 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSub-8-bit quantization for on-device speech recognition: a regularization-free approach
Oct 17, 2022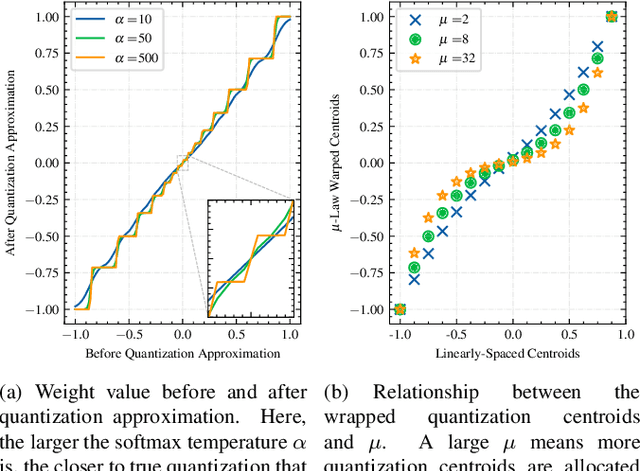

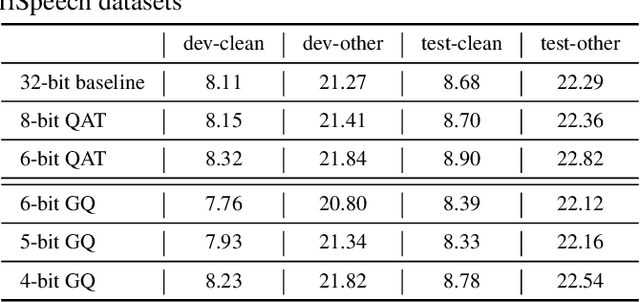
For on-device automatic speech recognition (ASR), quantization aware training (QAT) is ubiquitous to achieve the trade-off between model predictive performance and efficiency. Among existing QAT methods, one major drawback is that the quantization centroids have to be predetermined and fixed. To overcome this limitation, we introduce a regularization-free, "soft-to-hard" compression mechanism with self-adjustable centroids in a mu-Law constrained space, resulting in a simpler yet more versatile quantization scheme, called General Quantizer (GQ). We apply GQ to ASR tasks using Recurrent Neural Network Transducer (RNN-T) and Conformer architectures on both LibriSpeech and de-identified far-field datasets. Without accuracy degradation, GQ can compress both RNN-T and Conformer into sub-8-bit, and for some RNN-T layers, to 1-bit for fast and accurate inference. We observe a 30.73% memory footprint saving and 31.75% user-perceived latency reduction compared to 8-bit QAT via physical device benchmarking.
ConvRNN-T: Convolutional Augmented Recurrent Neural Network Transducers for Streaming Speech Recognition
Sep 29, 2022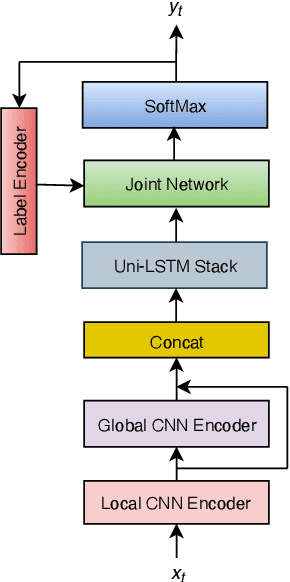
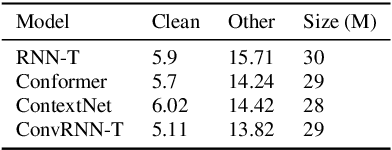
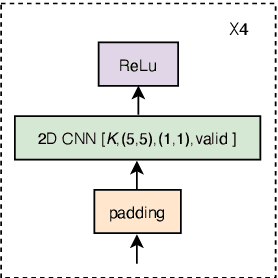

The recurrent neural network transducer (RNN-T) is a prominent streaming end-to-end (E2E) ASR technology. In RNN-T, the acoustic encoder commonly consists of stacks of LSTMs. Very recently, as an alternative to LSTM layers, the Conformer architecture was introduced where the encoder of RNN-T is replaced with a modified Transformer encoder composed of convolutional layers at the frontend and between attention layers. In this paper, we introduce a new streaming ASR model, Convolutional Augmented Recurrent Neural Network Transducers (ConvRNN-T) in which we augment the LSTM-based RNN-T with a novel convolutional frontend consisting of local and global context CNN encoders. ConvRNN-T takes advantage of causal 1-D convolutional layers, squeeze-and-excitation, dilation, and residual blocks to provide both global and local audio context representation to LSTM layers. We show ConvRNN-T outperforms RNN-T, Conformer, and ContextNet on Librispeech and in-house data. In addition, ConvRNN-T offers less computational complexity compared to Conformer. ConvRNN-T's superior accuracy along with its low footprint make it a promising candidate for on-device streaming ASR technologies.
Compute Cost Amortized Transformer for Streaming ASR
Jul 05, 2022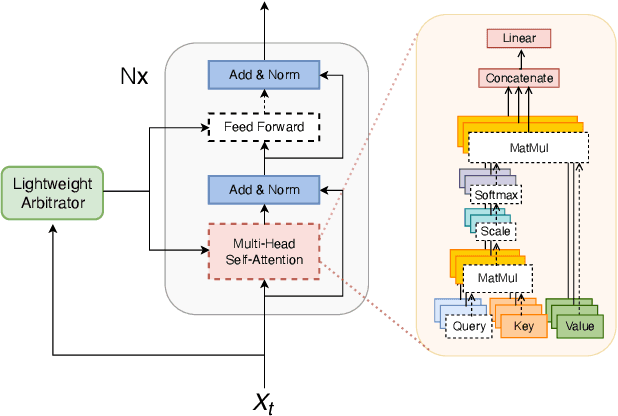
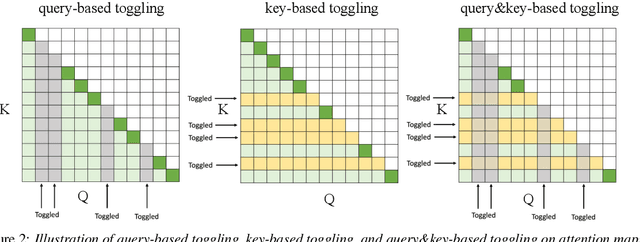
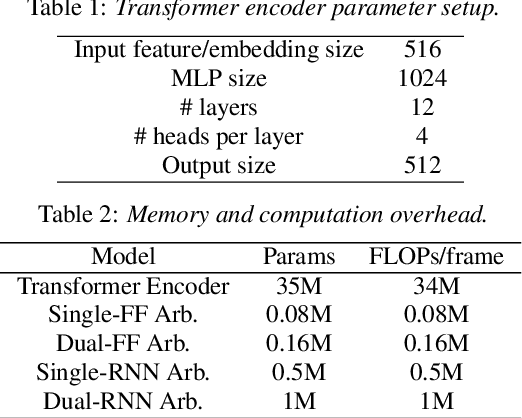
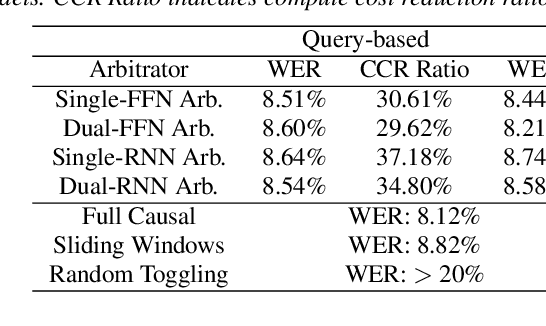
We present a streaming, Transformer-based end-to-end automatic speech recognition (ASR) architecture which achieves efficient neural inference through compute cost amortization. Our architecture creates sparse computation pathways dynamically at inference time, resulting in selective use of compute resources throughout decoding, enabling significant reductions in compute with minimal impact on accuracy. The fully differentiable architecture is trained end-to-end with an accompanying lightweight arbitrator mechanism operating at the frame-level to make dynamic decisions on each input while a tunable loss function is used to regularize the overall level of compute against predictive performance. We report empirical results from experiments using the compute amortized Transformer-Transducer (T-T) model conducted on LibriSpeech data. Our best model can achieve a 60% compute cost reduction with only a 3% relative word error rate (WER) increase.
Sub-8-Bit Quantization Aware Training for 8-Bit Neural Network Accelerator with On-Device Speech Recognition
Jun 30, 2022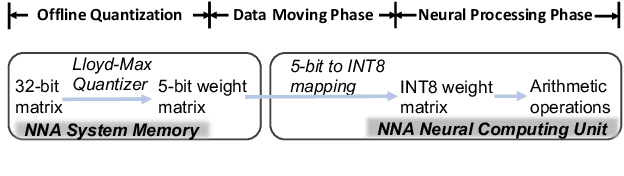
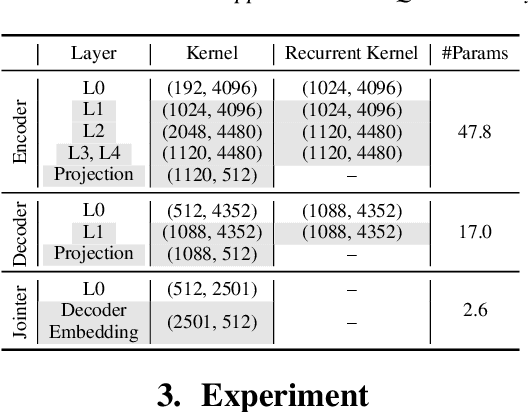
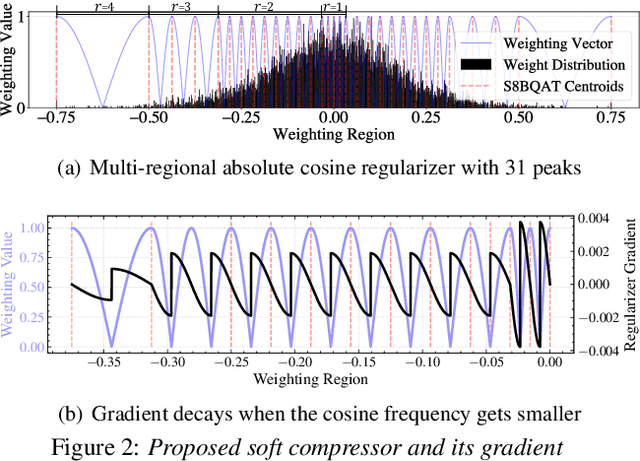
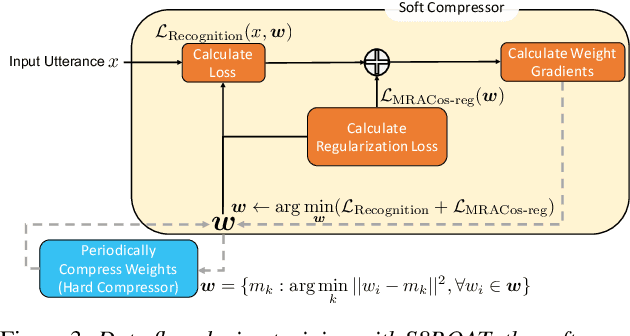
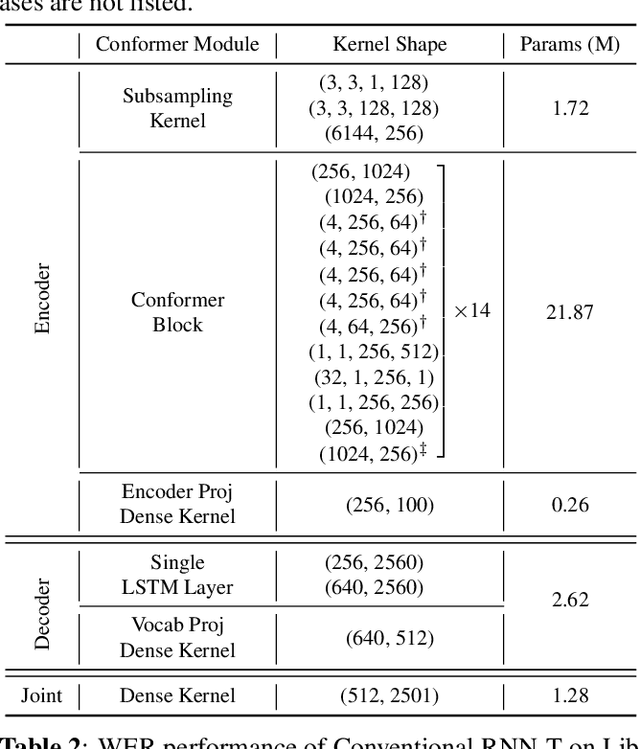
We present a novel sub-8-bit quantization-aware training (S8BQAT) scheme for 8-bit neural network accelerators. Our method is inspired from Lloyd-Max compression theory with practical adaptations for a feasible computational overhead during training. With the quantization centroids derived from a 32-bit baseline, we augment training loss with a Multi-Regional Absolute Cosine (MRACos) regularizer that aggregates weights towards their nearest centroid, effectively acting as a pseudo compressor. Additionally, a periodically invoked hard compressor is introduced to improve the convergence rate by emulating runtime model weight quantization. We apply S8BQAT on speech recognition tasks using Recurrent Neural NetworkTransducer (RNN-T) architecture. With S8BQAT, we are able to increase the model parameter size to reduce the word error rate by 4-16% relatively, while still improving latency by 5%.
Contextual Adapters for Personalized Speech Recognition in Neural Transducers
May 26, 2022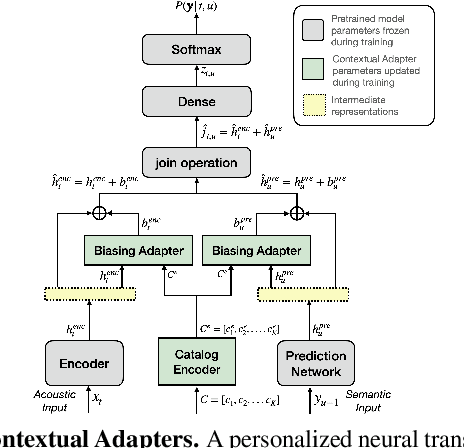
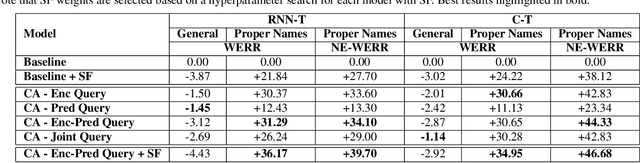
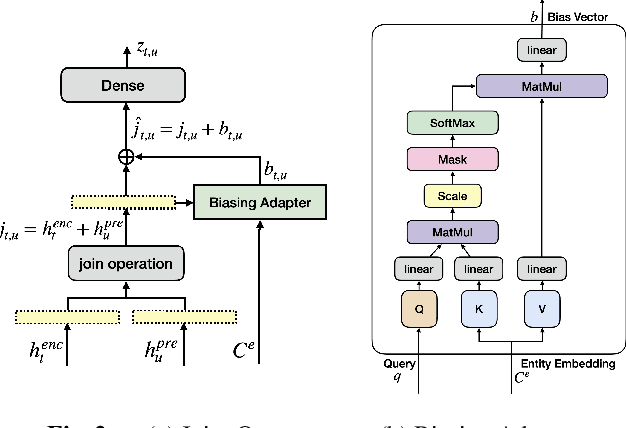
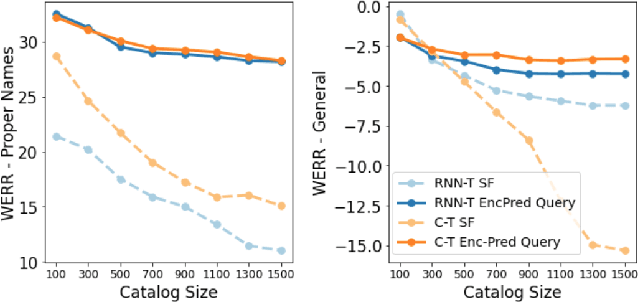
Personal rare word recognition in end-to-end Automatic Speech Recognition (E2E ASR) models is a challenge due to the lack of training data. A standard way to address this issue is with shallow fusion methods at inference time. However, due to their dependence on external language models and the deterministic approach to weight boosting, their performance is limited. In this paper, we propose training neural contextual adapters for personalization in neural transducer based ASR models. Our approach can not only bias towards user-defined words, but also has the flexibility to work with pretrained ASR models. Using an in-house dataset, we demonstrate that contextual adapters can be applied to any general purpose pretrained ASR model to improve personalization. Our method outperforms shallow fusion, while retaining functionality of the pretrained models by not altering any of the model weights. We further show that the adapter style training is superior to full-fine-tuning of the ASR models on datasets with user-defined content.
A neural prosody encoder for end-ro-end dialogue act classification
May 11, 2022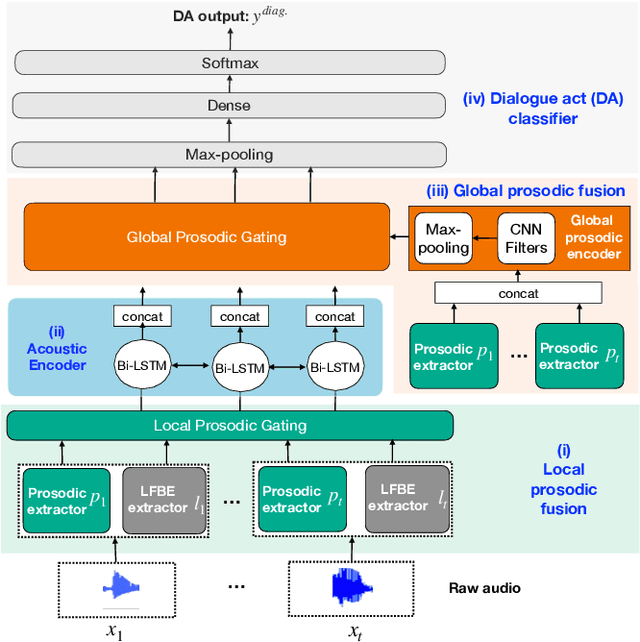
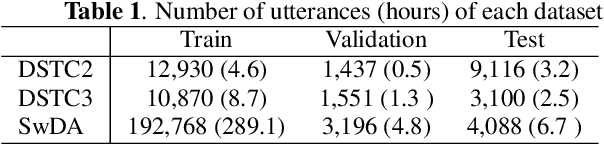
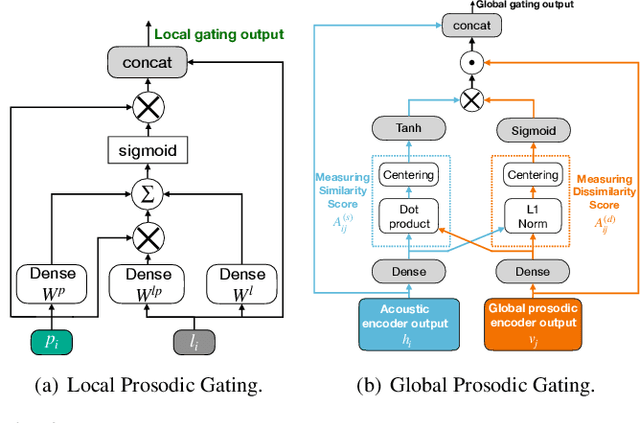

Dialogue act classification (DAC) is a critical task for spoken language understanding in dialogue systems. Prosodic features such as energy and pitch have been shown to be useful for DAC. Despite their importance, little research has explored neural approaches to integrate prosodic features into end-to-end (E2E) DAC models which infer dialogue acts directly from audio signals. In this work, we propose an E2E neural architecture that takes into account the need for characterizing prosodic phenomena co-occurring at different levels inside an utterance. A novel part of this architecture is a learnable gating mechanism that assesses the importance of prosodic features and selectively retains core information necessary for E2E DAC. Our proposed model improves DAC accuracy by 1.07% absolute across three publicly available benchmark datasets.
Context-Aware Transformer Transducer for Speech Recognition
Nov 05, 2021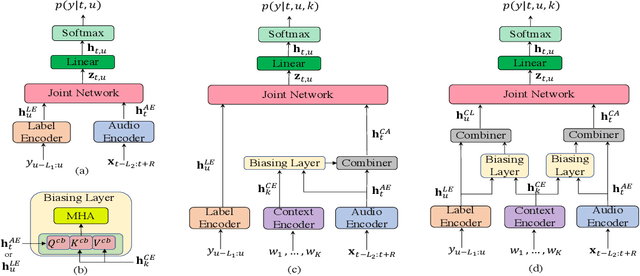
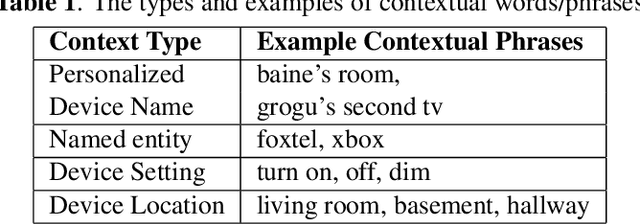

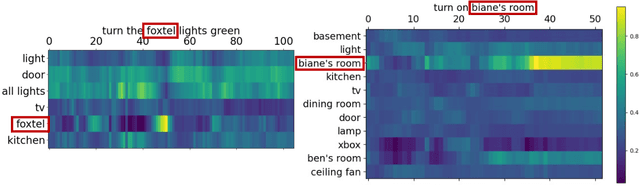
End-to-end (E2E) automatic speech recognition (ASR) systems often have difficulty recognizing uncommon words, that appear infrequently in the training data. One promising method, to improve the recognition accuracy on such rare words, is to latch onto personalized/contextual information at inference. In this work, we present a novel context-aware transformer transducer (CATT) network that improves the state-of-the-art transformer-based ASR system by taking advantage of such contextual signals. Specifically, we propose a multi-head attention-based context-biasing network, which is jointly trained with the rest of the ASR sub-networks. We explore different techniques to encode contextual data and to create the final attention context vectors. We also leverage both BLSTM and pretrained BERT based models to encode contextual data and guide the network training. Using an in-house far-field dataset, we show that CATT, using a BERT based context encoder, improves the word error rate of the baseline transformer transducer and outperforms an existing deep contextual model by 24.2% and 19.4% respectively.
FANS: Fusing ASR and NLU for on-device SLU
Oct 31, 2021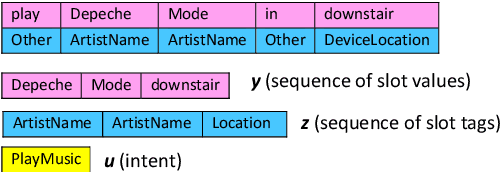
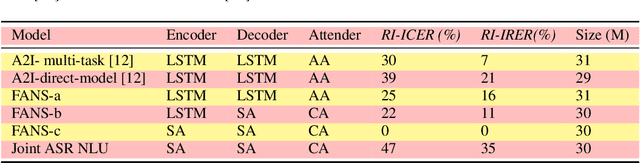
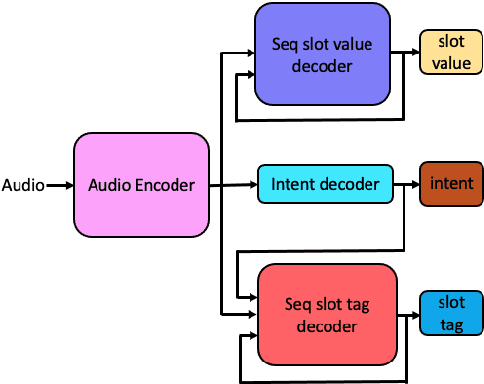
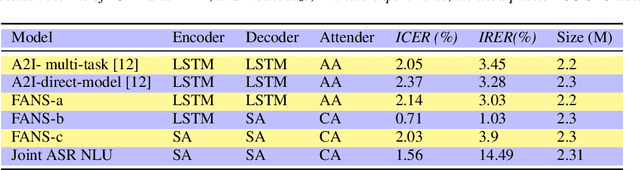
Spoken language understanding (SLU) systems translate voice input commands to semantics which are encoded as an intent and pairs of slot tags and values. Most current SLU systems deploy a cascade of two neural models where the first one maps the input audio to a transcript (ASR) and the second predicts the intent and slots from the transcript (NLU). In this paper, we introduce FANS, a new end-to-end SLU model that fuses an ASR audio encoder to a multi-task NLU decoder to infer the intent, slot tags, and slot values directly from a given input audio, obviating the need for transcription. FANS consists of a shared audio encoder and three decoders, two of which are seq-to-seq decoders that predict non null slot tags and slot values in parallel and in an auto-regressive manner. FANS neural encoder and decoders architectures are flexible which allows us to leverage different combinations of LSTM, self-attention, and attenders. Our experiments show compared to the state-of-the-art end-to-end SLU models, FANS reduces ICER and IRER errors relatively by 30 % and 7 %, respectively, when tested on an in-house SLU dataset and by 0.86 % and 2 % absolute when tested on a public SLU dataset.
Multi-Channel Transformer Transducer for Speech Recognition
Aug 30, 2021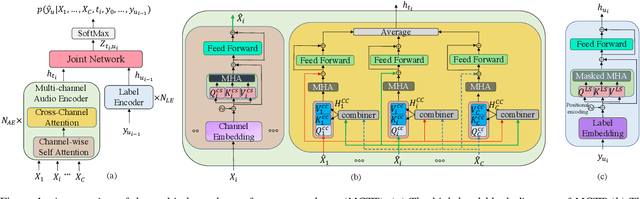
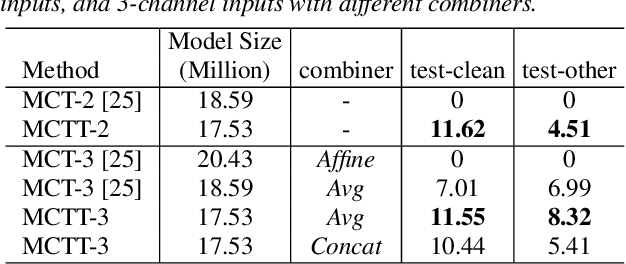
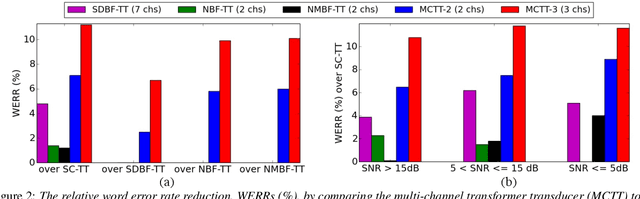
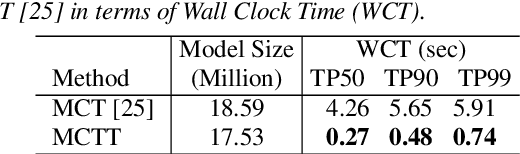
Multi-channel inputs offer several advantages over single-channel, to improve the robustness of on-device speech recognition systems. Recent work on multi-channel transformer, has proposed a way to incorporate such inputs into end-to-end ASR for improved accuracy. However, this approach is characterized by a high computational complexity, which prevents it from being deployed in on-device systems. In this paper, we present a novel speech recognition model, Multi-Channel Transformer Transducer (MCTT), which features end-to-end multi-channel training, low computation cost, and low latency so that it is suitable for streaming decoding in on-device speech recognition. In a far-field in-house dataset, our MCTT outperforms stagewise multi-channel models with transformer-transducer up to 6.01% relative WER improvement (WERR). In addition, MCTT outperforms the multi-channel transformer up to 11.62% WERR, and is 15.8 times faster in terms of inference speed. We further show that we can improve the computational cost of MCTT by constraining the future and previous context in attention computations.
End-to-End Spoken Language Understanding for Generalized Voice Assistants
Jun 16, 2021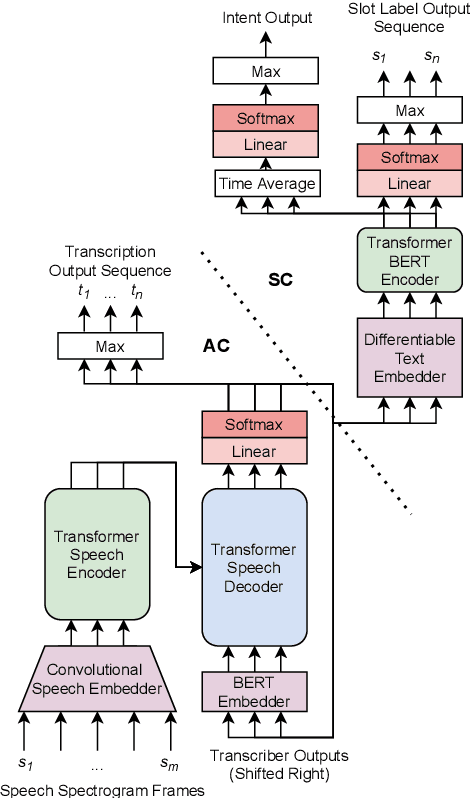
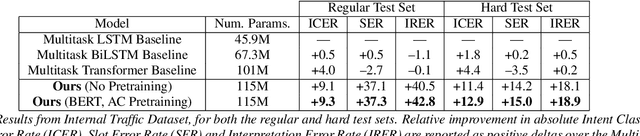
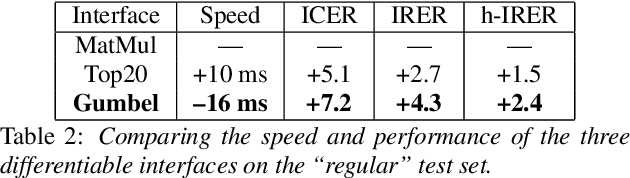
End-to-end (E2E) spoken language understanding (SLU) systems predict utterance semantics directly from speech using a single model. Previous work in this area has focused on targeted tasks in fixed domains, where the output semantic structure is assumed a priori and the input speech is of limited complexity. In this work we present our approach to developing an E2E model for generalized SLU in commercial voice assistants (VAs). We propose a fully differentiable, transformer-based, hierarchical system that can be pretrained at both the ASR and NLU levels. This is then fine-tuned on both transcription and semantic classification losses to handle a diverse set of intent and argument combinations. This leads to an SLU system that achieves significant improvements over baselines on a complex internal generalized VA dataset with a 43% improvement in accuracy, while still meeting the 99% accuracy benchmark on the popular Fluent Speech Commands dataset. We further evaluate our model on a hard test set, exclusively containing slot arguments unseen in training, and demonstrate a nearly 20% improvement, showing the efficacy of our approach in truly demanding VA scenarios.