 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Chain-of-Thought Prompting: Enhancing LLM Reasoning Performance and Efficiency
Mar 31, 2026Chain-of-Thought (CoT) prompting has significantly improved the reasoning capabilities of large language models (LLMs). However, conventional CoT often relies on unstructured, flat reasoning chains that suffer from redundancy and suboptimal performance. In this work, we introduce Hierarchical Chain-of-Thought (Hi-CoT) prompting, a structured reasoning paradigm specifically designed to address the challenges of complex, multi-step reasoning. Hi-CoT decomposes the reasoning process into hierarchical substeps by alternating between instructional planning and step-by-step execution. This decomposition enables LLMs to better manage long reasoning horizons and maintain logical coherence. Extensive evaluations across diverse LLMs and mathematical reasoning benchmarks show that Hi-CoT consistently improves average accuracy by 6.2% (up to 61.4% on certain models and tasks) while reducing reasoning trace length by 13.9% compared to CoT prompting. We further show that accuracy and efficiency are maximized when models strictly adhere to the hierarchical structure. Our code is available at https://github.com/XingshuaiHuang/Hi-CoT.
Multitask-Informed Prior for In-Context Learning on Tabular Data: Application to Steel Property Prediction
Mar 24, 2026Accurate prediction of mechanical properties of steel during hot rolling processes, such as Thin Slab Direct Rolling (TSDR), remains challenging due to complex interactions among chemical compositions, processing parameters, and resultant microstructures. Traditional empirical and experimental methodologies, while effective, are often resource-intensive and lack adaptability to varied production conditions. Moreover, most existing approaches do not explicitly leverage the strong correlations among key mechanical properties, missing an opportunity to improve predictive accuracy through multitask learning. To address this, we present a multitask learning framework that injects multitask awareness into the prior of TabPFN--a transformer-based foundation model for in-context learning on tabular data--through novel fine-tuning strategies. Originally designed for single-target regression or classification, we augment TabPFN's prior with two complementary approaches: (i) target averaging, which provides a unified scalar signal compatible with TabPFN's single-target architecture, and (ii) task-specific adapters, which introduce task-specific supervision during fine-tuning. These strategies jointly guide the model toward a multitask-informed prior that captures cross-property relationships among key mechanical metrics. Extensive experiments on an industrial TSDR dataset demonstrate that our multitask adaptations outperform classical machine learning methods and recent state-of-the-art tabular learning models across multiple evaluation metrics. Notably, our approach enhances both predictive accuracy and computational efficiency compared to task-specific fine-tuning, demonstrating that multitask-aware prior adaptation enables foundation models for tabular data to deliver scalable, rapid, and reliable deployment for automated industrial quality control and process optimization in TSDR.
Explainable Attention for Few-shot Learning and Beyond
Oct 11, 2023Attention mechanisms have exhibited promising potential in enhancing learning models by identifying salient portions of input data. This is particularly valuable in scenarios where limited training samples are accessible due to challenges in data collection and labeling. Drawing inspiration from human recognition processes, we posit that an AI baseline's performance could be more accurate and dependable if it is exposed to essential segments of raw data rather than the entire input dataset, akin to human perception. However, the task of selecting these informative data segments, referred to as hard attention finding, presents a formidable challenge. In situations with few training samples, existing studies struggle to locate such informative regions due to the large number of training parameters that cannot be effectively learned from the available limited samples. In this study, we introduce a novel and practical framework for achieving explainable hard attention finding, specifically tailored for few-shot learning scenarios, called FewXAT. Our approach employs deep reinforcement learning to implement the concept of hard attention, directly impacting raw input data and thus rendering the process interpretable for human understanding. Through extensive experimentation across various benchmark datasets, we demonstrate the efficacy of our proposed method.
NPC: Neighbors Progressive Competition Algorithm for Classification of Imbalanced Data Sets
Nov 29, 2017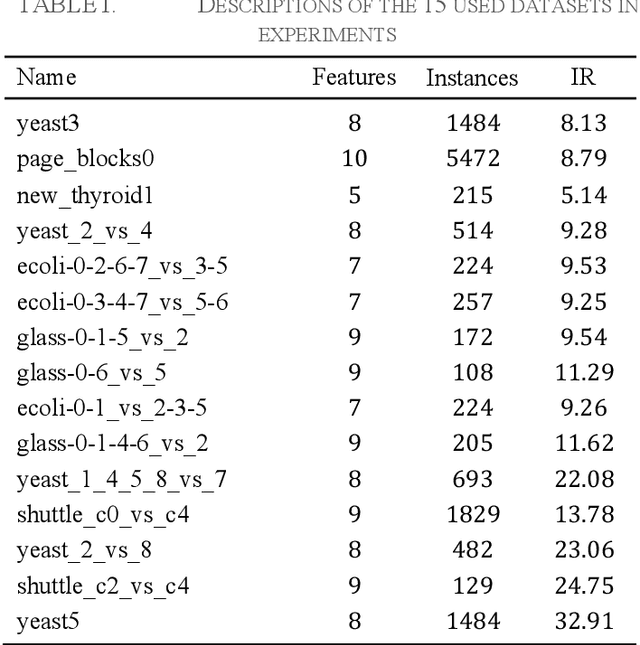

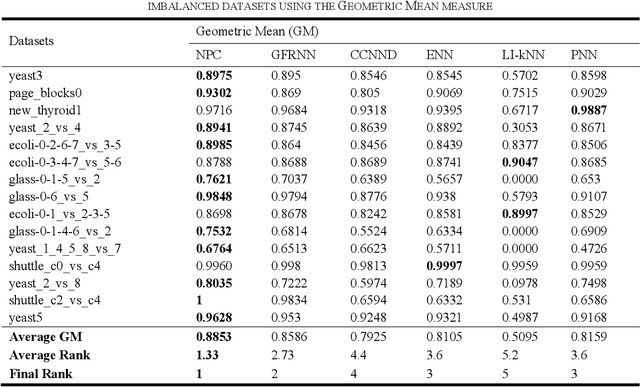
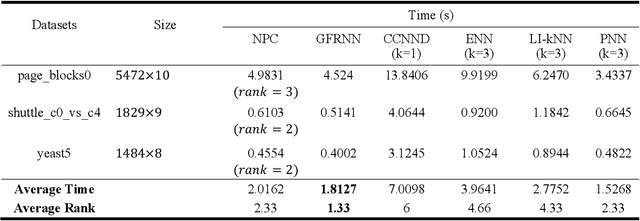
Learning from many real-world datasets is limited by a problem called the class imbalance problem. A dataset is imbalanced when one class (the majority class) has significantly more samples than the other class (the minority class). Such datasets cause typical machine learning algorithms to perform poorly on the classification task. To overcome this issue, this paper proposes a new approach Neighbors Progressive Competition (NPC) for classification of imbalanced datasets. Whilst the proposed algorithm is inspired by weighted k-Nearest Neighbor (k-NN) algorithms, it has major differences from them. Unlike k- NN, NPC does not limit its decision criteria to a preset number of nearest neighbors. In contrast, NPC considers progressively more neighbors of the query sample in its decision making until the sum of grades for one class is much higher than the other classes. Furthermore, NPC uses a novel method for grading the training samples to compensate for the imbalance issue. The grades are calculated using both local and global information. In brief, the contribution of this paper is an entirely new classifier for handling the imbalance issue effectively without any manually-set parameters or any need for expert knowledge. Experimental results compare the proposed approach with five representative algorithms applied to fifteen imbalanced datasets and illustrate this algorithms effectiveness.