 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounting in the 2020s: Binned Representations and Inclusive Performance Measures for Deep Crowd Counting Approaches
Apr 10, 2022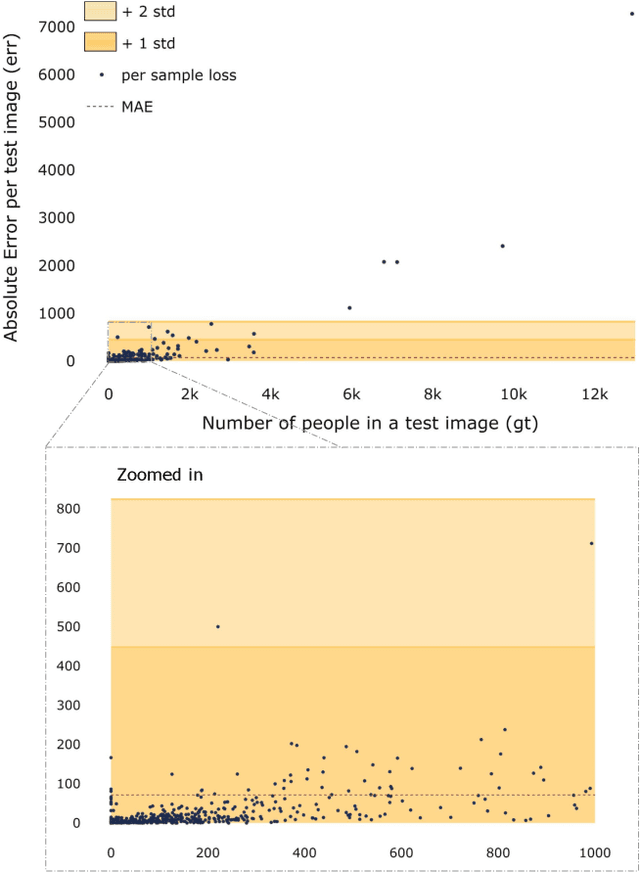
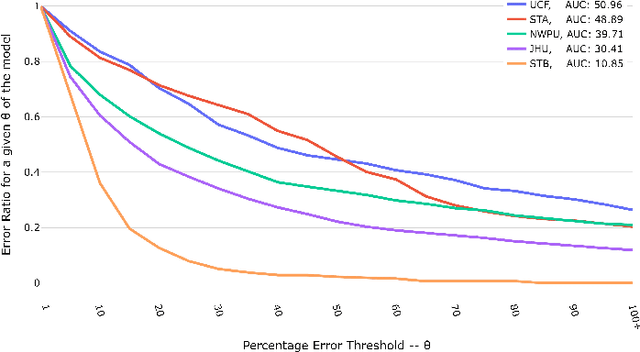
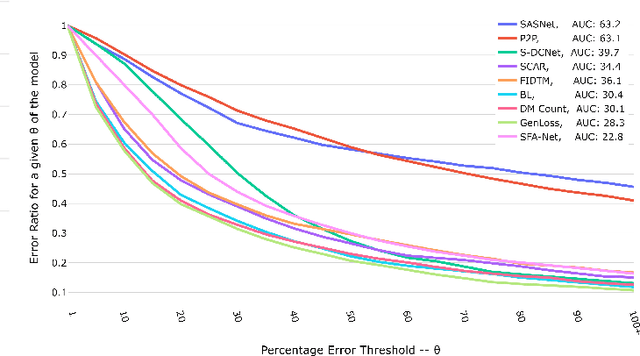
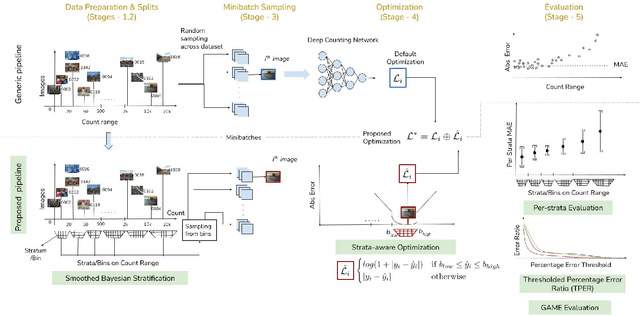
The data distribution in popular crowd counting datasets is typically heavy tailed and discontinuous. This skew affects all stages within the pipelines of deep crowd counting approaches. Specifically, the approaches exhibit unacceptably large standard deviation wrt statistical measures (MSE, MAE). To address such concerns in a holistic manner, we make two fundamental contributions. Firstly, we modify the training pipeline to accommodate the knowledge of dataset skew. To enable principled and balanced minibatch sampling, we propose a novel smoothed Bayesian binning approach. More specifically, we propose a novel cost function which can be readily incorporated into existing crowd counting deep networks to encourage bin-aware optimization. As the second contribution, we introduce additional performance measures which are more inclusive and throw light on various comparative performance aspects of the deep networks. We also show that our binning-based modifications retain their superiority wrt the newly proposed performance measures. Overall, our contributions enable a practically useful and detail-oriented characterization of performance for crowd counting approaches.
Hostility Detection and Covid-19 Fake News Detection in Social Media
Jan 15, 2021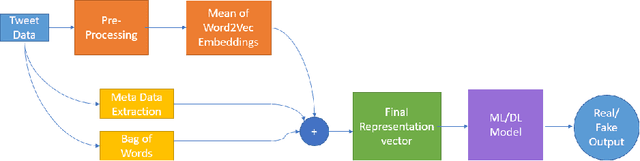
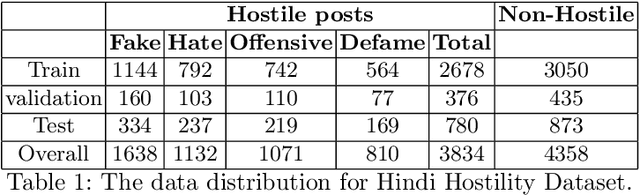
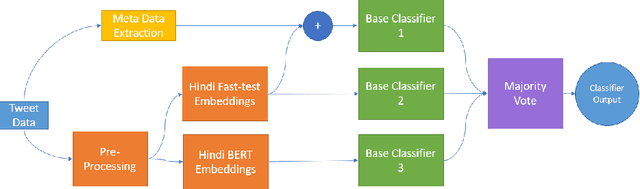
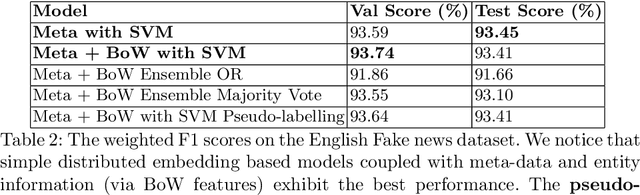
Withtheadventofsocialmedia,therehasbeenanextremely rapid increase in the content shared online. Consequently, the propagation of fake news and hostile messages on social media platforms has also skyrocketed. In this paper, we address the problem of detecting hostile and fake content in the Devanagari (Hindi) script as a multi-class, multi-label problem. Using NLP techniques, we build a model that makes use of an abusive language detector coupled with features extracted via Hindi BERT and Hindi FastText models and metadata. Our model achieves a 0.97 F1 score on coarse grain evaluation on Hostility detection task. Additionally, we built models to identify fake news related to Covid-19 in English tweets. We leverage entity information extracted from the tweets along with textual representations learned from word embeddings and achieve a 0.93 F1 score on the English fake news detection task.
AI-based Monitoring and Response System for Hospital Preparedness towards COVID-19 in Southeast Asia
Jul 30, 2020
This research paper proposes a COVID-19 monitoring and response system to identify the surge in the volume of patients at hospitals and shortage of critical equipment like ventilators in South-east Asian countries, to understand the burden on health facilities. This can help authorities in these regions with resource planning measures to redirect resources to the regions identified by the model. Due to the lack of publicly available data on the influx of patients in hospitals, or the shortage of equipment, ICU units or hospital beds that regions in these countries might be facing, we leverage Twitter data for gleaning this information. The approach has yielded accurate results for states in India, and we are working on validating the model for the remaining countries so that it can serve as a reliable tool for authorities to monitor the burden on hospitals.
Iterative Data Programming for Expanding Text Classification Corpora
Feb 04, 2020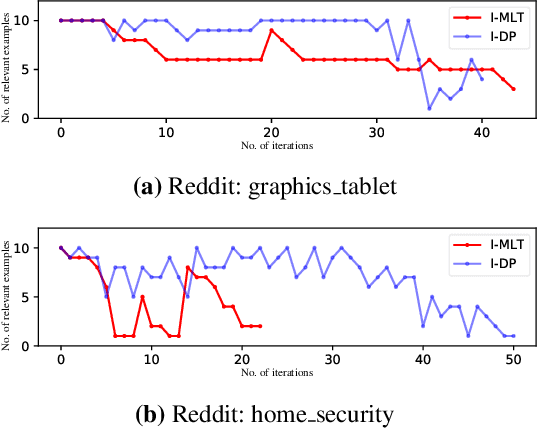
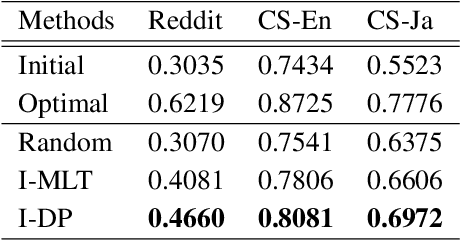
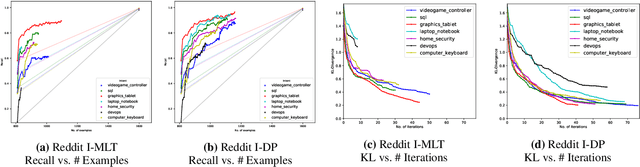
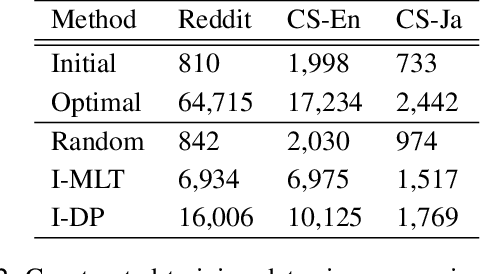
Real-world text classification tasks often require many labeled training examples that are expensive to obtain. Recent advancements in machine teaching, specifically the data programming paradigm, facilitate the creation of training data sets quickly via a general framework for building weak models, also known as labeling functions, and denoising them through ensemble learning techniques. We present a fast, simple data programming method for augmenting text data sets by generating neighborhood-based weak models with minimal supervision. Furthermore, our method employs an iterative procedure to identify sparsely distributed examples from large volumes of unlabeled data. The iterative data programming techniques improve newer weak models as more labeled data is confirmed with human-in-loop. We show empirical results on sentence classification tasks, including those from a task of improving intent recognition in conversational agents.
Design and Development of Underwater Vehicle: ANAHITA
Mar 01, 2019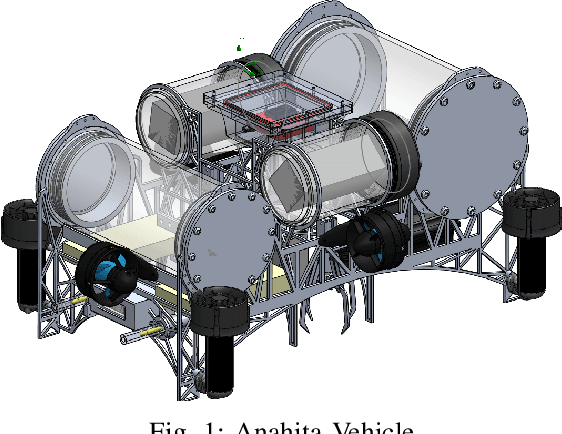
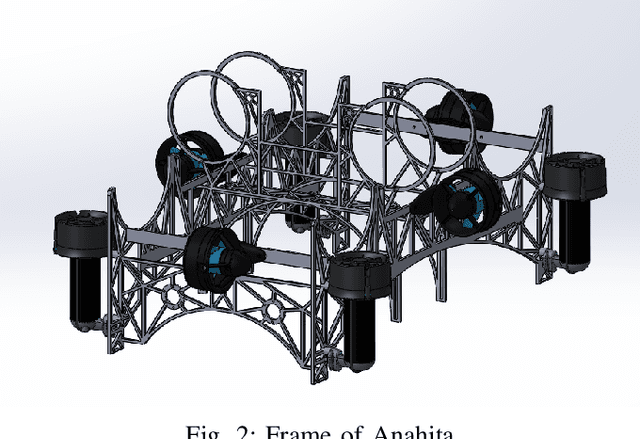
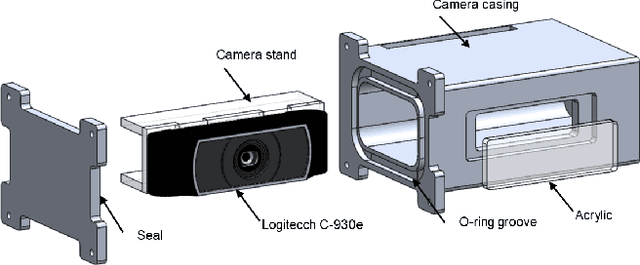
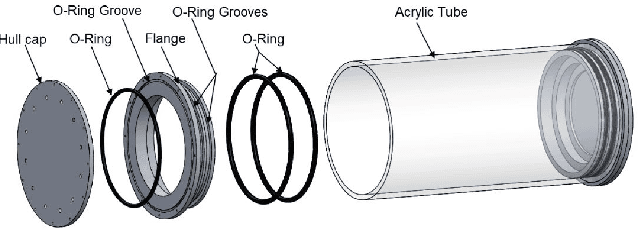
Anahita is an autonomous underwater vehicle which is currently being developed by interdisciplinary team of students at Indian Institute of Technology(IIT) Kanpur with aim to provide a platform for research in AUV to undergraduate students. This is the second vehicle which is being designed by AUV-IITK team to participate in 6th NIOT-SAVe competition organized by the National Institute of Ocean Technology, Chennai. The Vehicle has been completely redesigned with the major improvements in modularity and ease of access of all the components, keeping the design very compact and efficient. New advancements in the vehicle include, power distribution system and monitoring system. The sensors include the inertial measurement units (IMU), hydrophone array, a depth sensor, and two RGB cameras. The current vehicle features hot swappable battery pods giving a huge advantage over the previous vehicle, for longer runtime.
Bootstrapping Conversational Agents With Weak Supervision
Dec 14, 2018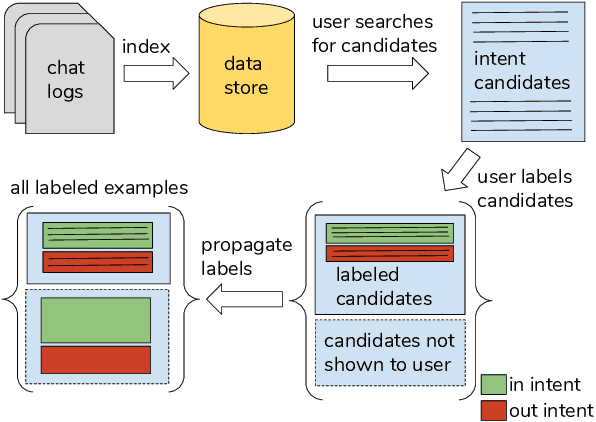

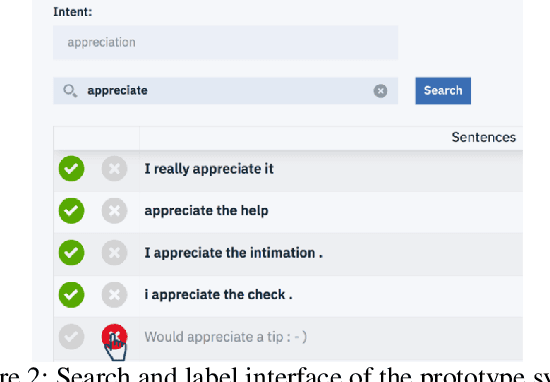
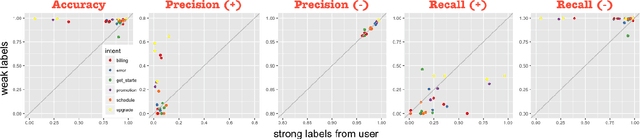
Many conversational agents in the market today follow a standard bot development framework which requires training intent classifiers to recognize user input. The need to create a proper set of training examples is often the bottleneck in the development process. In many occasions agent developers have access to historical chat logs that can provide a good quantity as well as coverage of training examples. However, the cost of labeling them with tens to hundreds of intents often prohibits taking full advantage of these chat logs. In this paper, we present a framework called \textit{search, label, and propagate} (SLP) for bootstrapping intents from existing chat logs using weak supervision. The framework reduces hours to days of labeling effort down to minutes of work by using a search engine to find examples, then relies on a data programming approach to automatically expand the labels. We report on a user study that shows positive user feedback for this new approach to build conversational agents, and demonstrates the effectiveness of using data programming for auto-labeling. While the system is developed for training conversational agents, the framework has broader application in significantly reducing labeling effort for training text classifiers.