 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePC-MIL: Decoupling Feature Resolution from Supervision Scale in Whole-Slide Learning
Apr 13, 2026Whole-slide image (WSI) classification in computational pathology is commonly formulated as slide-level Multiple Instance Learning (MIL) with a single global bag representation. However, slide-level MIL is fundamentally underconstrained: optimizing only global labels encourages models to aggregate features without learning anatomically meaningful localization. This creates a mismatch between the scale of supervision and the scale of clinical reasoning. Clinicians assess tumor burden, focal lesions, and architectural patterns within millimeter-scale regions, whereas standard MIL is trained only to predict whether "somewhere in the slide there is cancer." As a result, the model's inductive bias effectively erases anatomical structure. We propose Progressive-Context MIL (PC-MIL), a framework that treats the spatial extent of supervision as a first-class design dimension. Rather than altering magnification, patch size, or introducing pixel-level segmentation, we decouple feature resolution from supervision scale. Using fixed 20x features, we vary MIL bag extent in millimeter units and anchor supervision at a clinically motivated 2mm scale to preserve comparable tumor burden and avoid confounding scale with lesion density. PC-MIL progressively mixes slide- and region-level supervision in controlled proportions, enabling explicit train-context x test-context analysis. On 1,476 prostate WSIs from five public datasets for binary cancer detection, we show that anatomical context is an independent axis of generalization in MIL, orthogonal to feature resolution: modest regional supervision improves cross-context performance, and balanced multi-context training stabilizes accuracy across slide and regional evaluation without sacrificing global performance. These results demonstrate that supervision extent shapes MIL inductive bias and support anatomically grounded WSI generalization.
Topological Data Analysis Made Easy with the Topology ToolKit
Jun 21, 2018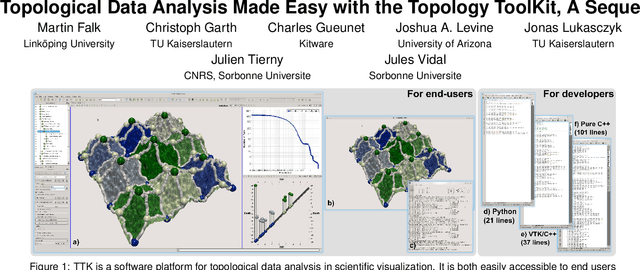
This tutorial presents topological methods for the analysis and visualization of scientific data from a user's perspective, with the Topology ToolKit (TTK), a recently released open-source library for topological data analysis. Topological methods have gained considerably in popularity and maturity over the last twenty years and success stories of established methods have been documented in a wide range of applications (combustion, chemistry, astrophysics, material sciences, etc.) with both acquired and simulated data, in both post-hoc and in-situ contexts. While reference textbooks have been published on the topic, no tutorial at IEEE VIS has covered this area in recent years, and never at a software level and from a user's point-of-view. This tutorial fills this gap by providing a beginner's introduction to topological methods for practitioners, researchers, students, and lecturers. In particular, instead of focusing on theoretical aspects and algorithmic details, this tutorial focuses on how topological methods can be useful in practice for concrete data analysis tasks such as segmentation, feature extraction or tracking. The tutorial describes in detail how to achieve these tasks with TTK. First, after an introduction to topological methods and their application in data analysis, a brief overview of TTK's main entry point for end users, namely ParaView, will be presented. Second, an overview of TTK's main features will be given. A running example will be described in detail, showcasing how to access TTK's features via ParaView, Python, VTK/C++, and C++. Third, hands-on sessions will concretely show how to use TTK in ParaView for multiple, representative data analysis tasks. Fourth, the usage of TTK will be presented for developers, in particular by describing several examples of visualization and data analysis projects that were built on top of TTK. Finally, some feedback regarding the usage of TTK as a teaching platform for topological analysis will be given. Presenters of this tutorial include experts in topological methods, core authors of TTK as well as active users, coming from academia, labs, or industry. A large part of the tutorial will be dedicated to hands-on exercises and a rich material package (including TTK pre-installs in virtual machines, code, data, demos, video tutorials, etc.) will be provided to the participants. This tutorial mostly targets students, practitioners and researchers who are not experts in topological methods but who are interested in using them in their daily tasks. We also target researchers already familiar to topological methods and who are interested in using or contributing to TTK.