 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoverage-centric Coreset Selection for High Pruning Rates
Oct 28, 2022



One-shot coreset selection aims to select a subset of the training data, given a pruning rate, that can achieve high accuracy for models that are subsequently trained only with that subset. State-of-the-art coreset selection methods typically assign an importance score to each example and select the most important examples to form a coreset. These methods perform well at low pruning rates; but at high pruning rates, they have been found to suffer a catastrophic accuracy drop, performing worse than even random coreset selection. In this paper, we explore the reasons for this accuracy drop both theoretically and empirically. We extend previous theoretical results on the bound for model loss in terms of coverage provided by the coreset. Inspired by theoretical results, we propose a novel coverage-based metric and, based on the metric, find that coresets selected by importance-based coreset methods at high pruning rates can be expected to perform poorly compared to random coresets because of worse data coverage. We then propose a new coreset selection method, Coverage-centric Coreset Selection (CCS), where we jointly consider overall data coverage based on the proposed metric as well as importance of each example. We evaluate CCS on four datasets and show that they achieve significantly better accuracy than state-of-the-art coreset selection methods as well as random sampling under high pruning rates, and comparable performance at low pruning rates. For example, CCS achieves 7.04% better accuracy than random sampling and at least 20.16% better than popular importance-based selection methods on CIFAR10 with a 90% pruning rate.
Constraining the Attack Space of Machine Learning Models with Distribution Clamping Preprocessing
May 18, 2022
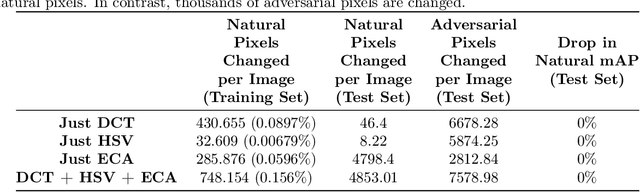
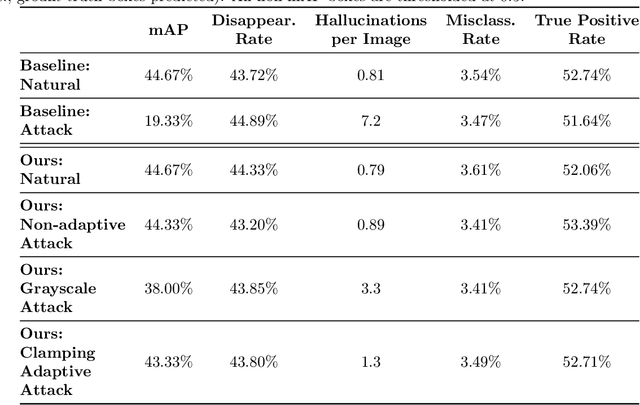
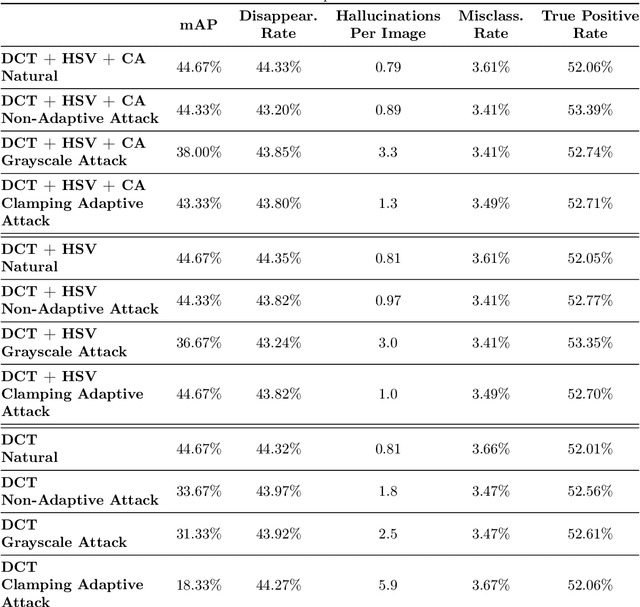
Preprocessing and outlier detection techniques have both been applied to neural networks to increase robustness with varying degrees of success. In this paper, we formalize the ideal preprocessor function as one that would take any input and set it to the nearest in-distribution input. In other words, we detect any anomalous pixels and set them such that the new input is in-distribution. We then illustrate a relaxed solution to this problem in the context of patch attacks. Specifically, we demonstrate that we can model constraints on the patch attack that specify regions as out of distribution. With these constraints, we are able to preprocess inputs successfully, increasing robustness on CARLA object detection.
Concept-based Explanations for Out-Of-Distribution Detectors
Mar 04, 2022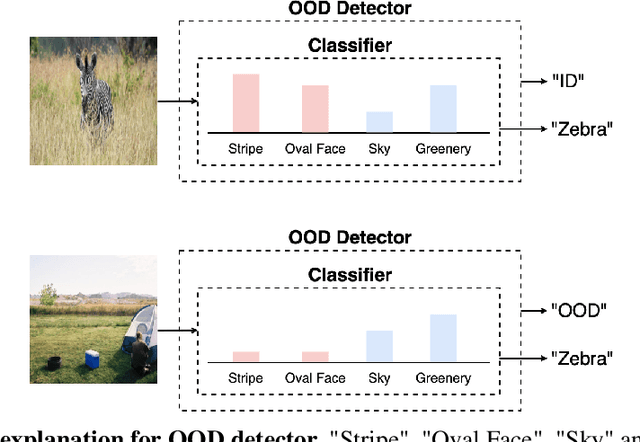
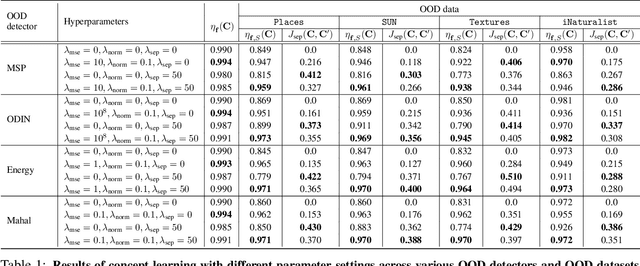
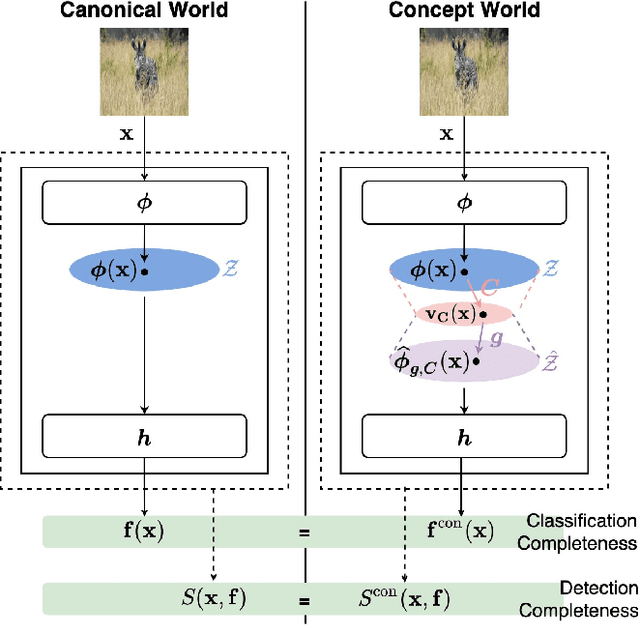
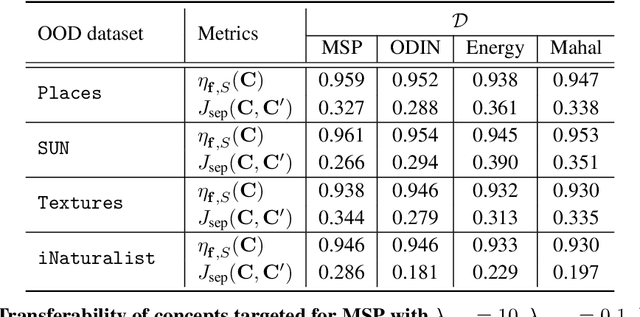
Out-of-distribution (OOD) detection plays a crucial role in ensuring the safe deployment of deep neural network (DNN) classifiers. While a myriad of methods have focused on improving the performance of OOD detectors, a critical gap remains in interpreting their decisions. We help bridge this gap by providing explanations for OOD detectors based on learned high-level concepts. We first propose two new metrics for assessing the effectiveness of a particular set of concepts for explaining OOD detectors: 1) detection completeness, which quantifies the sufficiency of concepts for explaining an OOD-detector's decisions, and 2) concept separability, which captures the distributional separation between in-distribution and OOD data in the concept space. Based on these metrics, we propose a framework for learning a set of concepts that satisfy the desired properties of detection completeness and concept separability and demonstrate the framework's effectiveness in providing concept-based explanations for diverse OOD techniques. We also show how to identify prominent concepts that contribute to the detection results via a modified Shapley value-based importance score.
Towards Adversarially Robust Deepfake Detection: An Ensemble Approach
Feb 11, 2022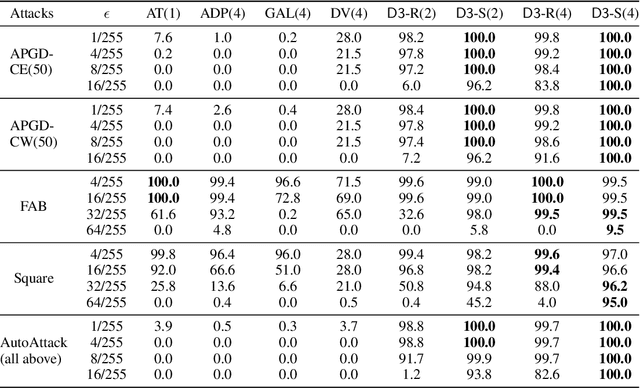
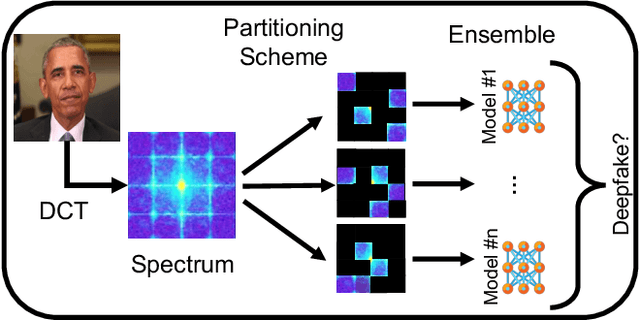
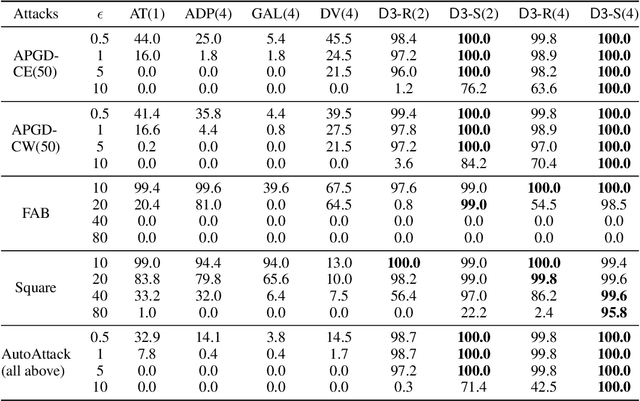
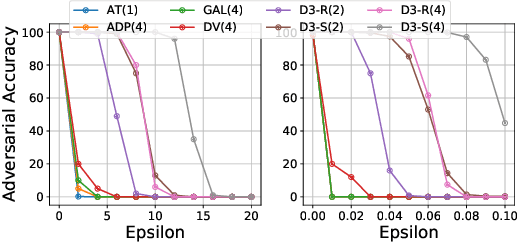
Detecting deepfakes is an important problem, but recent work has shown that DNN-based deepfake detectors are brittle against adversarial deepfakes, in which an adversary adds imperceptible perturbations to a deepfake to evade detection. In this work, we show that a modification to the detection strategy in which we replace a single classifier with a carefully chosen ensemble, in which input transformations for each model in the ensemble induces pairwise orthogonal gradients, can significantly improve robustness beyond the de facto solution of adversarial training. We present theoretical results to show that such orthogonal gradients can help thwart a first-order adversary by reducing the dimensionality of the input subspace in which adversarial deepfakes lie. We validate the results empirically by instantiating and evaluating a randomized version of such "orthogonal" ensembles for adversarial deepfake detection and find that these randomized ensembles exhibit significantly higher robustness as deepfake detectors compared to state-of-the-art deepfake detectors against adversarial deepfakes, even those created using strong PGD-500 attacks.
Using Anomaly Feature Vectors for Detecting, Classifying and Warning of Outlier Adversarial Examples
Jul 01, 2021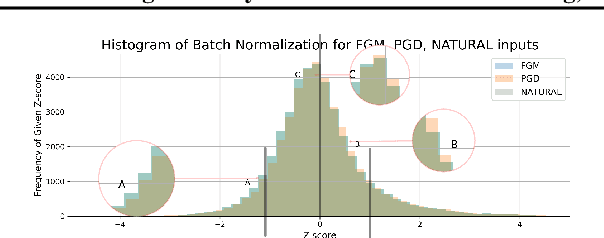
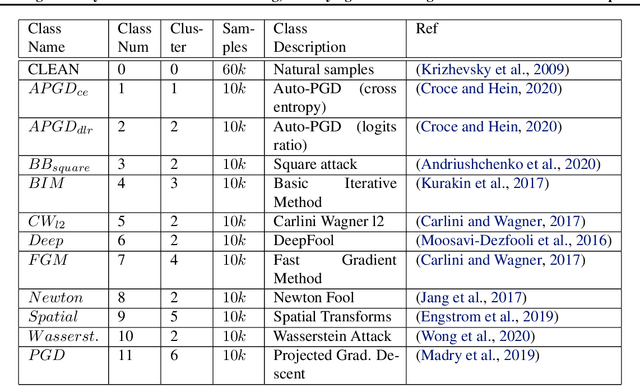
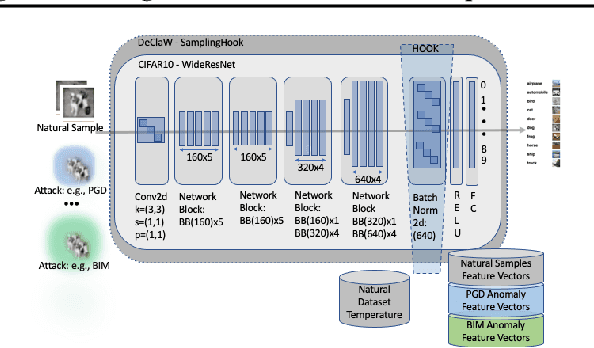
We present DeClaW, a system for detecting, classifying, and warning of adversarial inputs presented to a classification neural network. In contrast to current state-of-the-art methods that, given an input, detect whether an input is clean or adversarial, we aim to also identify the types of adversarial attack (e.g., PGD, Carlini-Wagner or clean). To achieve this, we extract statistical profiles, which we term as anomaly feature vectors, from a set of latent features. Preliminary findings suggest that AFVs can help distinguish among several types of adversarial attacks (e.g., PGD versus Carlini-Wagner) with close to 93% accuracy on the CIFAR-10 dataset. The results open the door to using AFV-based methods for exploring not only adversarial attack detection but also classification of the attack type and then design of attack-specific mitigation strategies.
Essential Features: Reducing the Attack Surface of Adversarial Perturbations with Robust Content-Aware Image Preprocessing
Dec 03, 2020
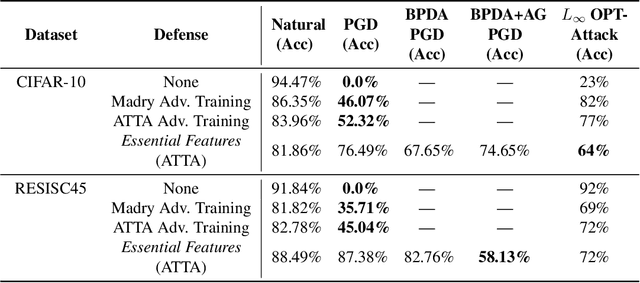
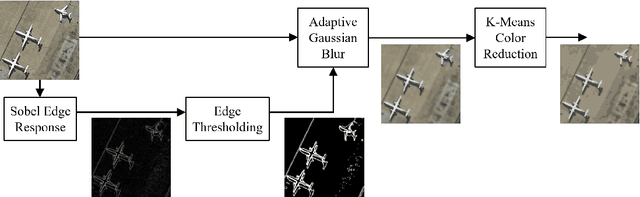
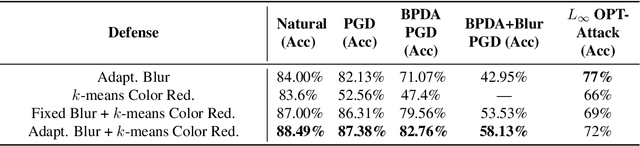
Adversaries are capable of adding perturbations to an image to fool machine learning models into incorrect predictions. One approach to defending against such perturbations is to apply image preprocessing functions to remove the effects of the perturbation. Existing approaches tend to be designed orthogonally to the content of the image and can be beaten by adaptive attacks. We propose a novel image preprocessing technique called Essential Features that transforms the image into a robust feature space that preserves the main content of the image while significantly reducing the effects of the perturbations. Specifically, an adaptive blurring strategy that preserves the main edge features of the original object along with a k-means color reduction approach is employed to simplify the image to its k most representative colors. This approach significantly limits the attack surface for adversaries by limiting the ability to adjust colors while preserving pertinent features of the original image. We additionally design several adaptive attacks and find that our approach remains more robust than previous baselines. On CIFAR-10 we achieve 64% robustness and 58.13% robustness on RESISC45, raising robustness by over 10% versus state-of-the-art adversarial training techniques against adaptive white-box and black-box attacks. The results suggest that strategies that retain essential features in images by adaptive processing of the content hold promise as a complement to adversarial training for boosting robustness against adversarial inputs.
Understanding and Diagnosing Vulnerability under Adversarial Attacks
Jul 17, 2020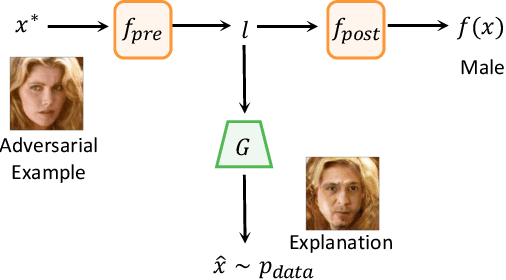
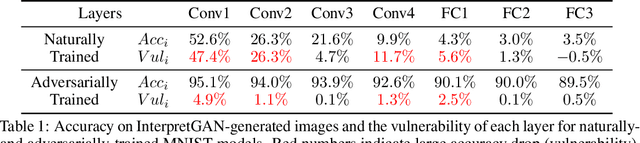
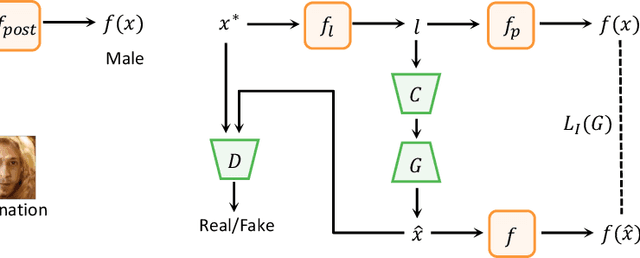
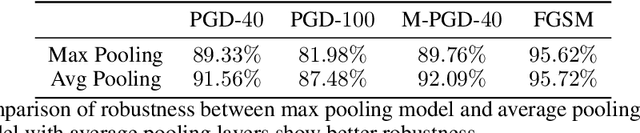
Deep Neural Networks (DNNs) are known to be vulnerable to adversarial attacks. Currently, there is no clear insight into how slight perturbations cause such a large difference in classification results and how we can design a more robust model architecture. In this work, we propose a novel interpretability method, InterpretGAN, to generate explanations for features used for classification in latent variables. Interpreting the classification process of adversarial examples exposes how adversarial perturbations influence features layer by layer as well as which features are modified by perturbations. Moreover, we design the first diagnostic method to quantify the vulnerability contributed by each layer, which can be used to identify vulnerable parts of model architectures. The diagnostic results show that the layers introducing more information loss tend to be more vulnerable than other layers. Based on the findings, our evaluation results on MNIST and CIFAR10 datasets suggest that average pooling layers, with lower information loss, are more robust than max pooling layers for the network architectures studied in this paper.
Towards Robustness against Unsuspicious Adversarial Examples
May 08, 2020

Despite the remarkable success of deep neural networks, significant concerns have emerged about their robustness to adversarial perturbations to inputs. While most attacks aim to ensure that these are imperceptible, physical perturbation attacks typically aim for being unsuspicious, even if perceptible. However, there is no universal notion of what it means for adversarial examples to be unsuspicious. We propose an approach for modeling suspiciousness by leveraging cognitive salience. Specifically, we split an image into foreground (salient region) and background (the rest), and allow significantly larger adversarial perturbations in the background. We describe how to compute the resulting dual-perturbation attacks on both deterministic and stochastic classifiers. We then experimentally demonstrate that our attacks do not significantly change perceptual salience of the background, but are highly effective against classifiers robust to conventional attacks. Furthermore, we show that adversarial training with dual-perturbation attacks yields classifiers that are more robust to these than state-of-the-art robust learning approaches, and comparable in terms of robustness to conventional attacks.
MAZE: Data-Free Model Stealing Attack Using Zeroth-Order Gradient Estimation
May 06, 2020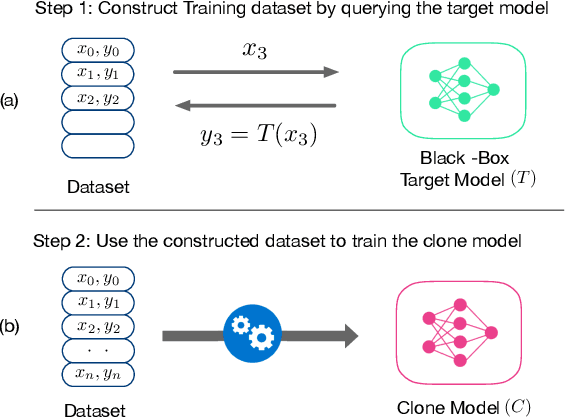
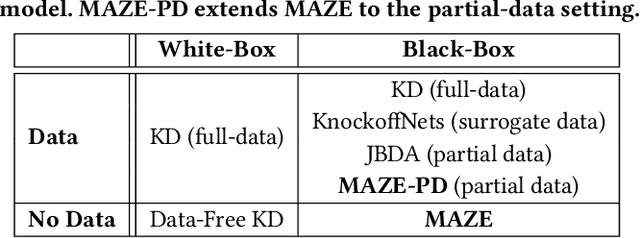
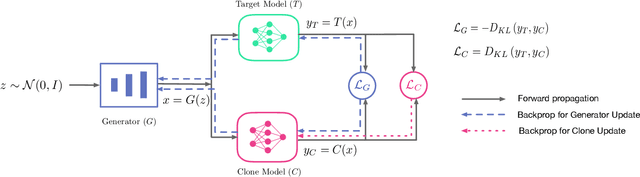
Model Stealing (MS) attacks allow an adversary with black-box access to a Machine Learning model to replicate its functionality, compromising the confidentiality of the model. Such attacks train a clone model by using the predictions of the target model for different inputs. The effectiveness of such attacks relies heavily on the availability of data necessary to query the target model. Existing attacks either assume partial access to the dataset of the target model or availability of an alternate dataset with semantic similarities. This paper proposes MAZE -- a data-free model stealing attack using zeroth-order gradient estimation. In contrast to prior works, MAZE does not require any data and instead creates synthetic data using a generative model. Inspired by recent works in data-free Knowledge Distillation (KD), we train the generative model using a disagreement objective to produce inputs that maximize disagreement between the clone and the target model. However, unlike the white-box setting of KD, where the gradient information is available, training a generator for model stealing requires performing black-box optimization, as it involves accessing the target model under attack. MAZE relies on zeroth-order gradient estimation to perform this optimization and enables a highly accurate MS attack. Our evaluation with four datasets shows that MAZE provides a normalized clone accuracy in the range of 0.91x to 0.99x, and outperforms even the recent attacks that rely on partial data (JBDA, clone accuracy 0.13x to 0.69x) and surrogate data (KnockoffNets, clone accuracy 0.52x to 0.97x). We also study an extension of MAZE in the partial-data setting and develop MAZE-PD, which generates synthetic data closer to the target distribution. MAZE-PD further improves the clone accuracy (0.97x to 1.0x) and reduces the query required for the attack by 2x-24x.
Query-Efficient Physical Hard-Label Attacks on Deep Learning Visual Classification
Feb 17, 2020
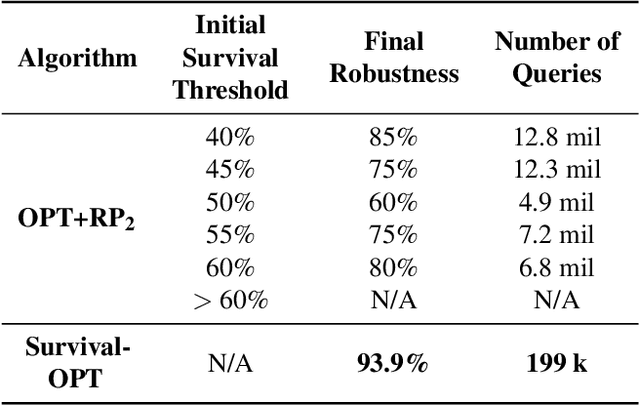

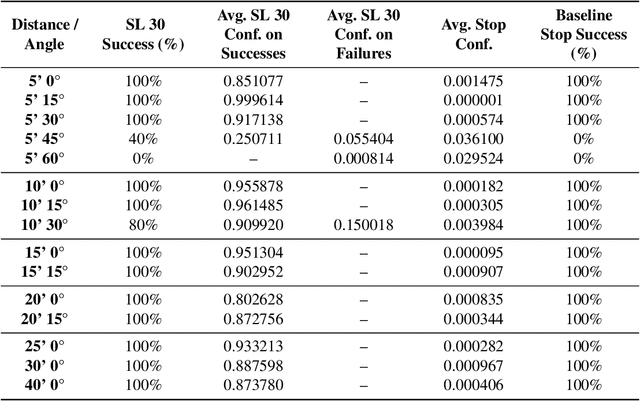
We present Survival-OPT, a physical adversarial example algorithm in the black-box hard-label setting where the attacker only has access to the model prediction class label. Assuming such limited access to the model is more relevant for settings such as proprietary cyber-physical and cloud systems than the whitebox setting assumed by prior work. By leveraging the properties of physical attacks, we create a novel approach based on the survivability of perturbations corresponding to physical transformations. Through simply querying the model for hard-label predictions, we optimize perturbations to survive in many different physical conditions and show that adversarial examples remain a security risk to cyber-physical systems (CPSs) even in the hard-label threat model. We show that Survival-OPT is query-efficient and robust: using fewer than 200K queries, we successfully attack a stop sign to be misclassified as a speed limit 30 km/hr sign in 98.5% of video frames in a drive-by setting. Survival-OPT also outperforms our baseline combination of existing hard-label and physical approaches, which required over 10x more queries for less robust results.