 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Reinforcement Learning with Finite Training Tasks -- a Density Estimation Approach
Jun 21, 2022
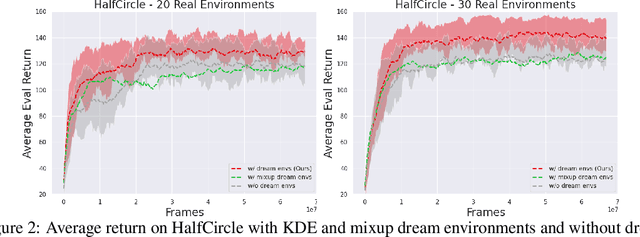
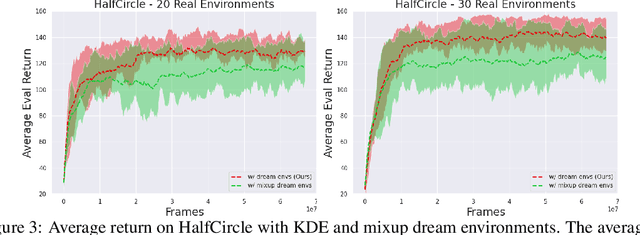
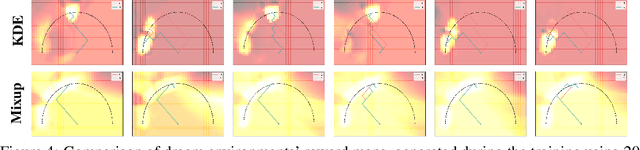
In meta reinforcement learning (meta RL), an agent learns from a set of training tasks how to quickly solve a new task, drawn from the same task distribution. The optimal meta RL policy, a.k.a. the Bayes-optimal behavior, is well defined, and guarantees optimal reward in expectation, taken with respect to the task distribution. The question we explore in this work is how many training tasks are required to guarantee approximately optimal behavior with high probability. Recent work provided the first such PAC analysis for a model-free setting, where a history-dependent policy was learned from the training tasks. In this work, we propose a different approach: directly learn the task distribution, using density estimation techniques, and then train a policy on the learned task distribution. We show that our approach leads to bounds that depend on the dimension of the task distribution. In particular, in settings where the task distribution lies in a low-dimensional manifold, we extend our analysis to use dimensionality reduction techniques and account for such structure, obtaining significantly better bounds than previous work, which strictly depend on the number of states and actions. The key of our approach is the regularization implied by the kernel density estimation method. We further demonstrate that this regularization is useful in practice, when `plugged in' the state-of-the-art VariBAD meta RL algorithm.
Unsupervised Image Representation Learning with Deep Latent Particles
May 31, 2022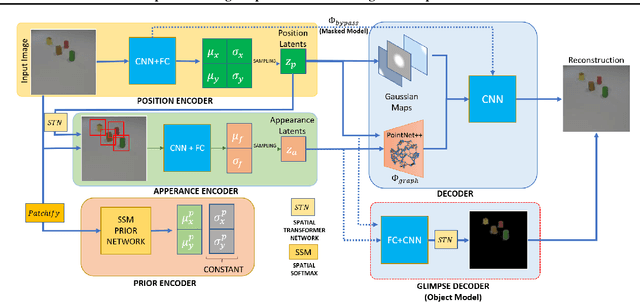
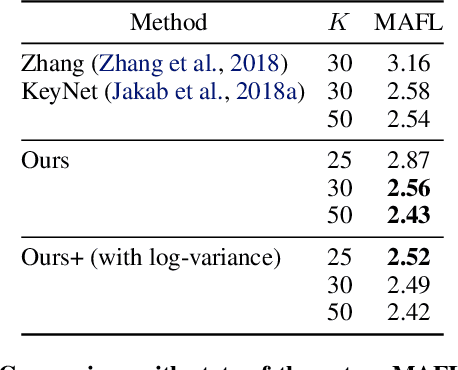


We propose a new representation of visual data that disentangles object position from appearance. Our method, termed Deep Latent Particles (DLP), decomposes the visual input into low-dimensional latent ``particles'', where each particle is described by its spatial location and features of its surrounding region. To drive learning of such representations, we follow a VAE-based approach and introduce a prior for particle positions based on a spatial-softmax architecture, and a modification of the evidence lower bound loss inspired by the Chamfer distance between particles. We demonstrate that our DLP representations are useful for downstream tasks such as unsupervised keypoint (KP) detection, image manipulation, and video prediction for scenes composed of multiple dynamic objects. In addition, we show that our probabilistic interpretation of the problem naturally provides uncertainty estimates for particle locations, which can be used for model selection, among other tasks. Videos and code are available: https://taldatech.github.io/deep-latent-particles-web/
Validate on Sim, Detect on Real -- Model Selection for Domain Randomization
Dec 01, 2021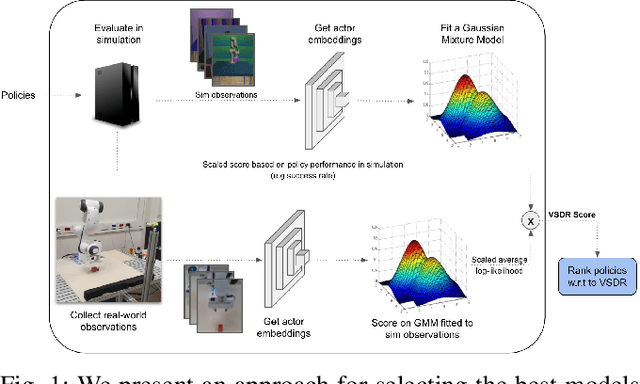
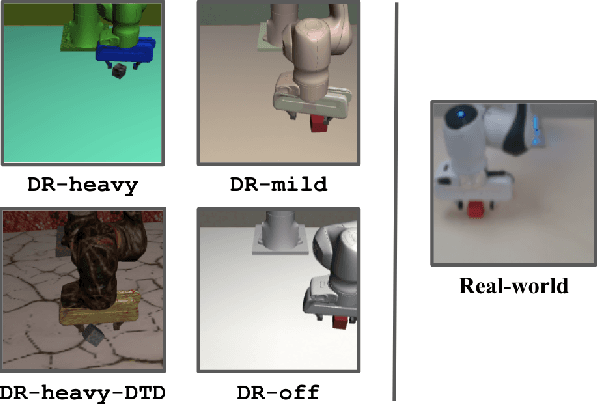
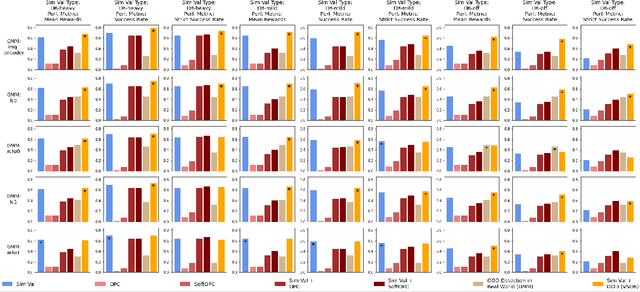
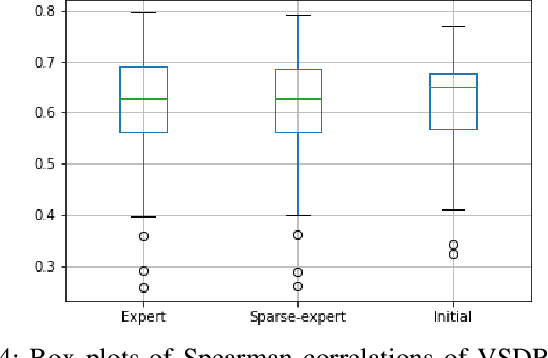
A practical approach to learning robot skills, often termed sim2real, is to train control policies in simulation and then deploy them on a real robot. Popular techniques to improve the sim2real transfer build on domain randomization (DR): Training the policy on a diverse set of randomly generated domains with the hope of better generalization to the real world. Due to the large number of hyper-parameters in both the policy learning and DR algorithms, one often ends up with a large number of trained models, where choosing the best model among them demands costly evaluation on the real robot. In this work we ask: Can we rank the policies without running them in the real world? Our main idea is that a predefined set of real world data can be used to evaluate all policies, using out-of-distribution detection (OOD) techniques. In a sense, this approach can be seen as a "unit test" to evaluate policies before any real world execution. However, we find that by itself, the OOD score can be inaccurate and very sensitive to the particular OOD method. Our main contribution is a simple-yet-effective policy score that combines OOD with an evaluation in simulation. We show that our score - VSDR - can significantly improve the accuracy of policy ranking without requiring additional real world data. We evaluate the effectiveness of VSDR on sim2real transfer in a robotic grasping task with image inputs. We extensively evaluate different DR parameters and OOD methods, and show that VSDR improves policy selection across the board. More importantly, our method achieves significantly better ranking, and uses significantly less data compared to baselines.
Regularization Guarantees Generalization in Bayesian Reinforcement Learning through Algorithmic Stability
Sep 24, 2021In the Bayesian reinforcement learning (RL) setting, a prior distribution over the unknown problem parameters -- the rewards and transitions -- is assumed, and a policy that optimizes the (posterior) expected return is sought. A common approximation, which has been recently popularized as meta-RL, is to train the agent on a sample of $N$ problem instances from the prior, with the hope that for large enough $N$, good generalization behavior to an unseen test instance will be obtained. In this work, we study generalization in Bayesian RL under the probably approximately correct (PAC) framework, using the method of algorithmic stability. Our main contribution is showing that by adding regularization, the optimal policy becomes stable in an appropriate sense. Most stability results in the literature build on strong convexity of the regularized loss -- an approach that is not suitable for RL as Markov decision processes (MDPs) are not convex. Instead, building on recent results of fast convergence rates for mirror descent in regularized MDPs, we show that regularized MDPs satisfy a certain quadratic growth criterion, which is sufficient to establish stability. This result, which may be of independent interest, allows us to study the effect of regularization on generalization in the Bayesian RL setting.
Efficient Self-Supervised Data Collection for Offline Robot Learning
May 10, 2021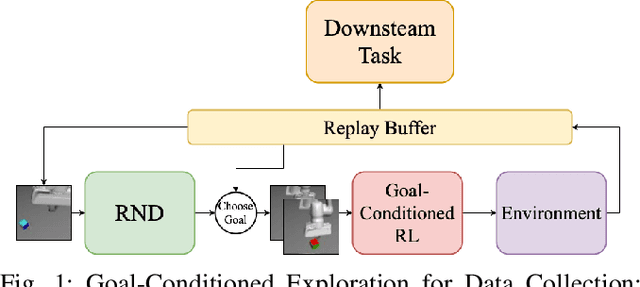

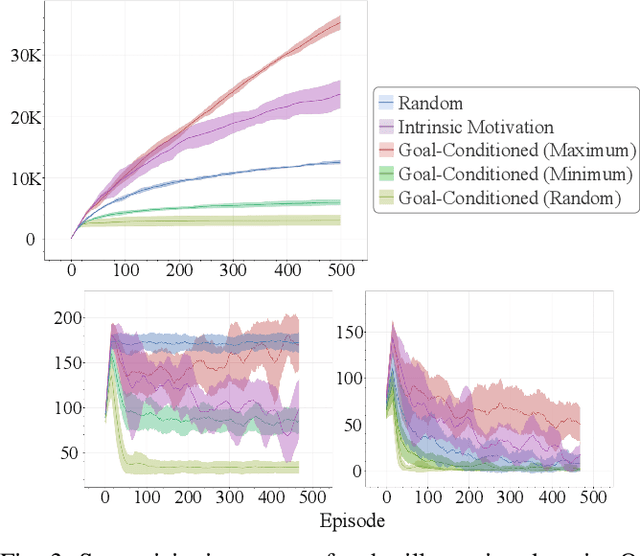

A practical approach to robot reinforcement learning is to first collect a large batch of real or simulated robot interaction data, using some data collection policy, and then learn from this data to perform various tasks, using offline learning algorithms. Previous work focused on manually designing the data collection policy, and on tasks where suitable policies can easily be designed, such as random picking policies for collecting data about object grasping. For more complex tasks, however, it may be difficult to find a data collection policy that explores the environment effectively, and produces data that is diverse enough for the downstream task. In this work, we propose that data collection policies should actively explore the environment to collect diverse data. In particular, we develop a simple-yet-effective goal-conditioned reinforcement-learning method that actively focuses data collection on novel observations, thereby collecting a diverse data-set. We evaluate our method on simulated robot manipulation tasks with visual inputs and show that the improved diversity of active data collection leads to significant improvements in the downstream learning tasks.
Unsupervised Feature Learning for Manipulation with Contrastive Domain Randomization
Mar 20, 2021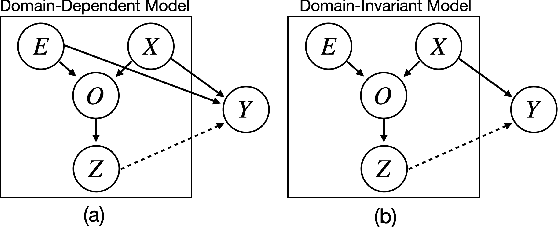
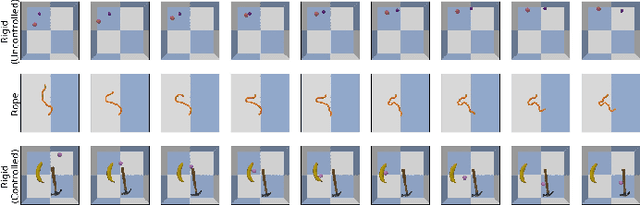

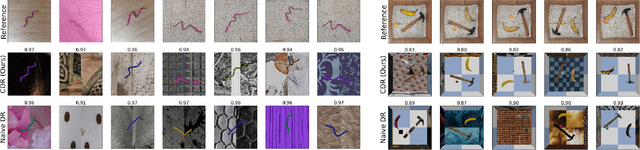
Robotic tasks such as manipulation with visual inputs require image features that capture the physical properties of the scene, e.g., the position and configuration of objects. Recently, it has been suggested to learn such features in an unsupervised manner from simulated, self-supervised, robot interaction; the idea being that high-level physical properties are well captured by modern physical simulators, and their representation from visual inputs may transfer well to the real world. In particular, learning methods based on noise contrastive estimation have shown promising results. To robustify the simulation-to-real transfer, domain randomization (DR) was suggested for learning features that are invariant to irrelevant visual properties such as textures or lighting. In this work, however, we show that a naive application of DR to unsupervised learning based on contrastive estimation does not promote invariance, as the loss function maximizes mutual information between the features and both the relevant and irrelevant visual properties. We propose a simple modification of the contrastive loss to fix this, exploiting the fact that we can control the simulated randomization of visual properties. Our approach learns physical features that are significantly more robust to visual domain variation, as we demonstrate using both rigid and non-rigid objects.
Soft-IntroVAE: Analyzing and Improving the Introspective Variational Autoencoder
Dec 24, 2020

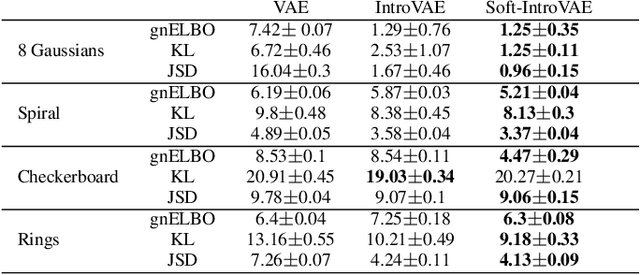
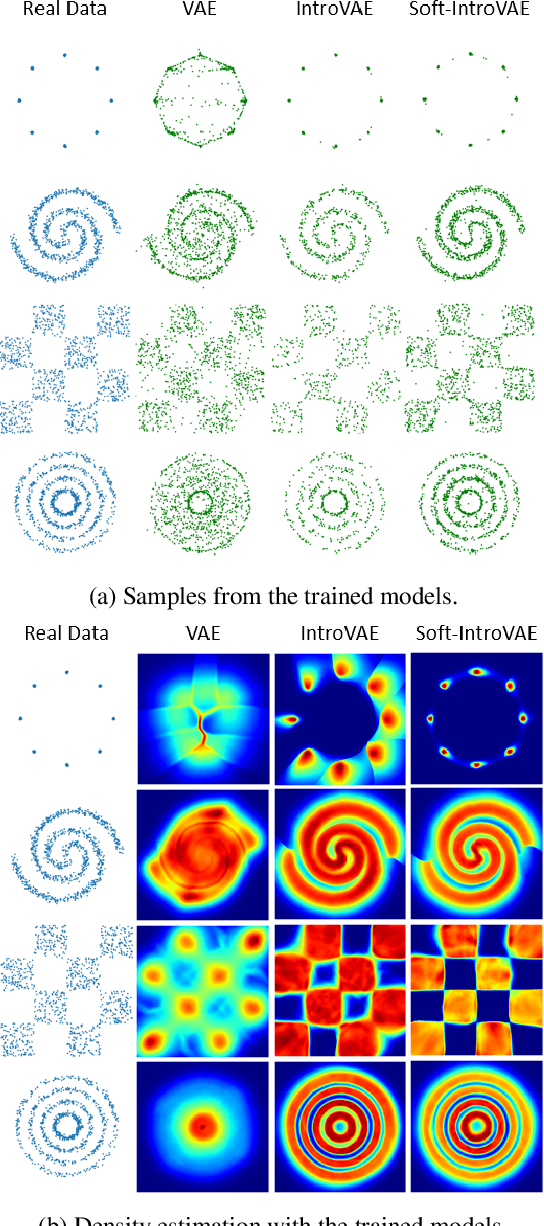
The recently introduced introspective variational autoencoder (IntroVAE) exhibits outstanding image generations, and allows for amortized inference using an image encoder. The main idea in IntroVAE is to train a VAE adversarially, using the VAE encoder to discriminate between generated and real data samples. However, the original IntroVAE loss function relied on a particular hinge-loss formulation that is very hard to stabilize in practice, and its theoretical convergence analysis ignored important terms in the loss. In this work, we take a step towards better understanding of the IntroVAE model, its practical implementation, and its applications. We propose the Soft-IntroVAE, a modified IntroVAE that replaces the hinge-loss terms with a smooth exponential loss on generated samples. This change significantly improves training stability, and also enables theoretical analysis of the complete algorithm. Interestingly, we show that the IntroVAE converges to a distribution that minimizes a sum of KL distance from the data distribution and an entropy term. We discuss the implications of this result, and demonstrate that it induces competitive image generation and reconstruction. Finally, we describe two applications of Soft-IntroVAE to unsupervised image translation and out-of-distribution detection, and demonstrate compelling results. Code and additional information is available on the project website -- https://taldatech.github.io/soft-intro-vae-web
Online Safety Assurance for Deep Reinforcement Learning
Oct 07, 2020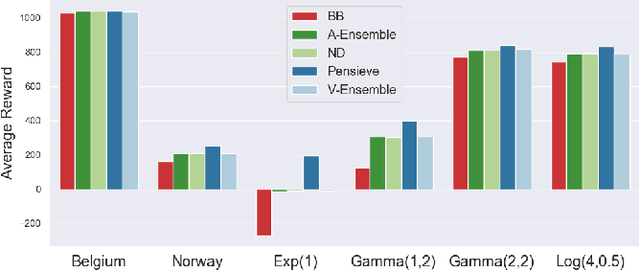
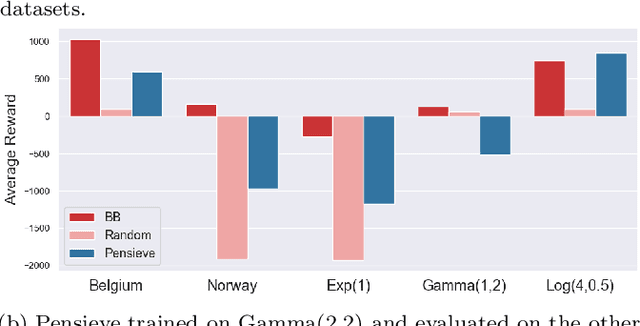
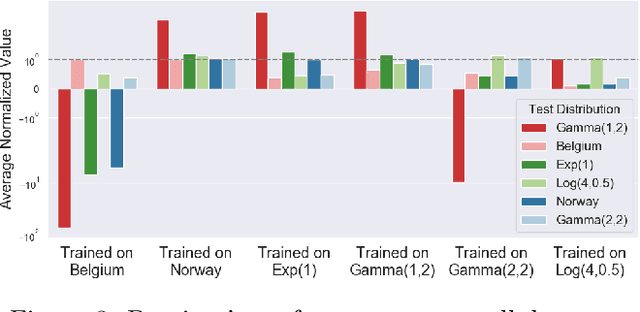
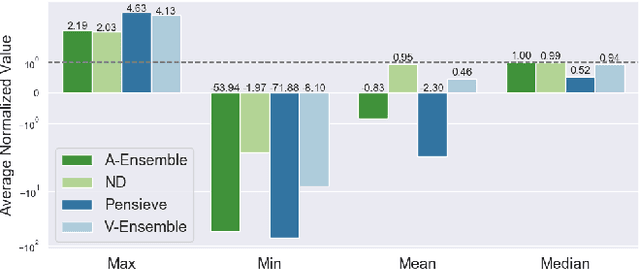
Recently, deep learning has been successfully applied to a variety of networking problems. A fundamental challenge is that when the operational environment for a learning-augmented system differs from its training environment, such systems often make badly informed decisions, leading to bad performance. We argue that safely deploying learning-driven systems requires being able to determine, in real time, whether system behavior is coherent, for the purpose of defaulting to a reasonable heuristic when this is not so. We term this the online safety assurance problem (OSAP). We present three approaches to quantifying decision uncertainty that differ in terms of the signal used to infer uncertainty. We illustrate the usefulness of online safety assurance in the context of the proposed deep reinforcement learning (RL) approach to video streaming. While deep RL for video streaming bests other approaches when the operational and training environments match, it is dominated by simple heuristics when the two differ. Our preliminary findings suggest that transitioning to a default policy when decision uncertainty is detected is key to enjoying the performance benefits afforded by leveraging ML without compromising on safety.
Robust 2D Assembly Sequencing via Geometric Planning with Learned Scores
Sep 20, 2020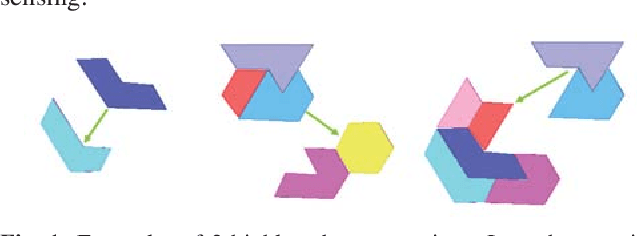
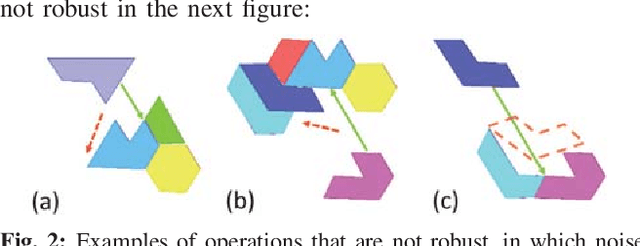
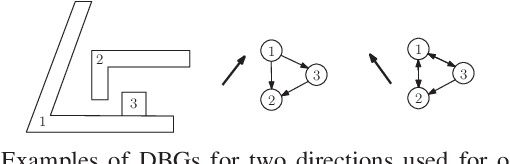
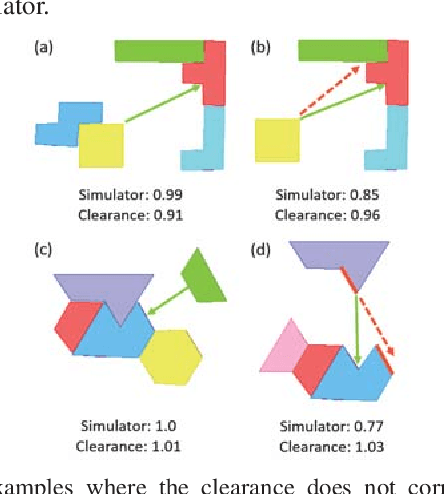
To compute robust 2D assembly plans, we present an approach that combines geometric planning with a deep neural network. We train the network using the Box2D physics simulator with added stochastic noise to yield robustness scores--the success probabilities of planned assembly motions. As running a simulation for every assembly motion is impractical, we train a convolutional neural network to map assembly operations, given as an image pair of the subassemblies before and after they are mated, to a robustness score. The neural network prediction is used within a planner to quickly prune out motions that are not robust. We demonstrate this approach on two-handed planar assemblies, where the motions are one-step translations. Results suggest that the neural network can learn robustness to plan robust sequences an order of magnitude faster than physics simulation.
Offline Meta Reinforcement Learning
Aug 06, 2020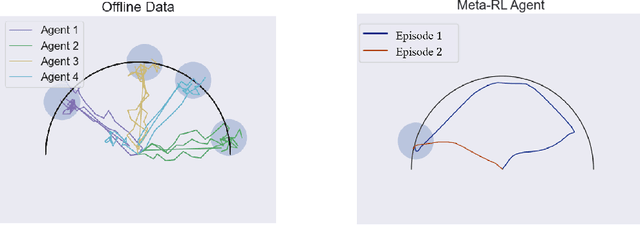


Consider the following problem, which we term Offline Meta Reinforcement Learning (OMRL): given the complete training histories of $N$ conventional RL agents, trained on $N$ different tasks, design a learning agent that can quickly maximize reward in a new, unseen task from the same task distribution. In particular, while each conventional RL agent explored and exploited its own different task, the OMRL agent must identify regularities in the data that lead to effective exploration/exploitation in the unseen task. To solve OMRL, we take a Bayesian RL (BRL) view, and seek to learn a Bayes-optimal policy from the offline data. We extend the recently proposed VariBAD BRL algorithm to the off-policy setting, and demonstrate learning of Bayes-optimal exploration strategies from offline data using deep neural networks. Furthermore, when applied to the online meta-RL setting (agent simultaneously collects data and improves its meta-RL policy), our method is significantly more sample efficient than the conventional VariBAD.