 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEA-NLI: Natural Language Inference as a Lens into Southeast Asian Cultural Understanding
Jun 02, 2026Frontier LLMs perform well in Western contexts, but remain poorly tested on underrepresented cultures such as those in Southeast Asia (SEA). Existing NLI benchmarks are largely Western-centric, translation-derived, or monolingual, limiting their ability to measure culturally grounded reasoning. We introduce SEA-NLI, a native, culturally grounded NLI benchmark covering eight SEA countries in English and native regional languages, verified by native speakers. Across 17 encoder and decoder models, we observe a low performance from all models, especially for knowledge-intensive categories such as Languages and Science and Technology. Our analysis shows that failure cases mainly stem from missing SEA cultural knowledge: SEA-adapted models and culture-aware prompting improve performance, while CoT prompting offers limited gains.
Aspect-Level Obfuscated Sentiment in Thai Financial Disclosures and Its Impact on Abnormal Returns
Nov 17, 2025Understanding sentiment in financial documents is crucial for gaining insights into market behavior. These reports often contain obfuscated language designed to present a positive or neutral outlook, even when underlying conditions may be less favorable. This paper presents a novel approach using Aspect-Based Sentiment Analysis (ABSA) to decode obfuscated sentiment in Thai financial annual reports. We develop specific guidelines for annotating obfuscated sentiment in these texts and annotate more than one hundred financial reports. We then benchmark various text classification models on this annotated dataset, demonstrating strong performance in sentiment classification. Additionally, we conduct an event study to evaluate the real-world implications of our sentiment analysis on stock prices. Our results suggest that market reactions are selectively influenced by specific aspects within the reports. Our findings underscore the complexity of sentiment analysis in financial texts and highlight the importance of addressing obfuscated language to accurately assess market sentiment.
OpenJAI-v1.0: An Open Thai Large Language Model
Oct 08, 2025We introduce OpenJAI-v1.0, an open-source large language model for Thai and English, developed from the Qwen3-14B model. Our work focuses on boosting performance on practical tasks through carefully curated data across three key use cases: instruction following, long-context understanding, and tool use. Evaluation results show that OpenJAI-v1.0 improves on the capabilities of its base model and outperforms other leading open-source Thai models on a diverse suite of benchmarks, while avoiding catastrophic forgetting. OpenJAI-v1.0 is publicly released as another alternative NLP resource for the Thai AI community.
ThaiCoref: Thai Coreference Resolution Dataset
Jun 10, 2024



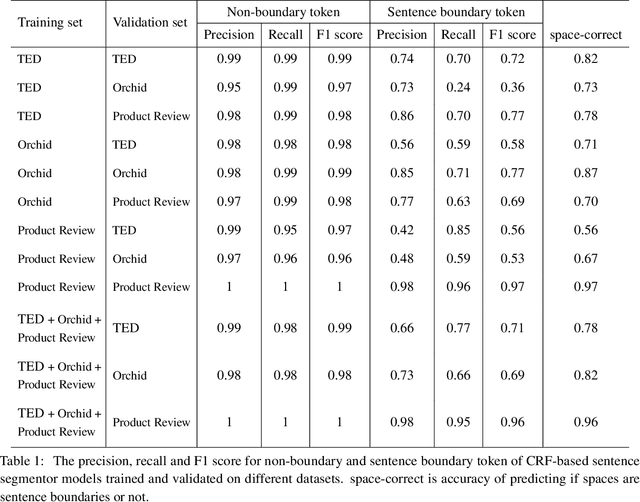
While coreference resolution is a well-established research area in Natural Language Processing (NLP), research focusing on Thai language remains limited due to the lack of large annotated corpora. In this work, we introduce ThaiCoref, a dataset for Thai coreference resolution. Our dataset comprises 777,271 tokens, 44,082 mentions and 10,429 entities across four text genres: university essays, newspapers, speeches, and Wikipedia. Our annotation scheme is built upon the OntoNotes benchmark with adjustments to address Thai-specific phenomena. Utilizing ThaiCoref, we train models employing a multilingual encoder and cross-lingual transfer techniques, achieving a best F1 score of 67.88\% on the test set. Error analysis reveals challenges posed by Thai's unique linguistic features. To benefit the NLP community, we make the dataset and the model publicly available at http://www.github.com/nlp-chula/thai-coref .
Thai Universal Dependency Treebank
May 13, 2024Automatic dependency parsing of Thai sentences has been underexplored, as evidenced by the lack of large Thai dependency treebanks with complete dependency structures and the lack of a published systematic evaluation of state-of-the-art models, especially transformer-based parsers. In this work, we address these problems by introducing Thai Universal Dependency Treebank (TUD), a new largest Thai treebank consisting of 3,627 trees annotated in accordance with the Universal Dependencies (UD) framework. We then benchmark dependency parsing models that incorporate pretrained transformers as encoders and train them on Thai-PUD and our TUD. The evaluation results show that most of our models can outperform other models reported in previous papers and provide insight into the optimal choices of components to include in Thai dependency parsers. The new treebank and every model's full prediction generated in our experiment are made available on a GitHub repository for further study.
PhayaThaiBERT: Enhancing a Pretrained Thai Language Model with Unassimilated Loanwords
Nov 21, 2023While WangchanBERTa has become the de facto standard in transformer-based Thai language modeling, it still has shortcomings in regard to the understanding of foreign words, most notably English words, which are often borrowed without orthographic assimilation into Thai in many contexts. We identify the lack of foreign vocabulary in WangchanBERTa's tokenizer as the main source of these shortcomings. We then expand WangchanBERTa's vocabulary via vocabulary transfer from XLM-R's pretrained tokenizer and pretrain a new model using the expanded tokenizer, starting from WangchanBERTa's checkpoint, on a new dataset that is larger than the one used to train WangchanBERTa. Our results show that our new pretrained model, PhayaThaiBERT, outperforms WangchanBERTa in many downstream tasks and datasets.
More Than Words: Collocation Tokenization for Latent Dirichlet Allocation Models
Aug 24, 2021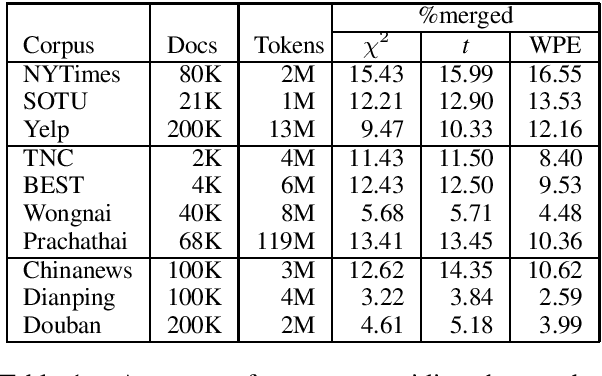


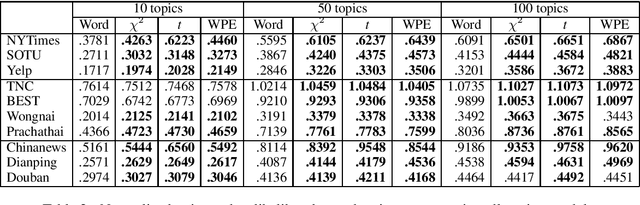
Traditionally, Latent Dirichlet Allocation (LDA) ingests words in a collection of documents to discover their latent topics using word-document co-occurrences. However, it is unclear how to achieve the best results for languages without marked word boundaries such as Chinese and Thai. Here, we explore the use of Pearson's chi-squared test, t-statistics, and Word Pair Encoding (WPE) to produce tokens as input to the LDA model. The Chi-squared, t, and WPE tokenizers are trained on Wikipedia text to look for words that should be grouped together, such as compound nouns, proper nouns, and complex event verbs. We propose a new metric for measuring the clustering quality in settings where the vocabularies of the models differ. Based on this metric and other established metrics, we show that topics trained with merged tokens result in topic keys that are clearer, more coherent, and more effective at distinguishing topics than those unmerged models.
scb-mt-en-th-2020: A Large English-Thai Parallel Corpus
Jul 07, 2020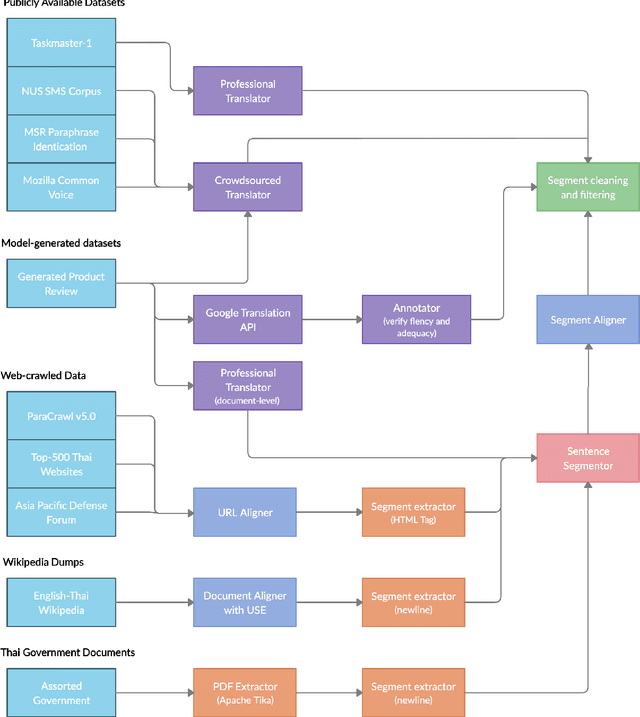
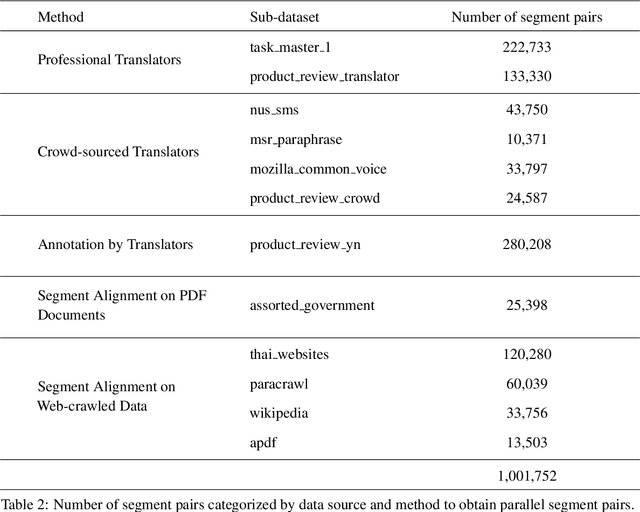
The primary objective of our work is to build a large-scale English-Thai dataset for machine translation. We construct an English-Thai machine translation dataset with over 1 million segment pairs, curated from various sources, namely news, Wikipedia articles, SMS messages, task-based dialogs, web-crawled data and government documents. Methodology for gathering data, building parallel texts and removing noisy sentence pairs are presented in a reproducible manner. We train machine translation models based on this dataset. Our models' performance are comparable to that of Google Translation API (as of May 2020) for Thai-English and outperform Google when the Open Parallel Corpus (OPUS) is included in the training data for both Thai-English and English-Thai translation. The dataset, pre-trained models, and source code to reproduce our work are available for public use.
Neural Network Models for Implicit Discourse Relation Classification in English and Chinese without Surface Features
Jun 07, 2016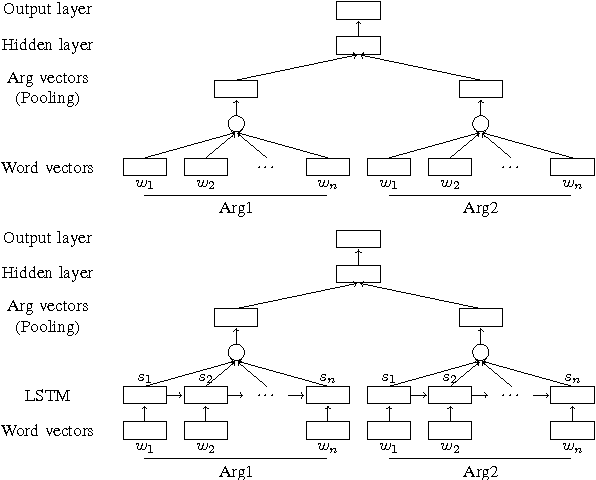
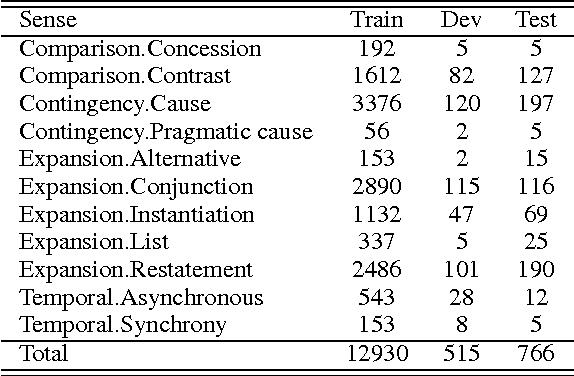

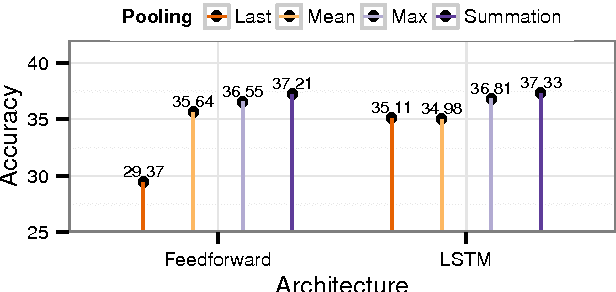
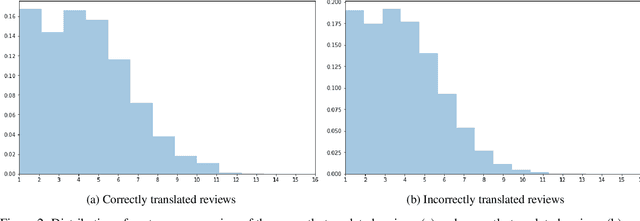
Inferring implicit discourse relations in natural language text is the most difficult subtask in discourse parsing. Surface features achieve good performance, but they are not readily applicable to other languages without semantic lexicons. Previous neural models require parses, surface features, or a small label set to work well. Here, we propose neural network models that are based on feedforward and long-short term memory architecture without any surface features. To our surprise, our best configured feedforward architecture outperforms LSTM-based model in most cases despite thorough tuning. Under various fine-grained label sets and a cross-linguistic setting, our feedforward models perform consistently better or at least just as well as systems that require hand-crafted surface features. Our models present the first neural Chinese discourse parser in the style of Chinese Discourse Treebank, showing that our results hold cross-linguistically.