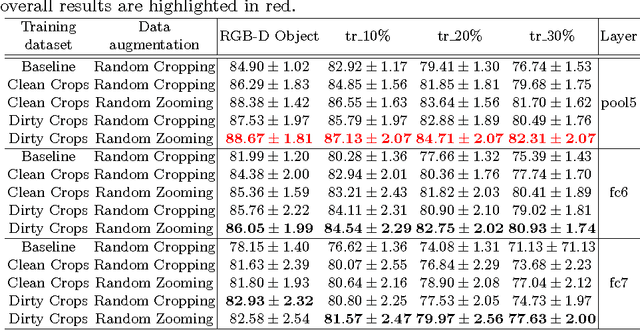
Despite the impressive progress brought by deep network in visual object recognition, robot vision is still far from being a solved problem. The most successful convolutional architectures are developed starting from ImageNet, a large scale collection of images of object categories downloaded from the Web. This kind of images is very different from the situated and embodied visual experience of robots deployed in unconstrained settings. To reduce the gap between these two visual experiences, this paper proposes a simple yet effective data augmentation layer that zooms on the object of interest and simulates the object detection outcome of a robot vision system. The layer, that can be used with any convolutional deep architecture, brings to an increase in object recognition performance of up to 7\%, in experiments performed over three different benchmark databases. Upon acceptance of the paper, our robot data augmentation layer will be made publicly available.
Learning Deep NBNN Representations for Robust Place Categorization
May 04, 2017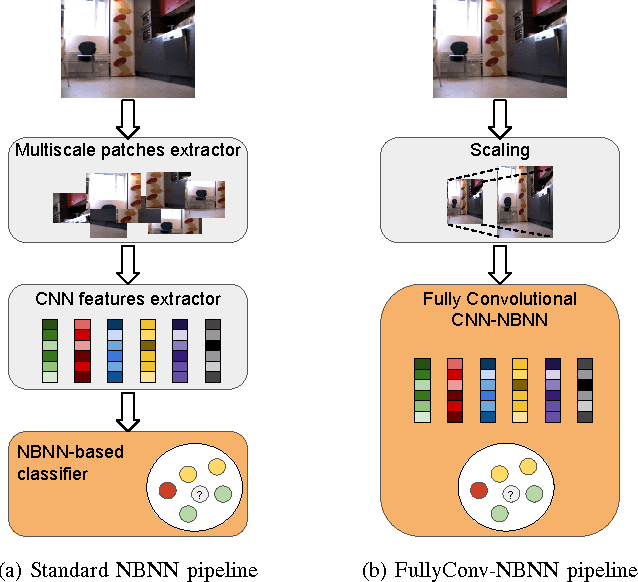
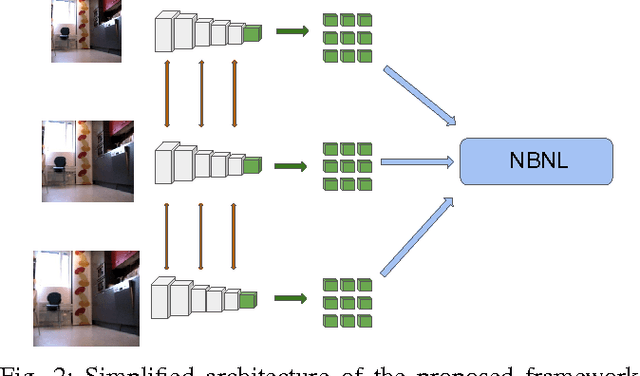

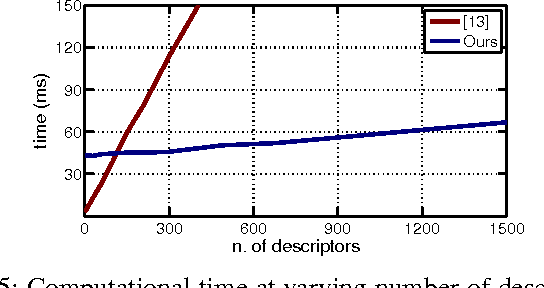
This paper presents an approach for semantic place categorization using data obtained from RGB cameras. Previous studies on visual place recognition and classification have shown that, by considering features derived from pre-trained Convolutional Neural Networks (CNNs) in combination with part-based classification models, high recognition accuracy can be achieved, even in presence of occlusions and severe viewpoint changes. Inspired by these works, we propose to exploit local deep representations, representing images as set of regions applying a Na\"{i}ve Bayes Nearest Neighbor (NBNN) model for image classification. As opposed to previous methods where CNNs are merely used as feature extractors, our approach seamlessly integrates the NBNN model into a fully-convolutional neural network. Experimental results show that the proposed algorithm outperforms previous methods based on pre-trained CNN models and that, when employed in challenging robot place recognition tasks, it is robust to occlusions, environmental and sensor changes.