 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum-enhanced Large Language Models on Quantum Hardware via Cayley Unitary Adapters
May 07, 2026Large language models (LLMs) have transformed artificial intelligence, yet classical architectures impose a fundamental constraint: every trainable parameter demands classical memory that scales unfavourably with model size. Quantum computing offers a qualitatively different pathway, but practical demonstrations on real hardware have remained elusive for models of practical relevance. Here we show that Cayley-parameterised unitary adapters -- quantum circuit blocks inserted into the frozen projection layers of pre-trained LLMs and executed on a 156-qubit IBM Quantum System Two superconducting processor -- improve the perplexity of Llama 3.1 8B, an 8-billion-parameter model in widespread use, by 1.4% with only 6,000 additional parameters and end-to-end inference validated on real Quantum Processing Unit (QPU). A systematic study on SmolLM2 (135M parameters), chosen for its tractability, reveals monotonically improving perplexity with unitary block dimension, 83% recovery of compression-induced degradation, and correct answers to questions that both classical baselines fail -- with a sharp noise-expressivity phase transition identifying the concrete path to quantum utility at larger qubit scales.
Scalably learning quantum many-body Hamiltonians from dynamical data
Sep 28, 2022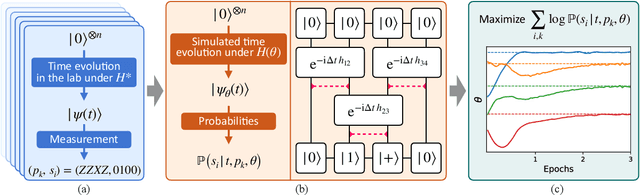
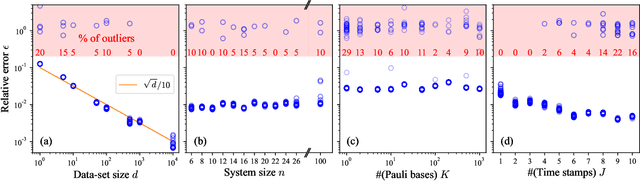
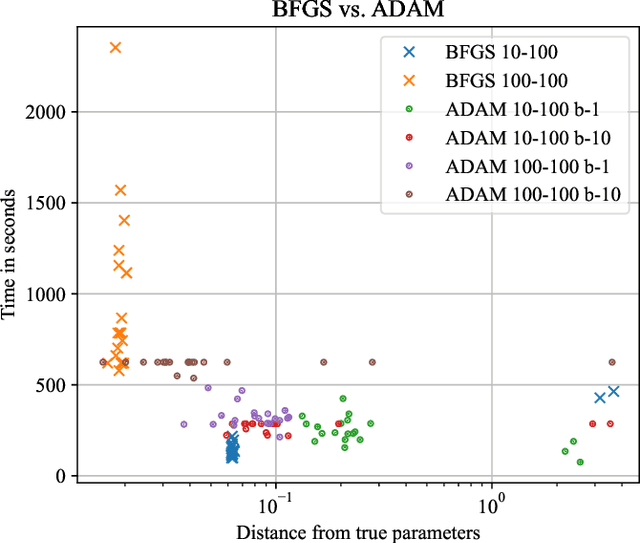
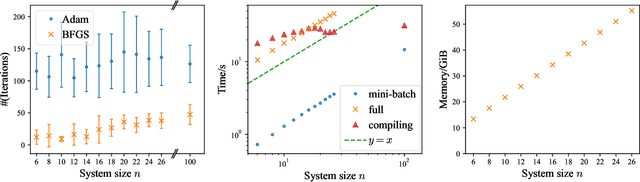
The physics of a closed quantum mechanical system is governed by its Hamiltonian. However, in most practical situations, this Hamiltonian is not precisely known, and ultimately all there is are data obtained from measurements on the system. In this work, we introduce a highly scalable, data-driven approach to learning families of interacting many-body Hamiltonians from dynamical data, by bringing together techniques from gradient-based optimization from machine learning with efficient quantum state representations in terms of tensor networks. Our approach is highly practical, experimentally friendly, and intrinsically scalable to allow for system sizes of above 100 spins. In particular, we demonstrate on synthetic data that the algorithm works even if one is restricted to one simple initial state, a small number of single-qubit observables, and time evolution up to relatively short times. For the concrete example of the one-dimensional Heisenberg model our algorithm exhibits an error constant in the system size and scaling as the inverse square root of the size of the data set.