 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality
Dec 11, 2025We introduce The FACTS Leaderboard, an online leaderboard suite and associated set of benchmarks that comprehensively evaluates the ability of language models to generate factually accurate text across diverse scenarios. The suite provides a holistic measure of factuality by aggregating the performance of models on four distinct sub-leaderboards: (1) FACTS Multimodal, which measures the factuality of responses to image-based questions; (2) FACTS Parametric, which assesses models' world knowledge by answering closed-book factoid questions from internal parameters; (3) FACTS Search, which evaluates factuality in information-seeking scenarios, where the model must use a search API; and (4) FACTS Grounding (v2), which evaluates whether long-form responses are grounded in provided documents, featuring significantly improved judge models. Each sub-leaderboard employs automated judge models to score model responses, and the final suite score is an average of the four components, designed to provide a robust and balanced assessment of a model's overall factuality. The FACTS Leaderboard Suite will be actively maintained, containing both public and private splits to allow for external participation while guarding its integrity. It can be found at https://www.kaggle.com/benchmarks/google/facts .
Effective Metrics for Multi-Robot Motion-Planning
Dec 15, 2017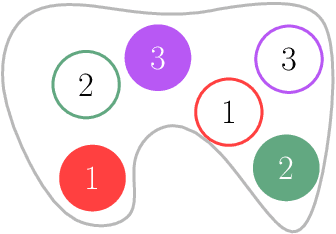
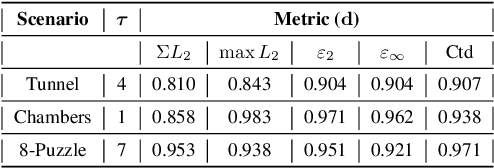
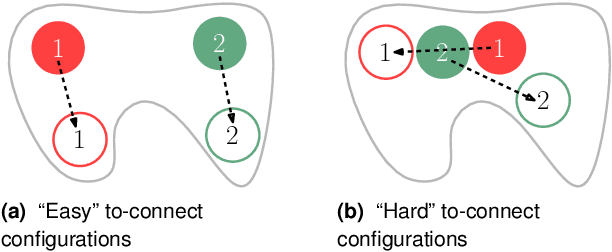
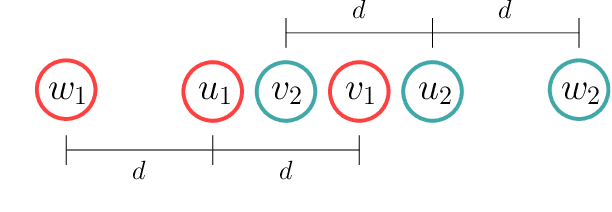
We study the effectiveness of metrics for Multi-Robot Motion-Planning (MRMP) when using RRT-style sampling-based planners. These metrics play the crucial role of determining the nearest neighbors of configurations and in that they regulate the connectivity of the underlying roadmaps produced by the planners and other properties like the quality of solution paths. After screening over a dozen different metrics we focus on the five most promising ones- two more traditional metrics, and three novel ones which we propose here, adapted from the domain of shape-matching. In addition to the novel multi-robot metrics, a central contribution of this work are tools to analyze and predict the effectiveness of metrics in the MRMP context. We identify a suite of possible substructures in the configuration space, for which it is fairly easy (i) to define a so-called natural distance which allows us to predict the performance of a metric. This is done by comparing the distribution of its values for sampled pairs of configurations to the distribution induced by the natural distance; (ii) to define equivalence classes of configurations and test how well a metric covers the different classes. We provide experiments that attest to the ability of our tools to predict the effectiveness of metrics: those metrics that qualify in the analysis yield higher success rate of the planner with fewer vertices in the roadmap. We also show how combining several metrics together leads to better results (success rate and size of roadmap) than using a single metric.