 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification
Feb 11, 2020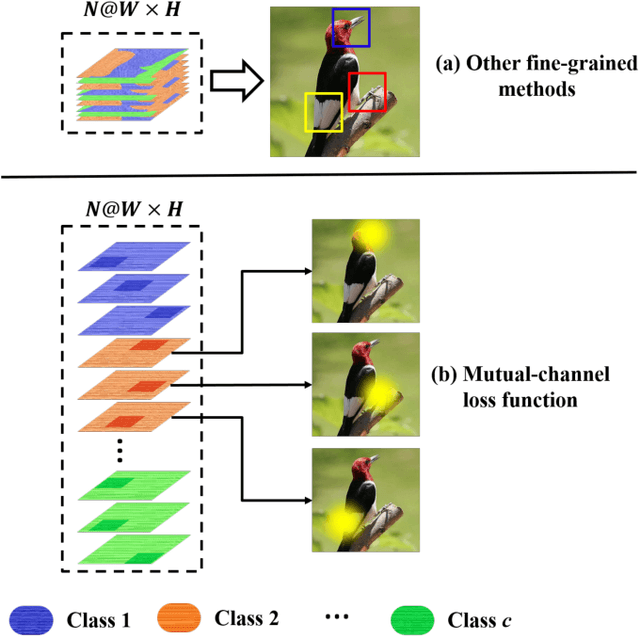
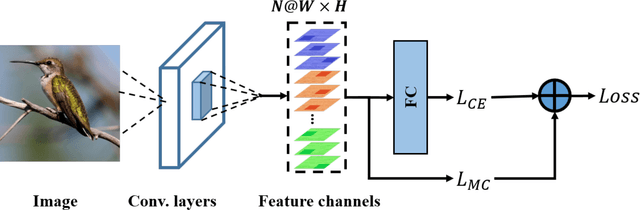
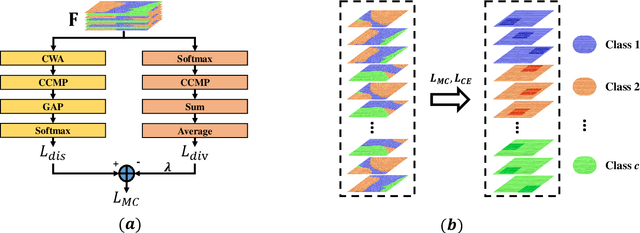
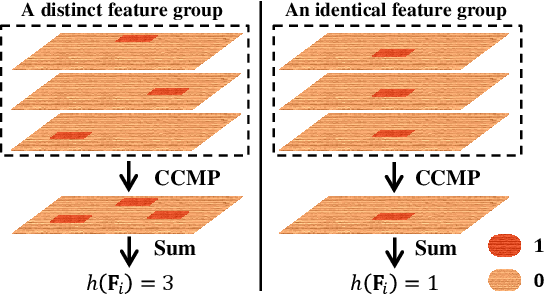
Key for solving fine-grained image categorization is finding discriminate and local regions that correspond to subtle visual traits. Great strides have been made, with complex networks designed specifically to learn part-level discriminate feature representations. In this paper, we show it is possible to cultivate subtle details without the need for overly complicated network designs or training mechanisms -- a single loss is all it takes. The main trick lies with how we delve into individual feature channels early on, as opposed to the convention of starting from a consolidated feature map. The proposed loss function, termed as mutual-channel loss (MC-Loss), consists of two channel-specific components: a discriminality component and a diversity component. The discriminality component forces all feature channels belonging to the same class to be discriminative, through a novel channel-wise attention mechanism. The diversity component additionally constraints channels so that they become mutually exclusive on spatial-wise. The end result is therefore a set of feature channels that each reflects different locally discriminative regions for a specific class. The MC-Loss can be trained end-to-end, without the need for any bounding-box/part annotations, and yields highly discriminative regions during inference. Experimental results show our MC-Loss when implemented on top of common base networks can achieve state-of-the-art performance on all four fine-grained categorization datasets (CUB-Birds, FGVC-Aircraft, Flowers-102, and Stanford-Cars). Ablative studies further demonstrate the superiority of MC-Loss when compared with other recently proposed general-purpose losses for visual classification, on two different base networks. Code available at https://github.com/dongliangchang/Mutual-Channel-Loss
Facial Micro-Expression Spotting and Recognition using Time Contrasted Feature with Visual Memory
Feb 09, 2019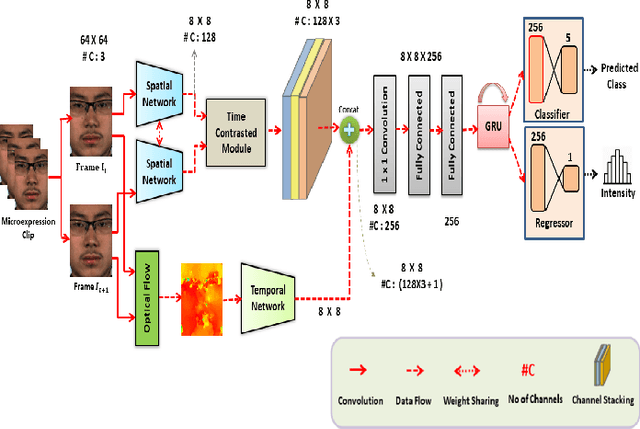
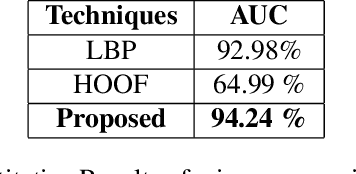
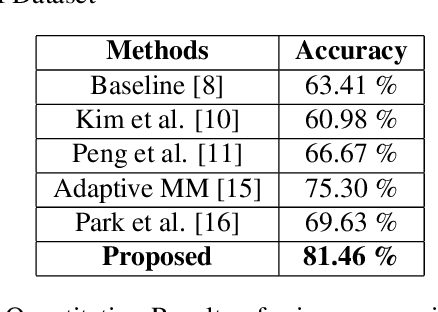

Facial micro-expressions are sudden involuntary minute muscle movements which reveal true emotions that people try to conceal. Spotting a micro-expression and recognizing it is a major challenge owing to its short duration and intensity. Many works pursued traditional and deep learning based approaches to solve this issue but compromised on learning low-level features and higher accuracy due to unavailability of datasets. This motivated us to propose a novel joint architecture of spatial and temporal network which extracts time-contrasted features from the feature maps to contrast out micro-expression from rapid muscle movements. The usage of time contrasted features greatly improved the spotting of micro-expression from inconspicuous facial movements. Also, we include a memory module to predict the class and intensity of the micro-expression across the temporal frames of the micro-expression clip. Our method achieves superior performance in comparison to other conventional approaches on CASMEII dataset.
Texture Synthesis Guided Deep Hashing for Texture Image Retrieval
Nov 04, 2018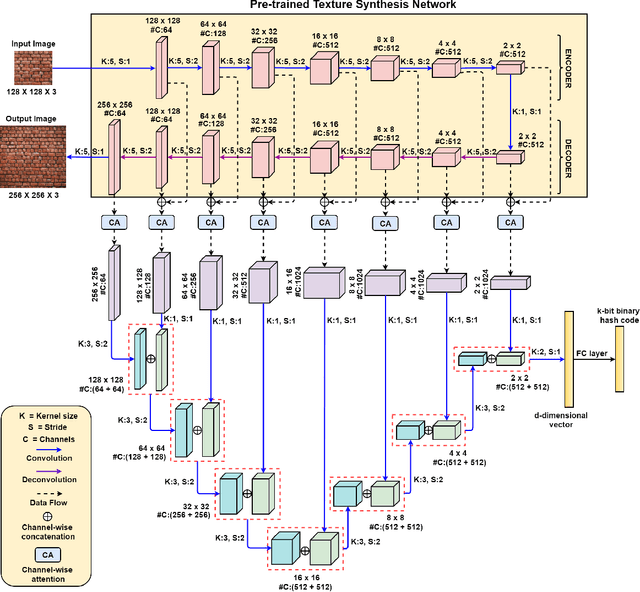
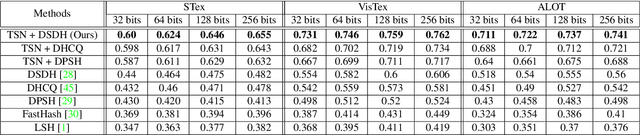

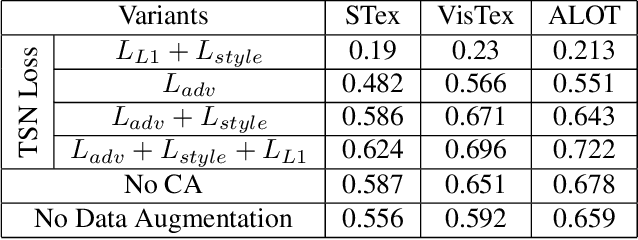
With the large-scale explosion of images and videos over the internet, efficient hashing methods have been developed to facilitate memory and time efficient retrieval of similar images. However, none of the existing works uses hashing to address texture image retrieval mostly because of the lack of sufficiently large texture image databases. Our work addresses this problem by developing a novel deep learning architecture that generates binary hash codes for input texture images. For this, we first pre-train a Texture Synthesis Network (TSN) which takes a texture patch as input and outputs an enlarged view of the texture by injecting newer texture content. Thus it signifies that the TSN encodes the learnt texture specific information in its intermediate layers. In the next stage, a second network gathers the multi-scale feature representations from the TSN's intermediate layers using channel-wise attention, combines them in a progressive manner to a dense continuous representation which is finally converted into a binary hash code with the help of individual and pairwise label information. The new enlarged texture patches also help in data augmentation to alleviate the problem of insufficient texture data and are used to train the second stage of the network. Experiments on three public texture image retrieval datasets indicate the superiority of our texture synthesis guided hashing approach over current state-of-the-art methods.
Handwriting Recognition in Low-resource Scripts using Adversarial Learning
Nov 04, 2018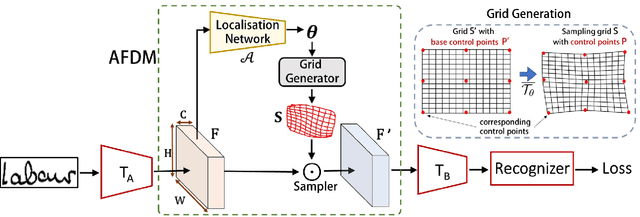
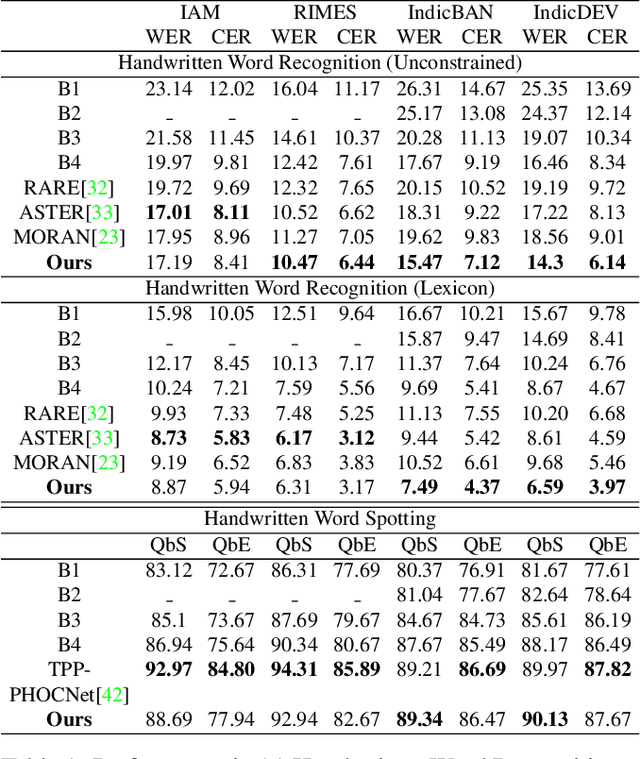
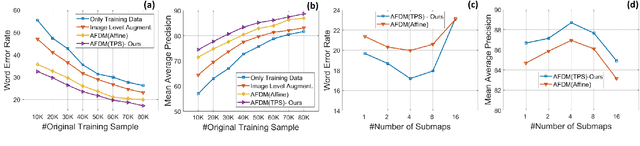

Handwritten Word Recognition and Spotting is a challenging field dealing with handwritten text possessing irregular and complex shapes. Designing models using deep neural networks makes it necessary to extend datasets in order to introduce variances and increase the number of training samples; word-retrieval is therefore very difficult in low-resource scripts. Much of the existing literature use preprocessing strategies which are seldom sufficient to cover all possible variations. We propose the Adversarial Feature Deformation Module that learns ways to elastically warp extracted features in a scalable manner. It is inserted between intermediate layers and trained alternatively with the original framework, boosting its capability to better learn highly informative features rather than trivial ones. We test our meta-framework which is built on top of popular spotting and recognition frameworks and enhanced by the AFDM not only on extensive Latin word datasets, but on sparser Indic scripts too. We record results for varying training data sizes, and observe that our enhanced network generalizes much better in the low-data regime; the overall word-error rates and mAP scores are observed to improve as well.
Query-based Logo Segmentation
Nov 04, 2018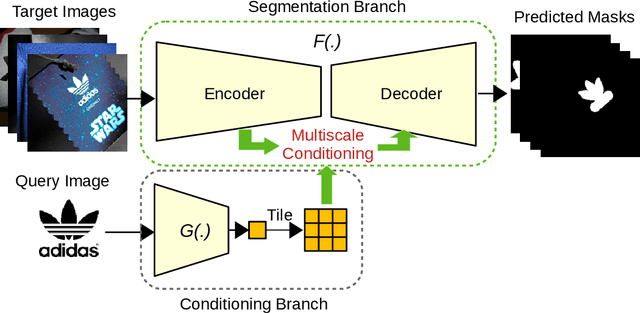
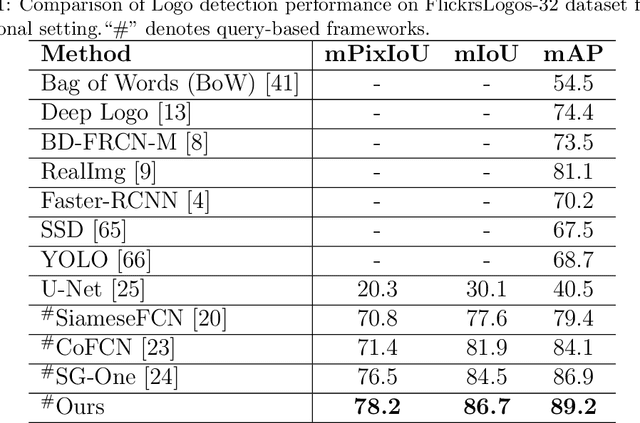
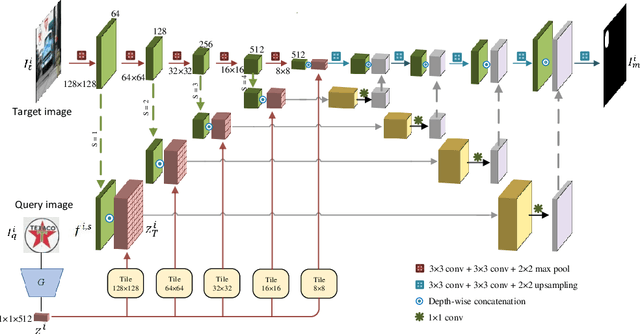
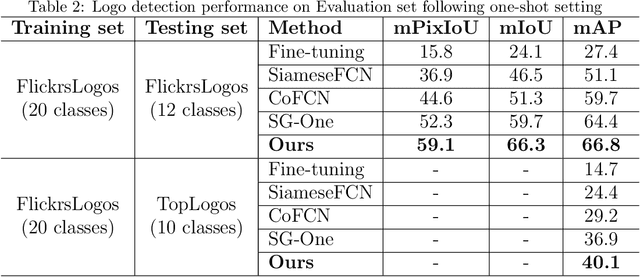
Logo detection in real-world scene images is an important problem with useful applications in advertisement and marketing. Existing general-purpose object detection methods require large training data with bounding box annotations for every logo class. These methods do not satisfy the incremental demand of logo classes necessary for practical deployment as it is practically impossible to have such paired data for every new unseen logo. In this work, we propose a query-based logo search and detection system by employing a one-shot learning technique. Given an image of a query logo, the model searches for it within a given target image and predicts the possible location of the logo by estimating a corresponding binary mask. The proposed model consists of a conditional branch and a segmentation branch. The former gives a conditional representation of a given query logo which is combined with the feature maps at multiple scales of the segmentation branch. The multi-scale conditioning allows our model to obtain a scale-invariant solution. Experimental results reveal that our model can be successfully adapted for any logo classes without separately training the whole network. Also, our query-based logo retrieval framework achieved superior performance in FlickrLogos-32 and TopLogos-10 dataset over existing baselines.
User Constrained Thumbnail Generation using Adaptive Convolutions
Nov 01, 2018


Thumbnails are widely used all over the world as a preview for digital images. In this work we propose a deep neural framework to generate thumbnails of any size and aspect ratio, even for unseen values during training, with high accuracy and precision. We use Global Context Aggregation (GCA) and a modified Region Proposal Network (RPN) with adaptive convolutions to generate thumbnails in real time. GCA is used to selectively attend and aggregate the global context information from the entire image while the RPN is used to predict candidate bounding boxes for the thumbnail image. Adaptive convolution eliminates the problem of generating thumbnails of various aspect ratios by using filter weights dynamically generated from the aspect ratio information. The experimental results indicate the superior performance of the proposed model over existing state-of-the-art techniques.
Cogni-Net: Cognitive Feature Learning through Deep Visual Perception
Nov 01, 2018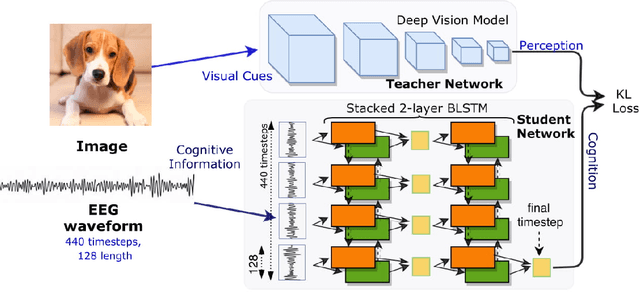

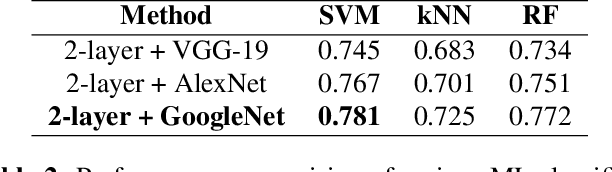
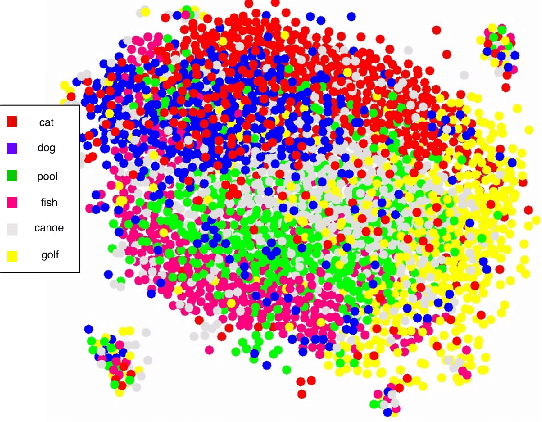
Can we ask computers to recognize what we see from brain signals alone? Our paper seeks to utilize the knowledge learnt in the visual domain by popular pre-trained vision models and use it to teach a recurrent model being trained on brain signals to learn a discriminative manifold of the human brain's cognition of different visual object categories in response to perceived visual cues. For this we make use of brain EEG signals triggered from visual stimuli like images and leverage the natural synchronization between images and their corresponding brain signals to learn a novel representation of the cognitive feature space. The concept of knowledge distillation has been used here for training the deep cognition model, CogniNet\footnote{The source code of the proposed system is publicly available at {https://www.github.com/53X/CogniNET}}, by employing a student-teacher learning technique in order to bridge the process of inter-modal knowledge transfer. The proposed novel architecture obtains state-of-the-art results, significantly surpassing other existing models. The experiments performed by us also suggest that if visual stimuli information like brain EEG signals can be gathered on a large scale, then that would help to obtain a better understanding of the largely unexplored domain of human brain cognition.
Improving Document Binarization via Adversarial Noise-Texture Augmentation
Oct 25, 2018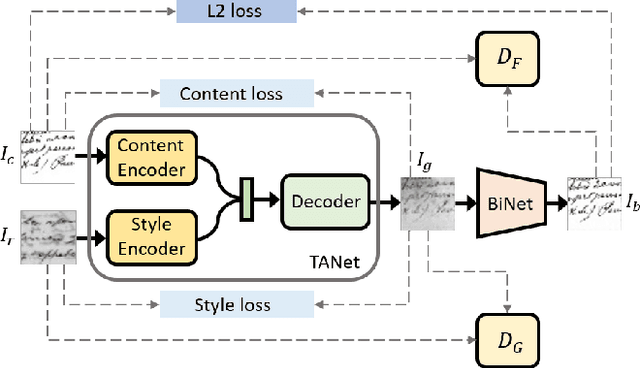
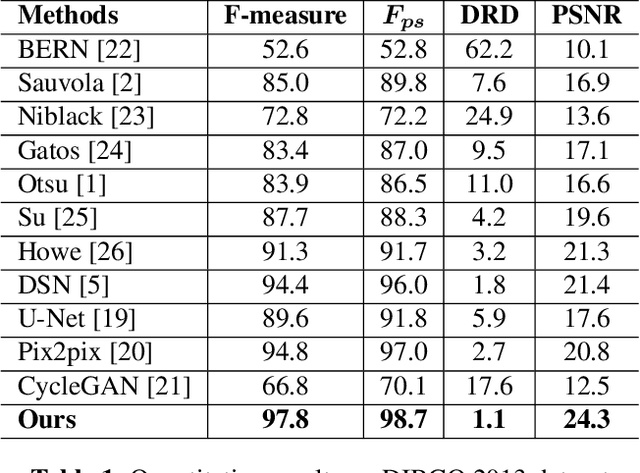


Binarization of degraded document images is an elementary step in most of the problems in document image analysis domain. The paper re-visits the binarization problem by introducing an adversarial learning approach. We construct a Texture Augmentation Network that transfers the texture element of a degraded reference document image to a clean binary image. In this way, the network creates multiple versions of the same textual content with various noisy textures, thus enlarging the available document binarization datasets. At last, the newly generated images are passed through a Binarization network to get back the clean version. By jointly training the two networks we can increase the adversarial robustness of our system. Also, it is noteworthy that our model can learn from unpaired data. Experimental results suggest that the proposed method achieves superior performance over widely used DIBCO datasets.
Script Identification in Natural Scene Image and Video Frame using Attention based Convolutional-LSTM Network
Aug 07, 2018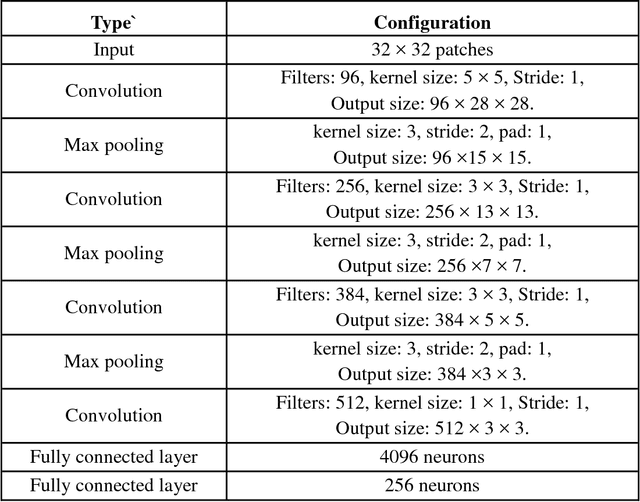
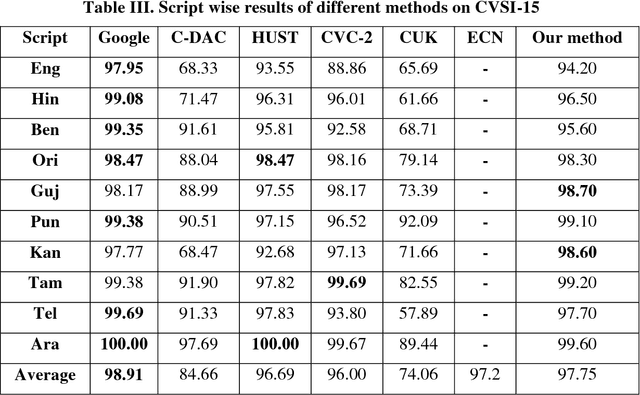
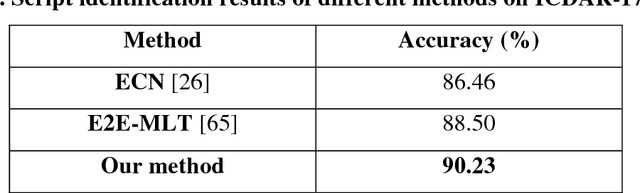
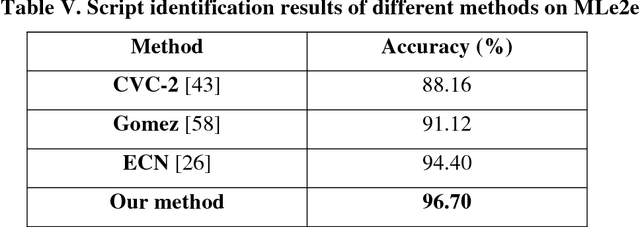
Script identification plays a significant role in analysing documents and videos. In this paper, we focus on the problem of script identification in scene text images and video scripts. Because of low image quality, complex background and similar layout of characters shared by some scripts like Greek, Latin, etc., text recognition in those cases become challenging. In this paper, we propose a novel method that involves extraction of local and global features using CNN-LSTM framework and weighting them dynamically for script identification. First, we convert the images into patches and feed them into a CNN-LSTM framework. Attention-based patch weights are calculated applying softmax layer after LSTM. Next, we do patch-wise multiplication of these weights with corresponding CNN to yield local features. Global features are also extracted from last cell state of LSTM. We employ a fusion technique which dynamically weights the local and global features for an individual patch. Experiments have been done in four public script identification datasets: SIW-13, CVSI2015, ICDAR-17 and MLe2e. The proposed framework achieves superior results in comparison to conventional methods.
Word Searching in Scene Image and Video Frame in Multi-Script Scenario using Dynamic Shape Coding
Jul 30, 2018
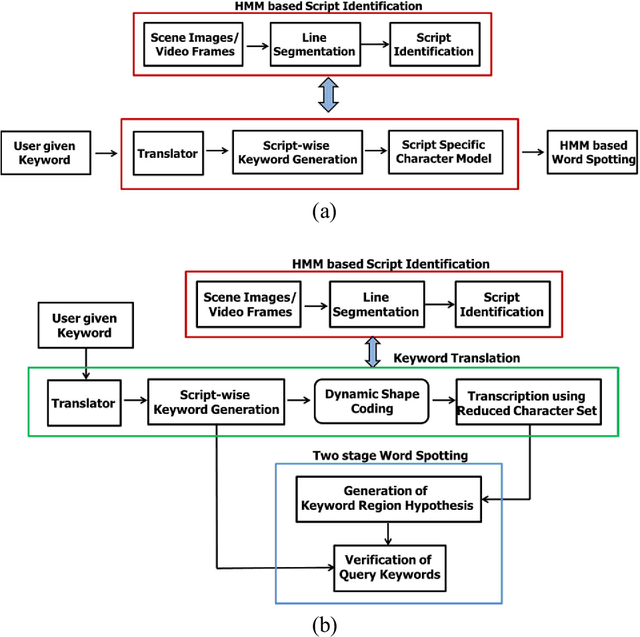
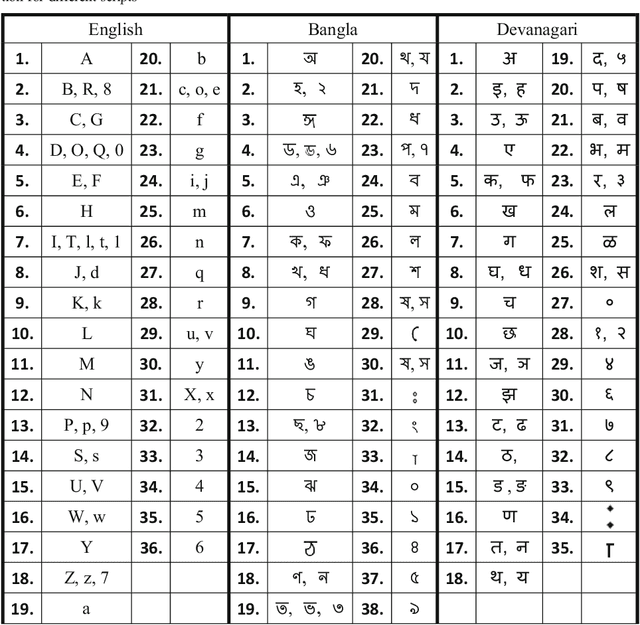
Retrieval of text information from natural scene images and video frames is a challenging task due to its inherent problems like complex character shapes, low resolution, background noise, etc. Available OCR systems often fail to retrieve such information in scene/video frames. Keyword spotting, an alternative way to retrieve information, performs efficient text searching in such scenarios. However, current word spotting techniques in scene/video images are script-specific and they are mainly developed for Latin script. This paper presents a novel word spotting framework using dynamic shape coding for text retrieval in natural scene image and video frames. The framework is designed to search query keyword from multiple scripts with the help of on-the-fly script-wise keyword generation for the corresponding script. We have used a two-stage word spotting approach using Hidden Markov Model (HMM) to detect the translated keyword in a given text line by identifying the script of the line. A novel unsupervised dynamic shape coding based scheme has been used to group similar shape characters to avoid confusion and to improve text alignment. Next, the hypotheses locations are verified to improve retrieval performance. To evaluate the proposed system for searching keyword from natural scene image and video frames, we have considered two popular Indic scripts such as Bangla (Bengali) and Devanagari along with English. Inspired by the zone-wise recognition approach in Indic scripts[1], zone-wise text information has been used to improve the traditional word spotting performance in Indic scripts. For our experiment, a dataset consisting of images of different scenes and video frames of English, Bangla and Devanagari scripts were considered. The results obtained showed the effectiveness of our proposed word spotting approach.