 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvishek Ghosh
Escaping Saddle Points in Distributed Newton's Method with Communication efficiency and Byzantine Resilience
Mar 17, 2021
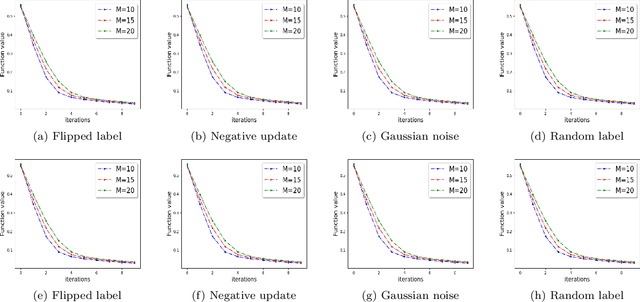

We study the problem of optimizing a non-convex loss function (with saddle points) in a distributed framework in the presence of Byzantine machines. We consider a standard distributed setting with one central machine (parameter server) communicating with many worker machines. Our proposed algorithm is a variant of the celebrated cubic-regularized Newton method of Nesterov and Polyak \cite{nest}, which avoids saddle points efficiently and converges to local minima. Furthermore, our algorithm resists the presence of Byzantine machines, which may create \emph{fake local minima} near the saddle points of the loss function, also known as saddle-point attack. We robustify the cubic-regularized Newton algorithm such that it avoids the saddle points and the fake local minimas efficiently. Furthermore, being a second order algorithm, the iteration complexity is much lower than its first order counterparts, and thus our algorithm communicates little with the parameter server. We obtain theoretical guarantees for our proposed scheme under several settings including approximate (sub-sampled) gradients and Hessians. Moreover, we validate our theoretical findings with experiments using standard datasets and several types of Byzantine attacks.
Distributed Newton Can Communicate Less and Resist Byzantine Workers
Jun 15, 2020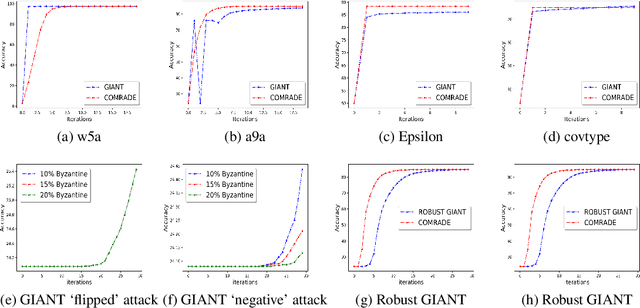
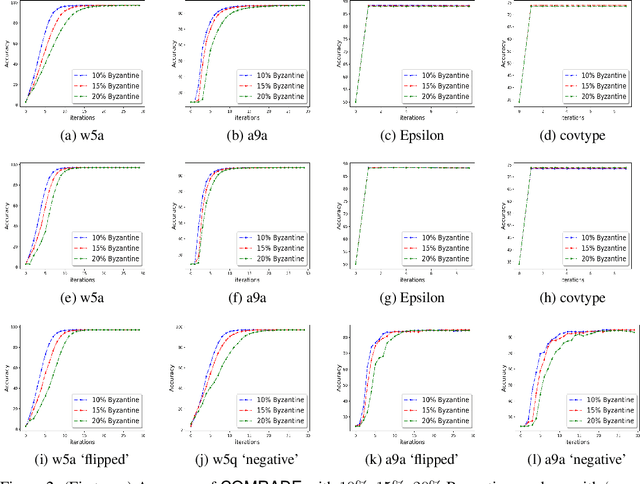
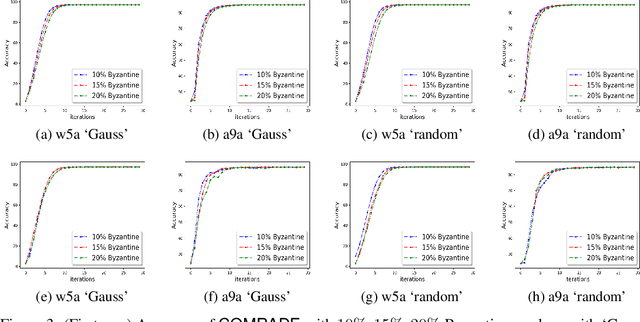
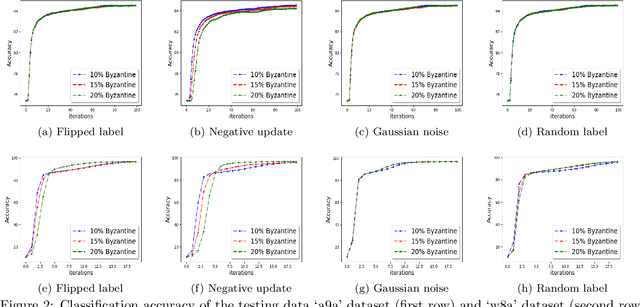
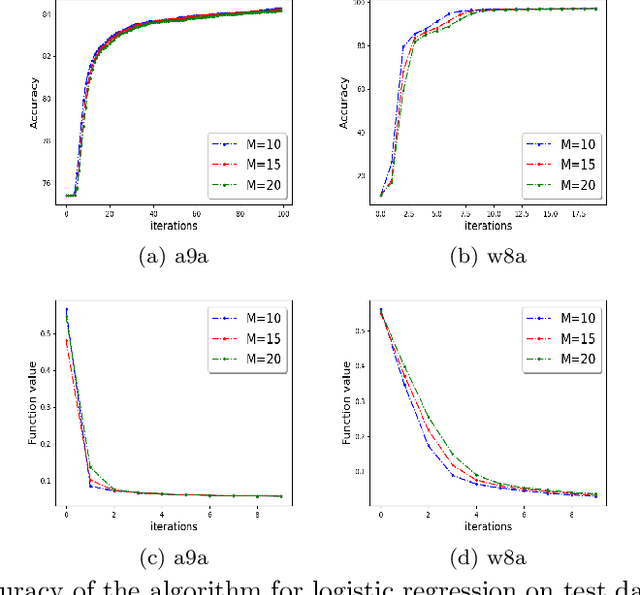
We develop a distributed second order optimization algorithm that is communication-efficient as well as robust against Byzantine failures of the worker machines. We propose COMRADE (COMunication-efficient and Robust Approximate Distributed nEwton), an iterative second order algorithm, where the worker machines communicate only once per iteration with the center machine. This is in sharp contrast with the state-of-the-art distributed second order algorithms like GIANT [34] and DINGO[7], where the worker machines send (functions of) local gradient and Hessian sequentially; thus ending up communicating twice with the center machine per iteration. Moreover, we show that the worker machines can further compress the local information before sending it to the center. In addition, we employ a simple norm based thresholding rule to filter-out the Byzantine worker machines. We establish the linear-quadratic rate of convergence of COMRADE and establish that the communication savings and Byzantine resilience result in only a small statistical error rate for arbitrary convex loss functions. To the best of our knowledge, this is the first work that addresses the issue of Byzantine resilience in second order distributed optimization. Furthermore, we validate our theoretical results with extensive experiments on synthetic and benchmark LIBSVM [5] data-sets and demonstrate convergence guarantees.
Problem-Complexity Adaptive Model Selection for Stochastic Linear Bandits
Jun 15, 2020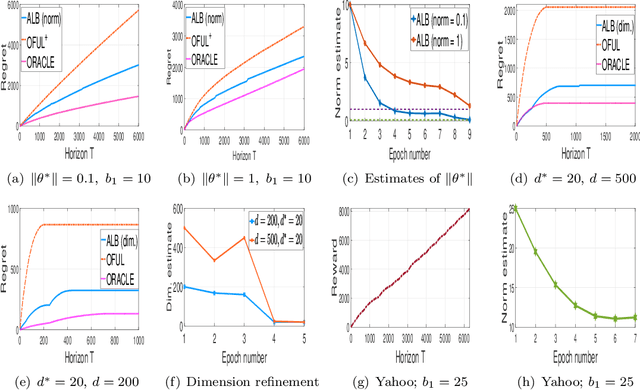
We consider the problem of model selection for two popular stochastic linear bandit settings, and propose algorithms that adapts to the unknown problem complexity. In the first setting, we consider the $K$ armed mixture bandits, where the mean reward of arm $i \in [K]$, is $\mu_i+ \langle \alpha_{i,t},\theta^* \rangle $, with $\alpha_{i,t} \in \mathbb{R}^d$ being the known context vector and $\mu_i \in [-1,1]$ and $\theta^*$ are unknown parameters. We define $\|\theta^*\|$ as the problem complexity and consider a sequence of nested hypothesis classes, each positing a different upper bound on $\|\theta^*\|$. Exploiting this, we propose Adaptive Linear Bandit (ALB), a novel phase based algorithm that adapts to the true problem complexity, $\|\theta^*\|$. We show that ALB achieves regret scaling of $O(\|\theta^*\|\sqrt{T})$, where $\|\theta^*\|$ is apriori unknown. As a corollary, when $\theta^*=0$, ALB recovers the minimax regret for the simple bandit algorithm without such knowledge of $\theta^*$. ALB is the first algorithm that uses parameter norm as model section criteria for linear bandits. Prior state of art algorithms \cite{osom} achieve a regret of $O(L\sqrt{T})$, where $L$ is the upper bound on $\|\theta^*\|$, fed as an input to the problem. In the second setting, we consider the standard linear bandit problem (with possibly an infinite number of arms) where the sparsity of $\theta^*$, denoted by $d^* \leq d$, is unknown to the algorithm. Defining $d^*$ as the problem complexity, we show that ALB achieves $O(d^*\sqrt{T})$ regret, matching that of an oracle who knew the true sparsity level. This methodology is then extended to the case of finitely many arms and similar results are proven. This is the first algorithm that achieves such model selection guarantees. We further verify our results via synthetic and real-data experiments.
An Efficient Framework for Clustered Federated Learning
Jun 07, 2020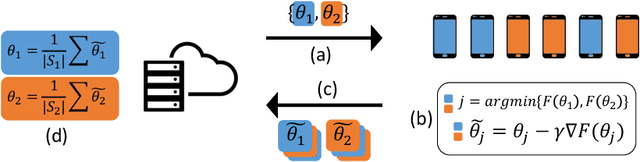

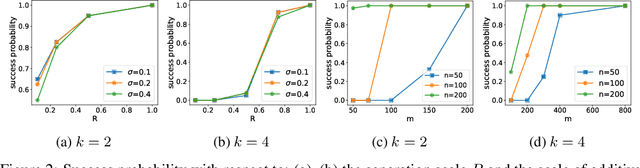
We address the problem of Federated Learning (FL) where users are distributed and partitioned into clusters. This setup captures settings where different groups of users have their own objectives (learning tasks) but by aggregating their data with others in the same cluster (same learning task), they can leverage the strength in numbers in order to perform more efficient Federated Learning. We propose a new framework dubbed the Iterative Federated Clustering Algorithm (IFCA), which alternately estimates the cluster identities of the users and optimizes model parameters for the user clusters via gradient descent. We analyze the convergence rate of this algorithm first in a linear model with squared loss and then for generic strongly convex and smooth loss functions. We show that in both settings, with good initialization, IFCA converges at an exponential rate, and discuss the optimality of the statistical error rate. In the experiments, we show that our algorithm can succeed even if we relax the requirements on initialization with random initialization and multiple restarts. We also present experimental results showing that our algorithm is efficient in non-convex problems such as neural networks and outperforms the baselines on several clustered FL benchmarks created based on the MNIST and CIFAR-10 datasets by $5\sim 8\%$.
Alternating Minimization Converges Super-Linearly for Mixed Linear Regression
Apr 23, 2020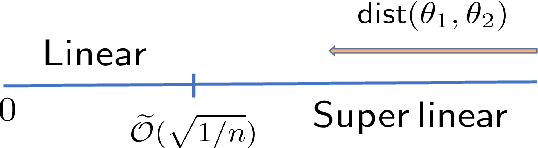
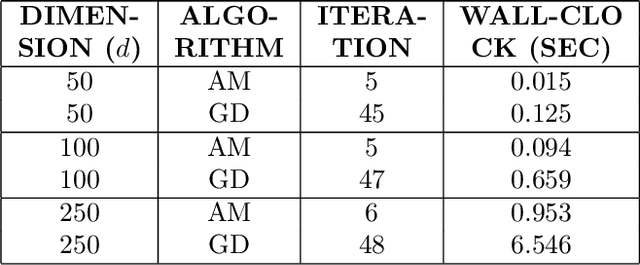
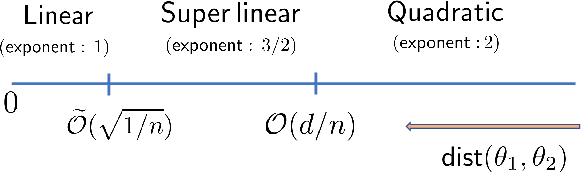
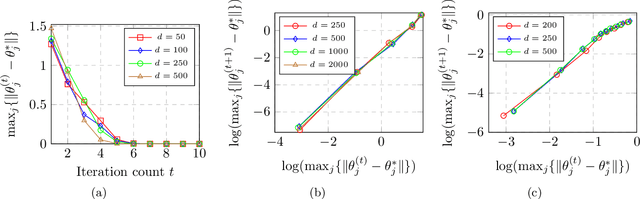
We address the problem of solving mixed random linear equations. We have unlabeled observations coming from multiple linear regressions, and each observation corresponds to exactly one of the regression models. The goal is to learn the linear regressors from the observations. Classically, Alternating Minimization (AM) (which is a variant of Expectation Maximization (EM)) is used to solve this problem. AM iteratively alternates between the estimation of labels and solving the regression problems with the estimated labels. Empirically, it is observed that, for a large variety of non-convex problems including mixed linear regression, AM converges at a much faster rate compared to gradient based algorithms. However, the existing theory suggests similar rate of convergence for AM and gradient based methods, failing to capture this empirical behavior. In this paper, we close this gap between theory and practice for the special case of a mixture of $2$ linear regressions. We show that, provided initialized properly, AM enjoys a \emph{super-linear} rate of convergence in certain parameter regimes. To the best of our knowledge, this is the first work that theoretically establishes such rate for AM. Hence, if we want to recover the unknown regressors upto an error (in $\ell_2$ norm) of $\epsilon$, AM only takes $\mathcal{O}(\log \log (1/\epsilon))$ iterations. Furthermore, we compare AM with a gradient based heuristic algorithm empirically and show that AM dominates in iteration complexity as well as wall-clock time.
Communication-Efficient and Byzantine-Robust Distributed Learning
Nov 21, 2019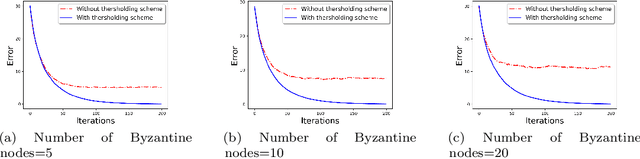
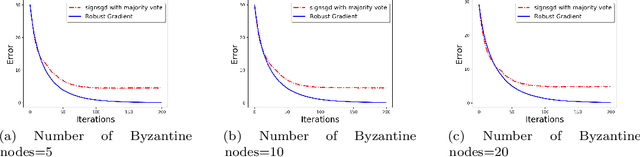
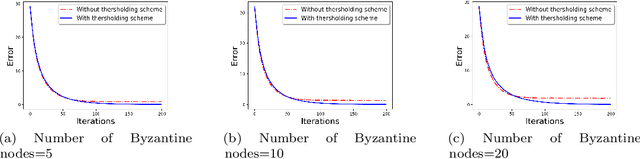
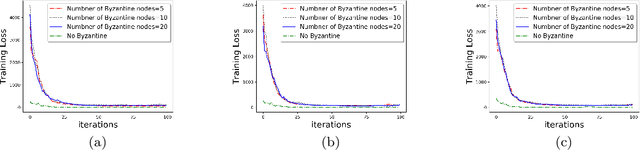
We develop a communication-efficient distributed learning algorithm that is robust against Byzantine worker machines. We propose and analyze a distributed gradient-descent algorithm that performs a simple thresholding based on gradient norms to mitigate Byzantine failures. We show the (statistical) error-rate of our algorithm matches that of [YCKB18], which uses more complicated schemes (like coordinate-wise median or trimmed mean) and thus optimal. Furthermore, for communication efficiency, we consider a generic class of {\delta}-approximate compressors from [KRSJ19] that encompasses sign-based compressors and top-k sparsification. Our algorithm uses compressed gradients and gradient norms for aggregation and Byzantine removal respectively. We establish the statistical error rate of the algorithm for arbitrary (convex or non-convex) smooth loss function. We show that, in the regime when the compression factor {\delta} is constant and the dimension of the parameter space is fixed, the rate of convergence is not affected by the compression operation, and hence we effectively get the compression for free. Moreover, we extend the compressed gradient descent algorithm with error feedback proposed in [KRSJ19] for the distributed setting. We have experimentally validated our results and shown good performance in convergence for convex (least-square regression) and non-convex (neural network training) problems.
Max-Affine Regression: Provable, Tractable, and Near-Optimal Statistical Estimation
Jun 21, 2019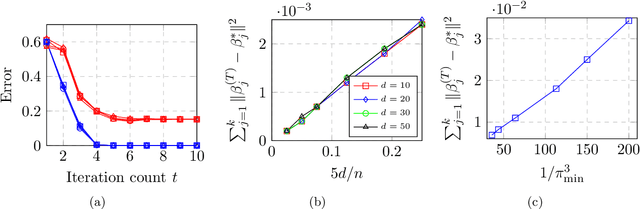
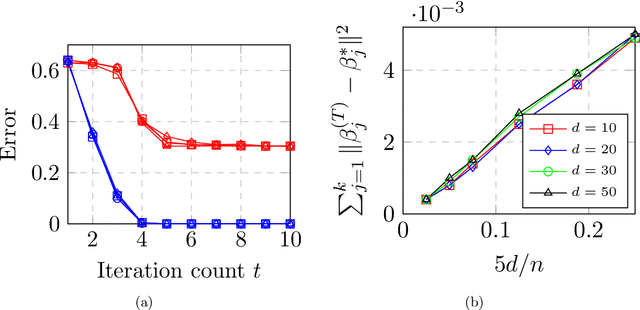
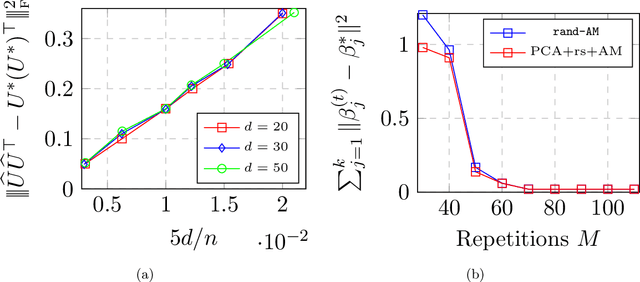
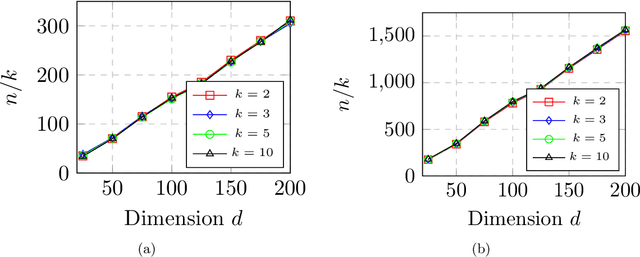
Max-affine regression refers to a model where the unknown regression function is modeled as a maximum of $k$ unknown affine functions for a fixed $k \geq 1$. This generalizes linear regression and (real) phase retrieval, and is closely related to convex regression. Working within a non-asymptotic framework, we study this problem in the high-dimensional setting assuming that $k$ is a fixed constant, and focus on estimation of the unknown coefficients of the affine functions underlying the model. We analyze a natural alternating minimization (AM) algorithm for the non-convex least squares objective when the design is random. We show that the AM algorithm, when initialized suitably, converges with high probability and at a geometric rate to a small ball around the optimal coefficients. In order to initialize the algorithm, we propose and analyze a combination of a spectral method and a random search scheme in a low-dimensional space, which may be of independent interest. The final rate that we obtain is near-parametric and minimax optimal (up to a poly-logarithmic factor) as a function of the dimension, sample size, and noise variance. In that sense, our approach should be viewed as a direct and implementable method of enforcing regularization to alleviate the curse of dimensionality in problems of the convex regression type. As a by-product of our analysis, we also obtain guarantees on a classical algorithm for the phase retrieval problem under considerably weaker assumptions on the design distribution than was previously known. Numerical experiments illustrate the sharpness of our bounds in the various problem parameters.
Robust Federated Learning in a Heterogeneous Environment
Jun 16, 2019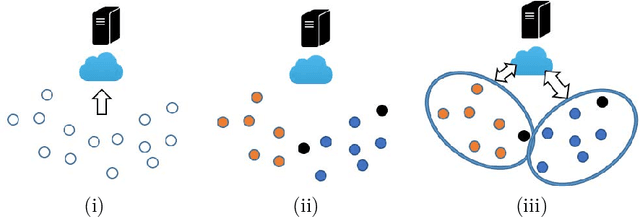
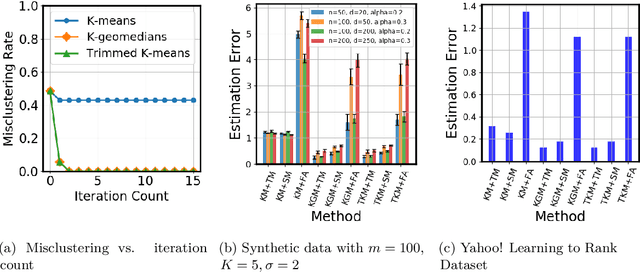
We study a recently proposed large-scale distributed learning paradigm, namely Federated Learning, where the worker machines are end users' own devices. Statistical and computational challenges arise in Federated Learning particularly in the presence of heterogeneous data distribution (i.e., data points on different devices belong to different distributions signifying different clusters) and Byzantine machines (i.e., machines that may behave abnormally, or even exhibit arbitrary and potentially adversarial behavior). To address the aforementioned challenges, first we propose a general statistical model for this problem which takes both the cluster structure of the users and the Byzantine machines into account. Then, leveraging the statistical model, we solve the robust heterogeneous Federated Learning problem \emph{optimally}; in particular our algorithm matches the lower bound on the estimation error in dimension and the number of data points. Furthermore, as a by-product, we prove statistical guarantees for an outlier-robust clustering algorithm, which can be considered as the Lloyd algorithm with robust estimation. Finally, we show via synthetic as well as real data experiments that the estimation error obtained by our proposed algorithm is significantly better than the non-Byzantine-robust algorithms; in particular, we gain at least by 53\% and 33\% for synthetic and real data experiments, respectively, in typical settings.
Online Scoring with Delayed Information: A Convex Optimization Viewpoint
Jul 09, 2018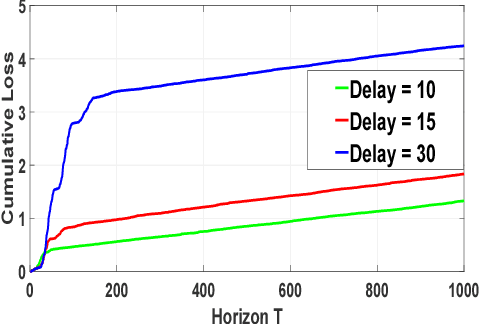
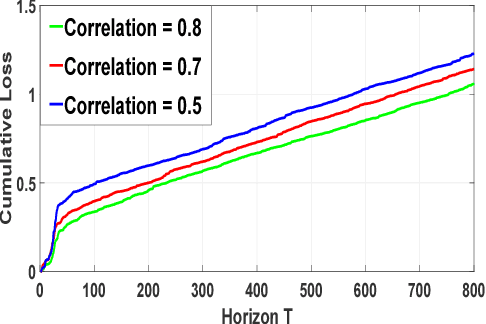
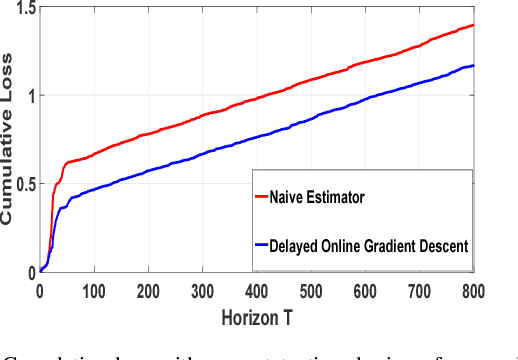
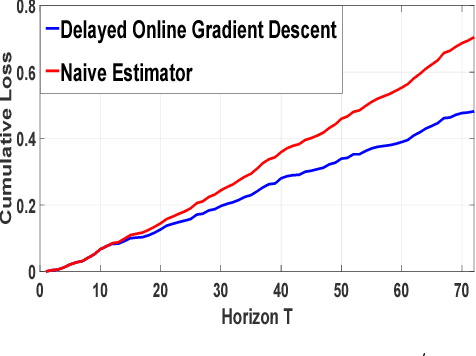
We consider a system where agents enter in an online fashion and are evaluated based on their attributes or context vectors. There can be practical situations where this context is partially observed, and the unobserved part comes after some delay. We assume that an agent, once left, cannot re-enter the system. Therefore, the job of the system is to provide an estimated score for the agent based on her instantaneous score and possibly some inference of the instantaneous score over the delayed score. In this paper, we estimate the delayed context via an online convex game between the agent and the system. We argue that the error in the score estimate accumulated over $T$ iterations is small if the regret of the online convex game is small. Further, we leverage side information about the delayed context in the form of a correlation function with the known context. We consider the settings where the delay is fixed or arbitrarily chosen by an adversary. Furthermore, we extend the formulation to the setting where the contexts are drawn from some Banach space. Overall, we show that the average penalty for not knowing the delayed context while making a decision scales with $\mathcal{O}(\frac{1}{\sqrt{T}})$, where this can be improved to $\mathcal{O}(\frac{\log T}{T})$ under special setting.