 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat can a cook in Italy teach a mechanic in India? Action Recognition Generalisation Over Scenarios and Locations
Jun 14, 2023



We propose and address a new generalisation problem: can a model trained for action recognition successfully classify actions when they are performed within a previously unseen scenario and in a previously unseen location? To answer this question, we introduce the Action Recognition Generalisation Over scenarios and locations dataset (ARGO1M), which contains 1.1M video clips from the large-scale Ego4D dataset, across 10 scenarios and 13 locations. We demonstrate recognition models struggle to generalise over 10 proposed test splits, each of an unseen scenario in an unseen location. We thus propose CIR, a method to represent each video as a Cross-Instance Reconstruction of videos from other domains. Reconstructions are paired with text narrations to guide the learning of a domain generalisable representation. We provide extensive analysis and ablations on ARGO1M that show CIR outperforms prior domain generalisation works on all test splits. Code and data: https://chiaraplizz.github.io/what-can-a-cook/.
Are Local Features All You Need for Cross-Domain Visual Place Recognition?
Apr 12, 2023Visual Place Recognition is a task that aims to predict the coordinates of an image (called query) based solely on visual clues. Most commonly, a retrieval approach is adopted, where the query is matched to the most similar images from a large database of geotagged photos, using learned global descriptors. Despite recent advances, recognizing the same place when the query comes from a significantly different distribution is still a major hurdle for state of the art retrieval methods. Examples are heavy illumination changes (e.g. night-time images) or substantial occlusions (e.g. transient objects). In this work we explore whether re-ranking methods based on spatial verification can tackle these challenges, following the intuition that local descriptors are inherently more robust than global features to domain shifts. To this end, we provide a new, comprehensive benchmark on current state of the art models. We also introduce two new demanding datasets with night and occluded queries, to be matched against a city-wide database. Code and datasets are available at https://github.com/gbarbarani/re-ranking-for-VPR.
Bringing Online Egocentric Action Recognition into the wild
Nov 06, 2022



To enable a safe and effective human-robot cooperation, it is crucial to develop models for the identification of human activities. Egocentric vision seems to be a viable solution to solve this problem, and therefore many works provide deep learning solutions to infer human actions from first person videos. However, although very promising, most of these do not consider the major challenges that comes with a realistic deployment, such as the portability of the model, the need for real-time inference, and the robustness with respect to the novel domains (i.e., new spaces, users, tasks). With this paper, we set the boundaries that egocentric vision models should consider for realistic applications, defining a novel setting of egocentric action recognition in the wild, which encourages researchers to develop novel, applications-aware solutions. We also present a new model-agnostic technique that enables the rapid repurposing of existing architectures in this new context, demonstrating the feasibility to deploy a model on a tiny device (Jetson Nano) and to perform the task directly on the edge with very low energy consumption (2.4W on average at 50 fps).
Hierarchical Instance Mixing across Domains in Aerial Segmentation
Oct 12, 2022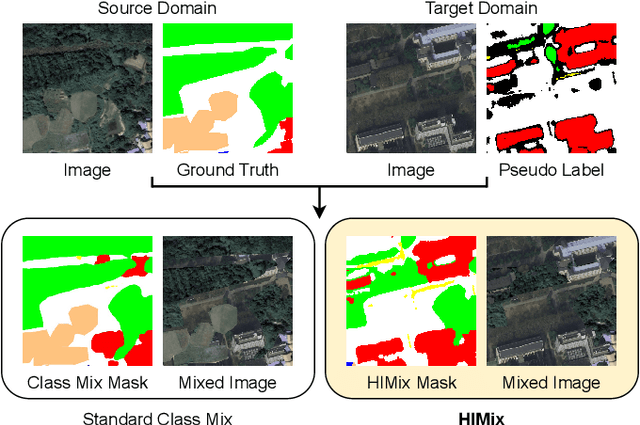
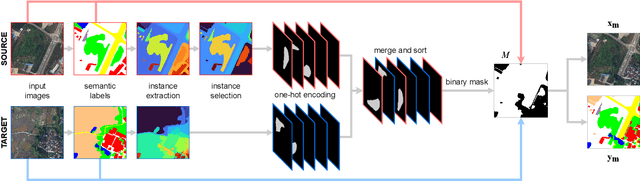

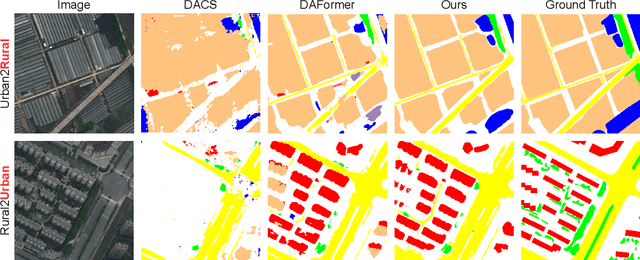
We investigate the task of unsupervised domain adaptation in aerial semantic segmentation and discover that the current state-of-the-art algorithms designed for autonomous driving based on domain mixing do not translate well to the aerial setting. This is due to two factors: (i) a large disparity in the extension of the semantic categories, which causes a domain imbalance in the mixed image, and (ii) a weaker structural consistency in aerial scenes than in driving scenes since the same scene might be viewed from different perspectives and there is no well-defined and repeatable structure of the semantic elements in the images. Our solution to these problems is composed of: (i) a new mixing strategy for aerial segmentation across domains called Hierarchical Instance Mixing (HIMix), which extracts a set of connected components from each semantic mask and mixes them according to a semantic hierarchy and, (ii) a twin-head architecture in which two separate segmentation heads are fed with variations of the same images in a contrastive fashion to produce finer segmentation maps. We conduct extensive experiments on the LoveDA benchmark, where our solution outperforms the current state-of-the-art.
Learning Across Domains and Devices: Style-Driven Source-Free Domain Adaptation in Clustered Federated Learning
Oct 05, 2022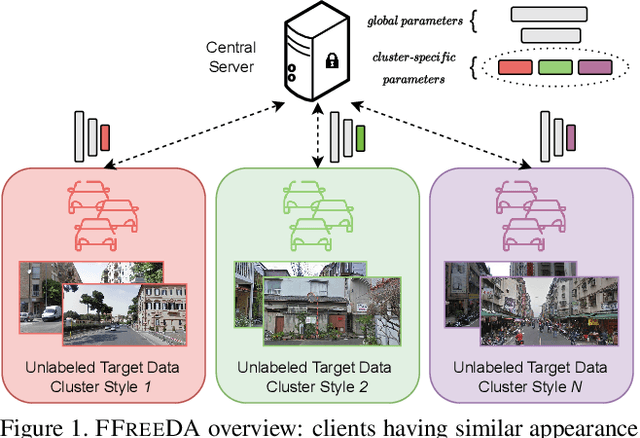
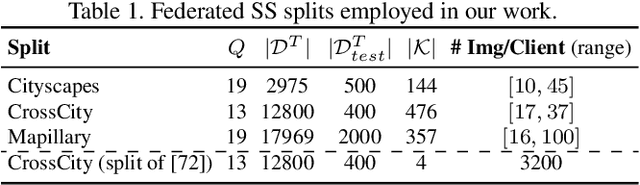
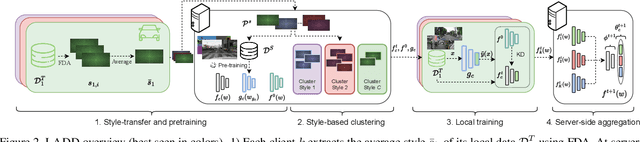
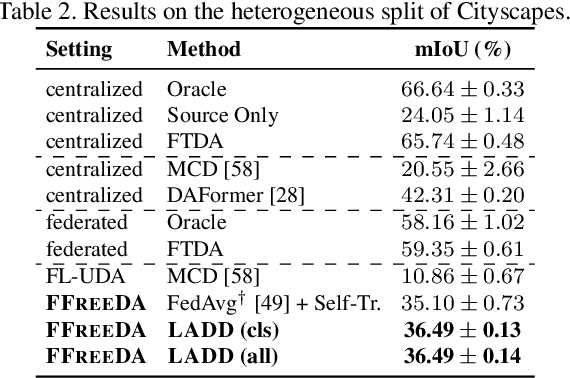
Federated Learning (FL) has recently emerged as a possible way to tackle the domain shift in real-world Semantic Segmentation (SS) without compromising the private nature of the collected data. However, most of the existing works on FL unrealistically assume labeled data in the remote clients. Here we propose a novel task (FFREEDA) in which the clients' data is unlabeled and the server accesses a source labeled dataset for pre-training only. To solve FFREEDA, we propose LADD, which leverages the knowledge of the pre-trained model by employing self-supervision with ad-hoc regularization techniques for local training and introducing a novel federated clustered aggregation scheme based on the clients' style. Our experiments show that our algorithm is able to efficiently tackle the new task outperforming existing approaches. The code is available at https://github.com/Erosinho13/LADD.
PoliTO-IIT-CINI Submission to the EPIC-KITCHENS-100 Unsupervised Domain Adaptation Challenge for Action Recognition
Sep 09, 2022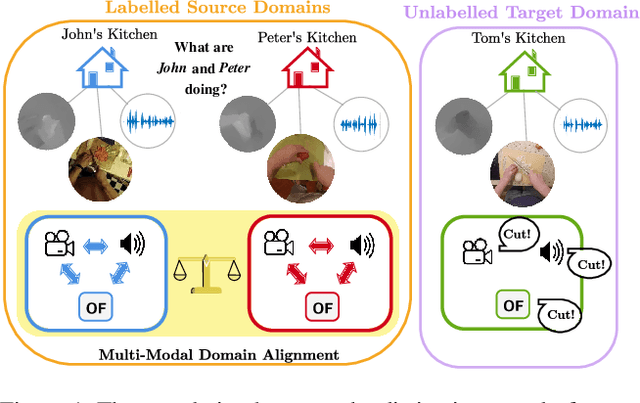


In this report, we describe the technical details of our submission to the EPIC-Kitchens-100 Unsupervised Domain Adaptation (UDA) Challenge in Action Recognition. To tackle the domain-shift which exists under the UDA setting, we first exploited a recent Domain Generalization (DG) technique, called Relative Norm Alignment (RNA). Secondly, we extended this approach to work on unlabelled target data, enabling a simpler adaptation of the model to the target distribution in an unsupervised fashion. To this purpose, we included in our framework UDA algorithms, such as multi-level adversarial alignment and attentive entropy. By analyzing the challenge setting, we notice the presence of a secondary concurrence shift in the data, which is usually called environmental bias. It is caused by the existence of different environments, i.e., kitchens. To deal with these two shifts (environmental and temporal), we extended our system to perform Multi-Source Multi-Target Domain Adaptation. Finally, we employed distinct models in our final proposal to leverage the potential of popular video architectures, and we introduced two more losses for the ensemble adaptation. Our submission (entry 'plnet') is visible on the leaderboard and ranked in 2nd position for 'verb', and in 3rd position for both 'noun' and 'action'.
Detecting the unknown in Object Detection
Aug 24, 2022
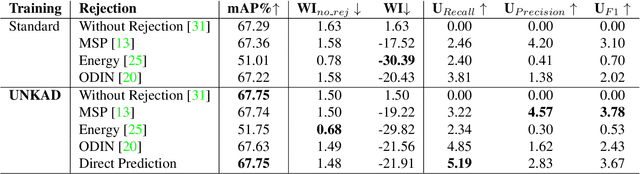

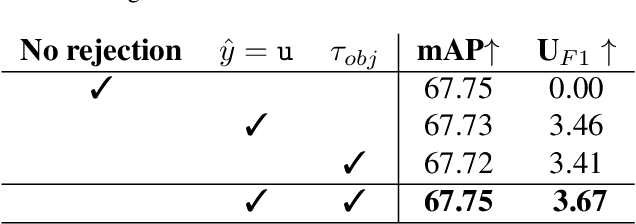
Object detection methods have witnessed impressive improvements in the last years thanks to the design of novel neural network architectures and the availability of large scale datasets. However, current methods have a significant limitation: they are able to detect only the classes observed during training time, that are only a subset of all the classes that a detector may encounter in the real world. Furthermore, the presence of unknown classes is often not considered at training time, resulting in methods not even able to detect that an unknown object is present in the image. In this work, we address the problem of detecting unknown objects, known as open-set object detection. We propose a novel training strategy, called UNKAD, able to predict unknown objects without requiring any annotation of them, exploiting non annotated objects that are already present in the background of training images. In particular, exploiting the four-steps training strategy of Faster R-CNN, UNKAD first identifies and pseudo-labels unknown objects and then uses the pseudo-annotations to train an additional unknown class. While UNKAD can directly detect unknown objects, we further combine it with previous unknown detection techniques, showing that it improves their performance at no costs.
Learning Sequential Descriptors for Sequence-based Visual Place Recognition
Jul 08, 2022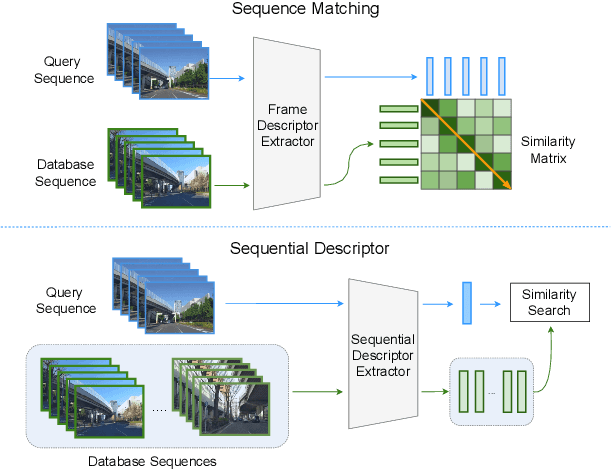

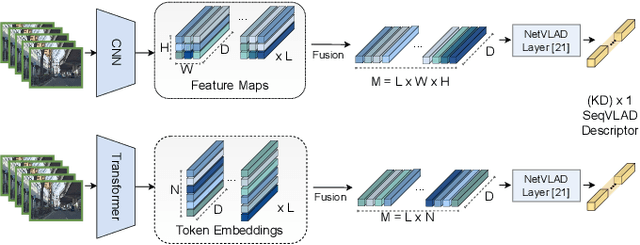
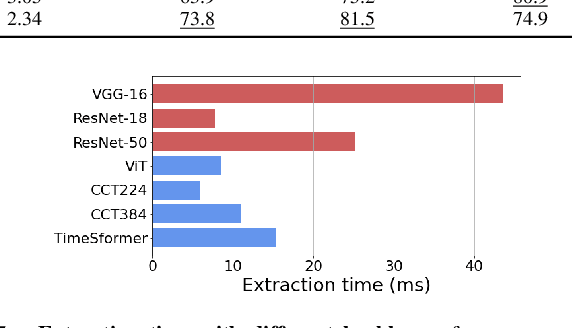
In robotics, Visual Place Recognition is a continuous process that receives as input a video stream to produce a hypothesis of the robot's current position within a map of known places. This task requires robust, scalable, and efficient techniques for real applications. This work proposes a detailed taxonomy of techniques using sequential descriptors, highlighting different mechanism to fuse the information from the individual images. This categorization is supported by a complete benchmark of experimental results that provides evidence on the strengths and weaknesses of these different architectural choices. In comparison to existing sequential descriptors methods, we further investigate the viability of Transformers instead of CNN backbones, and we propose a new ad-hoc sequence-level aggregator called SeqVLAD, which outperforms prior state of the art on different datasets. The code is available at https://github.com/vandal-vpr/vg-transformers.
Modeling Missing Annotations for Incremental Learning in Object Detection
Apr 21, 2022
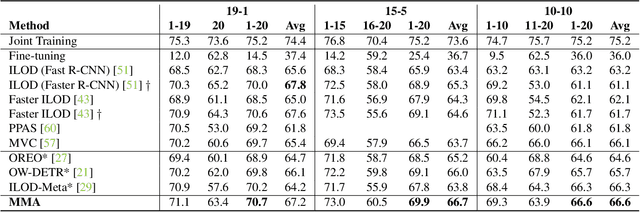
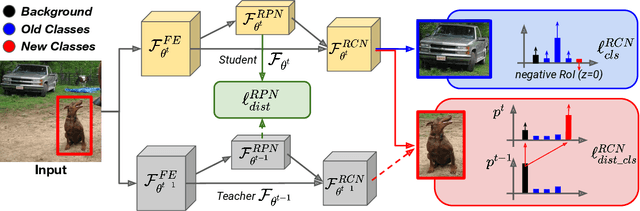

Despite the recent advances in the field of object detection, common architectures are still ill-suited to incrementally detect new categories over time. They are vulnerable to catastrophic forgetting: they forget what has been already learned while updating their parameters in absence of the original training data. Previous works extended standard classification methods in the object detection task, mainly adopting the knowledge distillation framework. However, we argue that object detection introduces an additional problem, which has been overlooked. While objects belonging to new classes are learned thanks to their annotations, if no supervision is provided for other objects that may still be present in the input, the model learns to associate them to background regions. We propose to handle these missing annotations by revisiting the standard knowledge distillation framework. Our approach outperforms current state-of-the-art methods in every setting of the Pascal-VOC dataset. We further propose an extension to instance segmentation, outperforming the other baselines. Code can be found here: https://github.com/fcdl94/MMA
Augmentation Invariance and Adaptive Sampling in Semantic Segmentation of Agricultural Aerial Images
Apr 17, 2022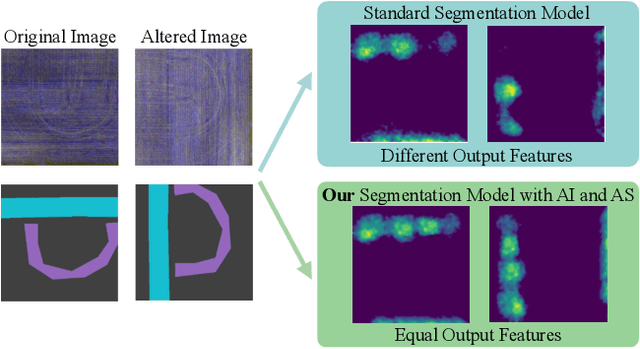
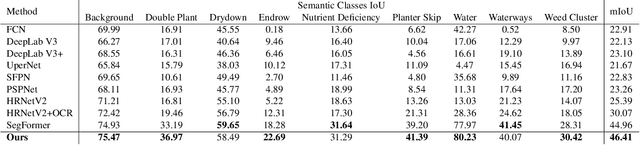
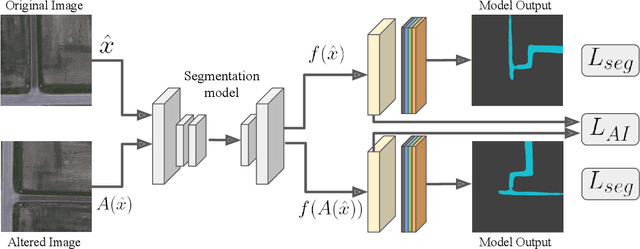
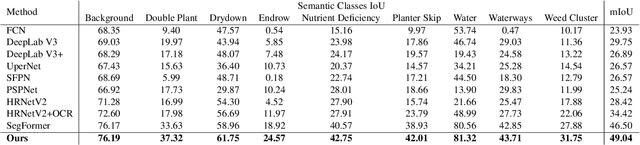
In this paper, we investigate the problem of Semantic Segmentation for agricultural aerial imagery. We observe that the existing methods used for this task are designed without considering two characteristics of the aerial data: (i) the top-down perspective implies that the model cannot rely on a fixed semantic structure of the scene, because the same scene may be experienced with different rotations of the sensor; (ii) there can be a strong imbalance in the distribution of semantic classes because the relevant objects of the scene may appear at extremely different scales (e.g., a field of crops and a small vehicle). We propose a solution to these problems based on two ideas: (i) we use together a set of suitable augmentation and a consistency loss to guide the model to learn semantic representations that are invariant to the photometric and geometric shifts typical of the top-down perspective (Augmentation Invariance); (ii) we use a sampling method (Adaptive Sampling) that selects the training images based on a measure of pixel-wise distribution of classes and actual network confidence. With an extensive set of experiments conducted on the Agriculture-Vision dataset, we demonstrate that our proposed strategies improve the performance of the current state-of-the-art method.